4小时学会雅达利游戏,AI需要几台电脑?
原作 Felipe Petroski Such, Kenneth O. Stanley and Jeff Clune
Root 编译自 Uber Engineering blog
量子位 出品 | 公众号 QbitAI
一台足矣。
昨天,优步AI Lab开源了深度神经进化的加速代码。其博客上称,哪怕用户只有一台电脑(台式机),用这个代码也能训练出会打雅达利的AI。而且只需要4!小!时!
要知道,此前用深度神经进化方法,让AI一小时学会玩雅达利,需要720个CPU。
720个CPU啊……谁来算算要多少钱……

别费劲算了。反正就是贵到爆炸。想训练出自己的AI?不是壕根本不要想。
优步还是决心伸出援手,拉贫苦大众一把。他们研发出这个深度神经进化加速代码,是希望降低AI研究的资金门槛。至少让那些穷得只能买得起游戏配置的学生们,想自己动手玩玩AI时还有机会。

只用一台电脑,4小时?怎么做到的?
弱弱地先补充个小前提:这台式电脑的配置得高端一点。

△ 也不用这么“高端”
事实上,高端的台式电脑是有几十个虚拟核的,这相当于中型计算集群了。
如果能恰当的平行运行评估环节的话,那原本需要720核CPU跑1小时的任务现在48核的个人电脑只要16小时。
但别忘了高端的电脑还有GPU可以用,毕竟GPU跑深度神经网络更快。
整体思路:CPU和GPU同时用起来
优步这次开源的代码可以同时最大化“榨”干CPU和GPU。让GPU跑深度神经网络,让CPU跑电子游戏或物理模拟器,然后平行批量运行多个评估程序。另外,它也包含调整过的TensorFlow运算,这对于训练速度的提高相当重要。
先改进GPU
在优步的setup里,运行单个神经网络,用CPU比GPU要快。
但GPU更擅长平行运行多个神经网络。
所以,为了充分发挥GPU的优势,优步把多个神经网络整合到了一起,放在同一批里运行。这种做法,在神经网络研究里还是挺常见的,通常用于同样的神经网络处理不同的输入的情况。
不过,神经网络的进化是不一样的。它需要用到不同类的神经网络。这对记忆的容量要求就变高了。
一开始,优步AI研究团队用基础的TensorFlow运算跑了一次,只用8小时就搞定。但他们觉得还有空间优化。
于是,他们进一步调整TensorFlow,增加了两类自定义的运算,于是速度又提升了一倍,训练用时再降到4小时。
其中,第一个自定义TensorFlow运算显著加速了GPU。它专门针对强化学习中的异构神经网络强化学习运算,比如雅达利游戏和大多数机器人运动模拟任务,在这些任务中,各个神经网络的训练周期长度都不同。有了这个自定义运算,GPU可以只调用必需的神经网络进行运算,而不必每一次任务都跑完所有的网络,这样能够大大节省计算量。
再针对CPU
上述提到的所有改进,侧重点都在GPU上。不过,GPU快到一定程度,也会受制于CPU的速度。为了提高CPU运行游戏模拟器的表现,就需要第二个自定义的TensorFlow运算。
具体来说,就是把雅达利模拟器的wrapper从Python改成自定义TensorFlow指令(reset,step,observation)。
这样不仅能利用TensorFlow多线程的快速处理能力,还避免了因为Python和TensorFlow相互作用而造成的减速。
总体上,这些调整极大地提升了雅达利模拟器的运行速度。确切来说,大概是原来的3倍。
对于任何一个域(比如雅达利模拟器、物理模拟器等)里包含多个实例的强化学习研究,上面提到的这些创新方法都能帮它们加速。这类研究越来越常见,比如深度Q学习DQN,或策略梯度A3C的强化学习都是这样。
分开优化后,整体再协调
单拎GPU或CPU来看,速度上已经提升到极致了。但下一个要面临的挑战是如何让所有的计算资源都同时开动起来。
比方说,我们在每个神经网络上都加个前馈传递,问它当下状态应该采取什么行动,那么当每个神经网络计算答案的时候,运行游戏模拟器的CPU只能空转。
同样,如果我们问域模拟器——现在这些行为会产生什么状态,那么CPU在模拟出结果的时候,GPU就没事干了。
下图就是CPU+GPU多线程的示意图。
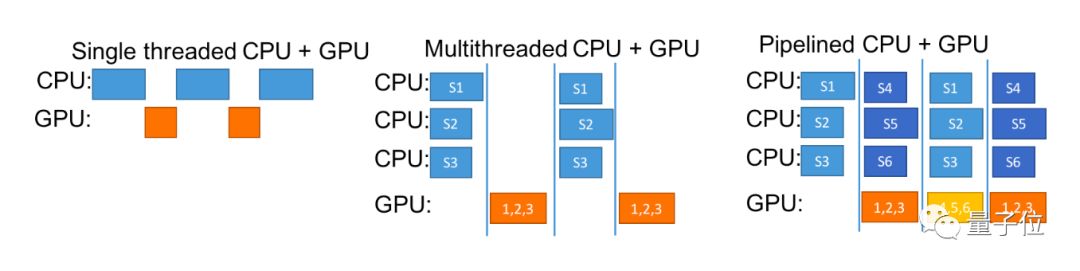
从这张图可以了解到,如何逐步优化强化学习里处理不同类型神经网络的运行效果。
蓝框指的是域模拟器,在这篇文章里是雅达利游戏仿真器,或者是MuJoCo物理模拟器。这两个模拟器都有不同时间长度的场景。
最左侧,是最原始的处理方法,效果最差。既没有充分利用到平行计算的能力,也没浪费了GPU或CPU等待对方处理数据的时间。
中间是多线程方法稍微好一点,一个CPU可以同时处理多个模拟任务,等到GPU运行时,也可以接上CPU处理好的多组数据。不过还是存在互相等造成的时间浪费。
优步的方法是CPU+GPU流水线法。其中,CPU不带停的。在GPU处理CPU数据的时候,CPU并没有闲下来,继续马不停蹄地处理更多的数据。
4百万参数的神经网络,用优步个方法,4个小时就能搞定。
流水线法的意义
又快又便宜。
这直接降低了研究门槛,使得更多自学AI的人,尤其是学生群体,也可以训练出自己想要的深度神经网络了。
效率大大提升的代码将会促进研究更高速的发展。
优步自己就受益匪浅。
他们针对遗传算法发布的大型超参数搜索,所花预算是只是原来的一部分。而且在大部分的雅达利游戏里的表现都获得了提升。具体数字请看优步更新的论文。(https://arxiv.org/abs/1712.06567)
另外,这代码还能缩短神经进化迭代的周期,AI研究人员可以更快地尝试新的想法,也愿意去试原先很大耗时很久的网络了。
优步AI lab研发的软件库包含深度遗传算法的实施,源自Saliman等工作的进化策略算法,还有优步自家据说超级好用随机搜索控制。
深度神经进化领域里,近期还有很多里程碑意义的工作。感兴趣的可以进一步了解以下机构的工作:
OpenAI:https://blog.openai.com/evolution-strategies/
DeepMind:https://deepmind.com/blog/population-based-training-neural-networks/
Google Brain:https://research.googleblog.com/2018/03/using-evolutionary-automl-to-discover.html
Sentient:https://www.sentient.ai/blog/evolution-is-the-new-deep-learning/
最后,附神经网络加速代码:
https://github.com/uber-common/deep-neuroevolution/tree/master/gpu_implementation




