无监督复述
·

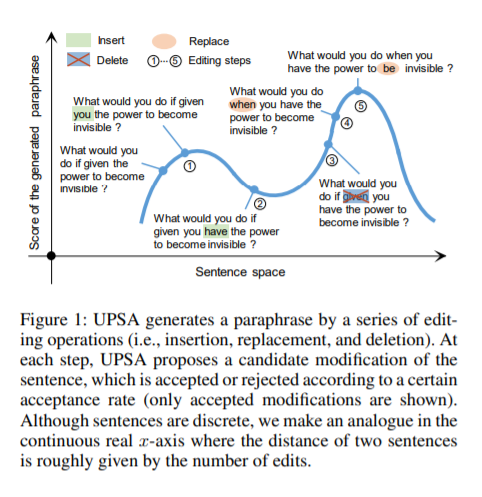
无监督复述是自然语言处理中的重要研究课题。我们提出了一种利用模拟退火实现无监督复述的新方法,我们将复述建模为一个离散优化问题,并提出了一个精心设计的目标函数,包括语义相似性、表达多样性和释义的语言流畅性等衡量指标。通过执行一系列的局部编辑,在整个句子空间中搜索满足该目标函数的句子。因为我们的方法是无监督的,不需要平行语料库进行训练,因此可以方便地应用于不同领域的复述生成任务。我们在各种基准数据集上(Quora、Wikianswers、MSCOCO和Twitter)评估了本方法,结果表明,与以往的无监督方法相比,我们的方法在自动评估和人工评估方面都具备明显的优越性。此外,我们无监督方法优于大多数现有的领域自适应监督模型。
成为VIP会员查看完整内容
相关内容
专知会员服务
34+阅读 · 2020年6月19日
专知会员服务
27+阅读 · 2020年4月5日
专知会员服务
44+阅读 · 2020年3月26日
专知会员服务
33+阅读 · 2020年2月29日
Arxiv
8+阅读 · 2020年4月13日
Arxiv
5+阅读 · 2020年4月2日
Arxiv
11+阅读 · 2018年7月12日
相关主题
相关VIP内容
专知会员服务
34+阅读 · 2020年6月19日
专知会员服务
27+阅读 · 2020年4月5日
专知会员服务
44+阅读 · 2020年3月26日
专知会员服务
33+阅读 · 2020年2月29日
相关资讯
相关论文
Arxiv
8+阅读 · 2020年4月13日
Arxiv
5+阅读 · 2020年4月2日
Arxiv
11+阅读 · 2018年7月12日