深度学习中的互信息:无监督提取特征

作者丨苏剑林
单位丨广州火焰信息科技有限公司
研究方向丨NLP,神经网络
个人主页丨kexue.fm
对于 NLP 来说,互信息是一个非常重要的指标,它衡量了两个东西的本质相关性。笔者曾多次讨论过互信息,本人也对各种利用互信息的文章颇感兴趣。前段时间看到了最近提出来的 Deep INFOMAX 模型 [1],用最大化互信息来对图像做无监督学习,自然也颇感兴趣,研读了一番,就得到了本文。
本文整体思路源于 Deep INFOMAX 的原始论文,但并没有照搬原始模型,而是按照这自己的想法改动了模型(主要是先验分布部分),并且会在相应的位置进行注明。

▲ 随机采样的KNN样本
我们要做什么
自编码器
特征提取是无监督学习中很重要且很基本的一项任务,常见形式是训练一个编码器将原始数据集编码为一个固定长度的向量。自然地,我们对这个编码器的基本要求是:保留原始数据的(尽可能多的)重要信息。
我们怎么知道编码向量保留了重要信息呢?一个很自然的想法是这个编码向量应该也要能还原出原始图片出来,所以我们还训练一个解码器,试图重构原图片,最后的 loss 就是原始图片和重构图片的 mse。这导致了标准的自编码器的设计。后来,我们还希望编码向量的分布尽量能接近高斯分布,这就导致了变分自编码器。
重构的思考
然而,值得思考的是“重构”这个要求是否合理?
首先,我们可以发现通过低维编码重构原图的结果通常是很模糊的,这可以解释为损失函数 mse 要求“逐像素”重建过于苛刻。又或者可以理解为,对于图像重构事实上我们并没有非常适合的 loss 可以选用,最理想的方法是用对抗网络训练一个判别器出来,但是这会进一步增加任务难度。
其次,一个很有趣的事实是:我们大多数人能分辨出很多真假币,但如果要我们画一张百元大钞出来,我相信基本上画得一点都不像。这表明,对于真假币识别这个任务,可以设想我们有了一堆真假币供学习,我们能从中提取很丰富的特征,但是这些特征并不足以重构原图,它只能让我们分辨出这堆纸币的差异。也就是说,对于数据集和任务来说,合理的、充分的特征并不一定能完成图像重构。
最大化互信息
互信息
上面的讨论表明,重构不是好特征的必要条件。好特征的基本原则应当是“能够从整个数据集中辨别出该样本出来”,也就是说,提取出该样本(最)独特的信息。如何衡量提取出来的信息是该样本独特的呢?我们用“互信息”来衡量。
让我们先引入一些记号,用 X 表示原始图像的集合,用 x∈X 表示某一原始图像,Z 表示编码向量的集合,z∈Z 表示某个编码向量,p(z|x) 表示 x 所产生的编码向量的分布,我们设它为高斯分布,或者简单理解它就是我们想要寻找的编码器。那么可以用互信息来表示 X,Z 的相关性。
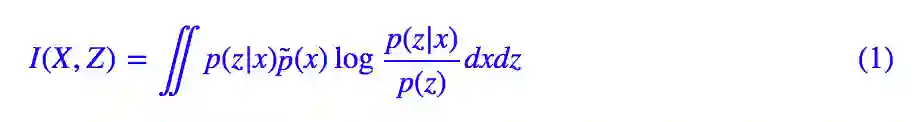
这里的 p̃(x) 原始数据的分布,p(z) 是在 p(z|x) 给定之后整个 Z 的分布,即:

那么一个好的特征编码器,应该要使得互信息尽量地大,即:

互信息越大意味着(大部分的)应当尽量大,这意味着 p(z|x) 应当远大于 p(z),即对于每个 x,编码器能找出专属于 x 的那个 z,使得 p(z|x) 的概率远大于随机的概率 p(z)。这样一来,我们就有能力只通过 z 就从中分辨出原始样本来。
注意:(1) 的名称为互信息,而对数项我们称为“点互信息”,有时也直接称为互信息。两者的差别是:(1) 计算的是整体关系,比如回答“前后两个词有没有关系”的问题;
计算的是局部关系,比如回答“‘忐’和‘忑’是否经常连在一起出现”的问题。
先验分布
前面提到,相对于自编码器,变分自编码器同时还希望隐变量服从标准正态分布的先验分布,这有利于使得编码空间更加规整,甚至有利于解耦特征,便于后续学习。因此,在这里我们同样希望加上这个约束。
Deep INFOMAX 论文中通过类似 AAE 的思路通过对抗来加入这个约束,但众所周知对抗是一个最大最小化过程,需要交替训练,不够稳定,也不够简明。这里提供另一种更加端到端的思路:设 q(z) 为标准正态分布,我们去最小化 p(z) 与先验分布 q(z) 的 KL 散度。
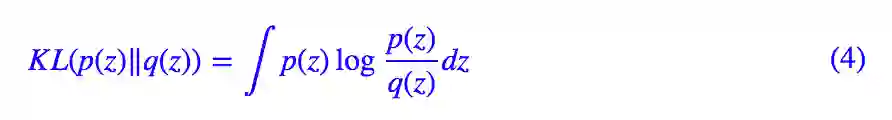
将 (1) 与 (4) 加权混合起来,我们可以得到最小化的总目标:
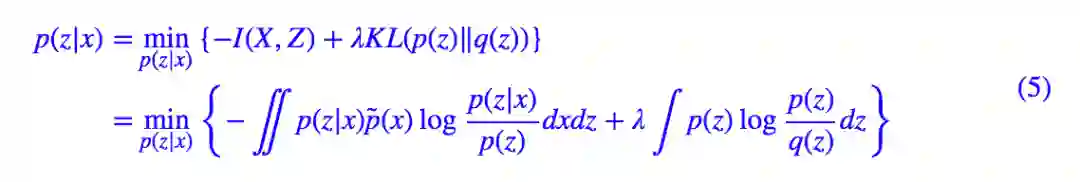
看起来很清晰很美好,但是我们还不知道 p(z) 的表达式,也就没法算下去了,因此这事还没完。
逐个击破
简化先验项
有意思的是式 (5) 的 loss 进行稍加变换得到:
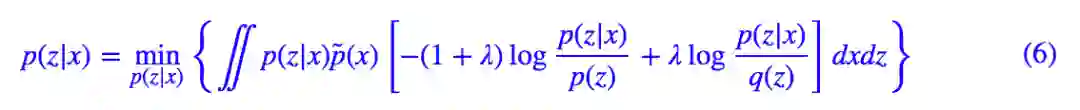
注意上式正好是互信息与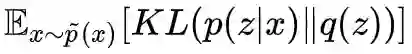
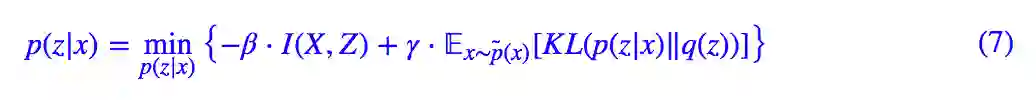
下面我们主攻互信息这一项。
互信息本质
现在只剩下了互信息这一项没解决了,怎么才能最大化互信息呢?我们把互信息的定义 (1) 稍微变换一下:
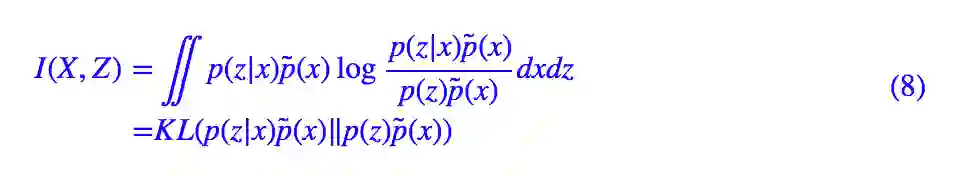
这个形式揭示了互信息的本质含义:p(z|x)p̃(x) 描述了两个变量 x,z 的联合分布,p(z)p̃(x) 则是随机抽取一个 x 和一个 z 时的分布(假设它们两个不相关时),而互信息则是这两个分布的 KL 散度。而所谓最大化互信息,就是要拉大 p(z|x)p̃(x) 与 p(z)p̃(x) 之间的距离。
注意 KL 散度理论上是无上界的,我们要去最大化一个无上界的量,这件事情有点危险,很可能得到无穷大的结果。所以,为了更有效地优化,我们抓住“最大化互信息就是拉大 p(z|x)p̃(x) 与 p(z)p̃(x) 之间的距离”这个特点,我们不用 KL 散度,而换一个有上界的度量:JS 散度(当然理论上也可以换成 Hellinger 距离,请参考 f-GAN简介:GAN模型的生产车间 [2]),它定义为:
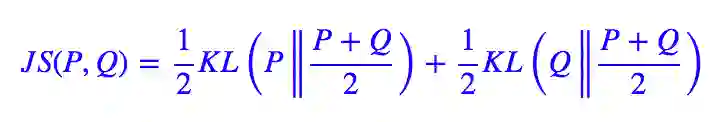
JS 散度同样衡量了两个分布的距离,但是它有上界,我们最大化它的时候,同样能起到类似最大化互信息的效果,但是又不用担心无穷大问题。于是我们用下面的目标取代式 (7):
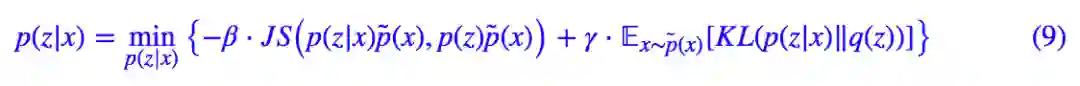
当然,这并没有改变问题的本质和难度,JS 散度也还是没有算出来。下面到了攻关的最后一步。
攻克互信息
在文章 f-GAN简介:GAN模型的生产车间 [2] 中,我们介绍了一般的 f 散度的局部变分推断,即那篇文章中的式 (13):
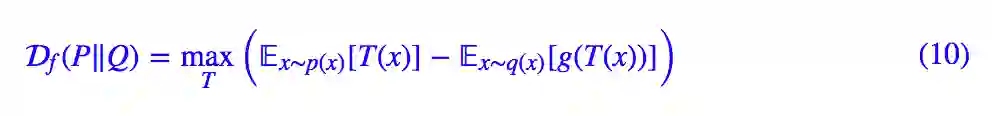
对于 JS 散度,给出的结果是:
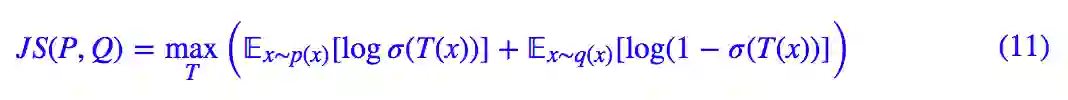
代入 p(z|x)p̃(x),p(z)p̃(x) 就得到:
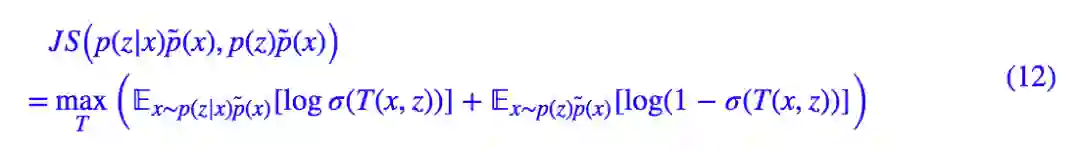
你没看错,除去常数项不算,它就完全等价于 deep INFOMAX 论文中的式 (5)。我很奇怪,为什么论文作者放着上面这个好看而直观的形式不用,非得故弄玄虚搞个让人茫然的形式。
其实 (12) 式的含义非常简单,它就是“负采样估计”:引入一个判别网络 σ(T(x,z)),x 及其对应的 z 视为一个正样本对,x 及随机抽取的 z 则视为负样本,然后最大化似然函数,等价于最小化交叉熵。
这样一来,通过负采样的方式,我们就给出了估计 JS 散度的一种方案,从而也就给出了估计 JS 版互信息的一种方案,从而成功攻克了互信息。现在,对应式 (9),具体的 loss 为:
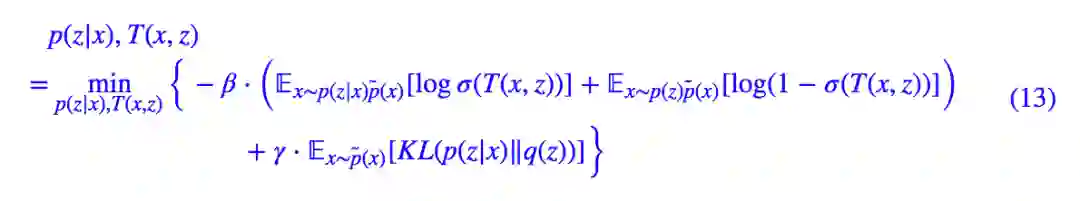
现在,理论已经完备了,剩下的就是要付诸实践了。
从全局到局部
batch内打乱
从实验上来看,式 (13) 就是要怎么操作呢?先验分布的 KL 散度那一项不难办,照搬 VAE 的即可。而互信息那一项呢?
首先,我们随机选一张图片 x,通过编码器就可以得到 z 的均值和方差,然后重参数就可以得到 zx,这样的一个 (x,zx) 对构成一个正样本。
负样本呢?为了减少计算量,我们直接在 batch 内对图片进行随机打乱,然后按照随机打乱的顺序作为选择负样本的依据,也就是说,如果 x 是原来 batch 内的第 4 张图片,将图片打乱后第 4 张图片是 x̂ ,那么 (x,zx) 就是正样本,(x̂,zx) 就是负样本。
局部互信息
上面的做法,实际上就是考虑了整张图片之间的关联,但是我们知道,图片的相关性更多体现在局部中(也就是因为这样所以我们才可以对图片使用 CNN)。换言之,图片的识别、分类等应该是一个从局部到整体的过程。因此,有必要把“局部互信息”也考虑进来。
通过 CNN 进行编码的过程一般是:

我们已经考虑了 x 和 z 的关联,那么中间层特征(feature map)和 z 的关联呢?我们记中间层特征为 {Cij(x)|i=1,2,…,h;j=1,2,…,w} 也就是视为 h×w 个向量的集合,我们也去算这 h×w 个向量跟 zx 的互信息,称为“局部互信息”。
估算方法跟全局是一样的,将每一个 Cij(x) 与 zx 拼接起来得到 [Cij(x),zx],相当于得到了一个更大的 feature map,然后对这个 feature map 用多个 1x1 的卷积层来作为局部互信息的估算网络 Tlocal。负样本的选取方法也是用在 batch 内随机打算的方案。
现在,加入局部互信息的总 loss 为:
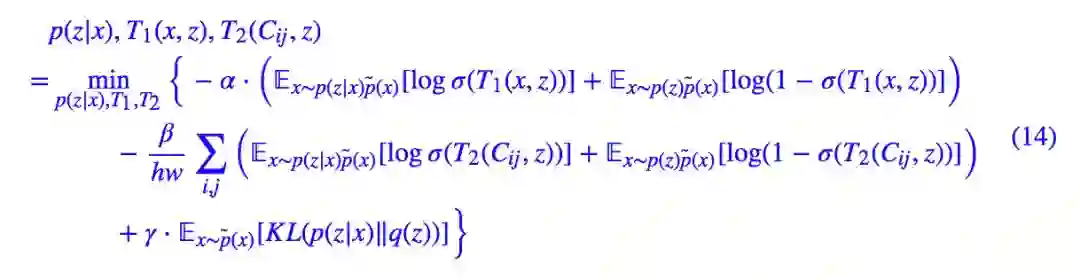
其他信息
其实,还有很多其他的信息可以考虑进去。
比如我们已经考虑了 Cij 与 z 的互信息,还可以考虑的是 Cij 之间的互信息,即同一张图片之间的 Cij 应当是有关联的,它们的互信息应该尽可能大(正样本),而不同图片之间的 Cij 应当是没关联的,它们的互信息应该尽可能小。不过我实验过,这一项的提升不是特别明显。
还有多尺度信息,可以手动在输入图片那里做多尺度的数据扩增,又或者是在编码器这些引入多尺度结构、Attention 结构。诸如此类的操作,都可以考虑引入到无监督学习中,提高编码质量。
类似的word2vec
其实,熟悉 NLP 中的 word2vec 模型原理的读者应该会感觉到:这不就是图像中的 word2vec 吗?
没错,在原理和做法上 deep INFOMAX 跟 word2vec 大体都一样。在 word2vec 中,也是随机采集负样本,然后通过判别器来区分两者的过程。这个过程我们通常称为“噪声对比估计”,我们之前也提到过,word2vec 的噪声对比估计过程(负采样)的实际优化目标就是互信息,细节请参考“噪声对比估计”杂谈:曲径通幽之妙。
word2vec 中,固定了一个窗口大小,然后在窗口内统计词的共现(正样本)。而 deep INFOMAX 呢?因为只有一张图片,没有其他“词”,所以它干脆把图片分割为一个个小块,然后把一张图片当作一个窗口,图片的每个小块就是一个个词了。当然,更准确地类比的话,deep INFOMAX 更像类似 word2vec 的那个 doc2vec 模型。
换个角度来想,也可以这样理解:局部互信息的引入相当于将每个小局部也看成了一个样本,这样就相当于原来的 1 个样本变成了 1+hw 个样本,大大增加了样本量,所以能提升效果。
同时这样做也保证了图片的每一个“角落”都被用上了,因为低维压缩编码,比如 32×32×3 编码到 128 维,很可能左上角的 8×8×3>128 的区域就已经能够唯一分辨出图片出来了,但这不能代表整张图片,因此要想办法让整张图片都用上。
开源和效果图
参考代码
其实上述模型的实现代码应当说还是比较简单的,总比我复现 Glow 模型容易几十倍。不管用哪个框架都不困难,下面是用 Keras 实现的一个版本:
https://github.com/bojone/infomax
来,上图片
无监督的算法好坏比较难定量判断,一般都是通过做很多下游任何看效果的。就好比当初词向量很火时,怎么定量衡量词向量的质量也是一个很头疼的问题。deep INFOMAX 论文中做了很多相关实验,我这里也不重复了,只是看看它的 KNN 效果(通过一张图片查找最相近的 k 张图片)。
总的来说效果差强人意,我觉得精调之后做一个简单的以图搜图问题不大。原论文中的很多实验效果也都不错,进一步印证了该思路的威力。
CIFAR-10
每一行的左边第一张是原始图片,右边 9 张是最邻近图片,用的是 cos 相似度。用欧氏距离的排序结果类似。

Tiny ImageNet
每一行的左边第一张是原始图片,右边 9 张是最邻近图片,用的是 cos 相似度。用欧氏距离的排序结果类似。

全局 vs 局部
局部互信息的引入是很必要的,下面比较了只有全局互信息和只有局部互信息时的 KNN 的差异。

又到终点站
作为无监督学习的成功,将常见于 NLP 的互信息概念一般化、理论化,然后用到了图像中。当然,现在看来它也可以反过来用回 NLP 中,甚至用到其他领域,因为它已经被抽象化了,适用性很强。
deep INFOMAX 整篇文章的风格我是很喜欢的:从一般化的理念(互信息最大化)到估算框架再到实际模型,思路清晰,论证完整,是我心中的理想文章的风格(除了它对先验分布的处理用了对抗网络,我认为这是没有必要的)。期待看到更多的这类文章。
参考文献
[1]. Learning Deep Representations by Mutual Information Estimation and Maximization R Devon Hjelm, Alex Fedorov, Samuel Lavoie, Karan Grewal, Phil Bachman, Adam Trischler, Yoshua Bengio. ArXiv 1808.06670.
[2]. https://kexue.fm/archives/6016

点击以下标题查看作者其他文章:
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看作者博客




