基于GAN的字体风格迁移 | CVPR 2018论文解读

在碎片化阅读充斥眼球的时代,越来越少的人会去关注每篇论文背后的探索和思考。
在这个栏目里,你会快速 get 每篇精选论文的亮点和痛点,时刻紧跟 AI 前沿成果。
点击本文底部的「阅读原文」即刻加入社区,查看更多最新论文推荐。
本期推荐的论文笔记来自 PaperWeekly 社区用户 @kaitoron。本文首次提出用端到端的方案来解决从少量相同风格的字体中合成其他艺术字体,例如 A-Z 26 个相同风格的艺术字母,已知其中 A-D 的艺术字母,生成剩余 E-Z 的艺术字母。
本文研究的问题看上去没啥亮点,但在实际应用中,很多设计师在设计海报或者电影标题的字体时,只会创作用到的字母,但想将风格迁移到其他设计上时,其他的一些没设计字母需要自己转化,造成了不必要的麻烦。
如何从少量(5 个左右)的任意类型的艺术字中泛化至全部 26 个字母是本文的难点。本文通过对传统 Condition GAN 做扩展,提出了 Stack GAN 的两段式架构,首先通过 Conditional GAN #1 根据已知的字体生成出所有 A-Z 的字体,之后通过 Conditional GAN #2 加上颜色和艺术点缀。
如果你对本文工作感兴趣,点击底部的阅读原文即可查看原论文。
关于作者:黄亢,卡耐基梅隆大学硕士,研究方向为信息抽取和手写识别,现为波音公司数据科学家。
■ 论文 | Multi-Content GAN for Few-Shot Font Style Transfer
■ 链接 | https://www.paperweekly.site/papers/1781
■ 源码 | https://github.com/azadis/MC-GAN
论文动机
在很多 2D 宣传海报设计中,艺术家们花了很多时间去研究风格兼容的艺术字,也因此只去设计当前作品中所需要的少部分字母,之后若是作品成功想要将艺术字的风格转移到其他项目中时,难免会出现新的字母,这时候得花更多的时间去补充和完善。
本文希望在只看到少量已有艺术字母的劣势下,通过 GAN 来自动生成那些我们需要但又缺失的相同风格的字母。
模型介绍
本文的模型建立在许多已有的工作基础之上。先从宏观角度来看,整个网络分为两个个阶段:第一阶段先根据不同字母之间的相互联系产生出基本的灰度字形,第二阶段给字母上色以及合成相应的装饰效果。
GAN 本来就难训练,作为 Stack GAN 我们有必要把第一阶段网络给预训练一下。那就让我们把 Stack GAN 拆成 Glyph(字形)网络和 Ornamentation(修饰)网络单独来看。
Glyph 网络其实是 Conditional GAN [1] 的衍生,只不过中间网络更复杂,损失函数更加丰富。
我们知道传统 GAN 的输入是 Random Noise,这里它采用了和 Conditional GAN 一样的做法,只把要模仿的字母作为输入而忽略了 Random Noise。输入维度是B X 26 X 64 X 64,B 是 Batch Size,26 指的是 A-Z,64X64 指的是每个字母图片的长宽大小。

▲ 图1:Glyph Network输入示例
Glyph 网络中 Generator 延续了 Image Transformation Network [2] 中相同的架构,即多层 ResNet Block 抽取隐含特征再通过 transpose convolution 上采样输出和原来大小一致的图片,即输出也是 B X 26 X 64 X 64。
这里值得注意的是,作者没有直接将图 1 作为输入,否则二维卷积由于横向的感受野太小很难捕捉到相邻较远字符之间(例如 A 和 Z)的特征。因此作者巧妙的增加了一个维度——输入字母的数目,即将平铺开来的输入图片给垂直垒起来。
作者在代码中第一层还用了三维卷积去模拟了用独立不相关的 filter 去二维卷积每个字母图片的效果,经过 Image Transformation Network 的输出也为 B X 26 X 64 X 64,也就是 64 X 64 的 fake A-Z 26 个字母。
Discriminator 引用了 PatchGAN [1] 的思想,即在公共网络加了 3 层卷积层采用了 21 × 21 Local Discriminator 去衡量局部真假,然后又在公共网络上平行加了 2 层作为 Global Discriminator 去衡量整个图片的真假。
最后,Glyph 网络有 3 个 loss:Local & Global Discrimnator 的 least squares GAN ( LSGAN ) loss [3],以及 Generator 的 L1 loss。loss 之间的权重作为网络的 hyperparameter。
整个网络的示意图如下图:
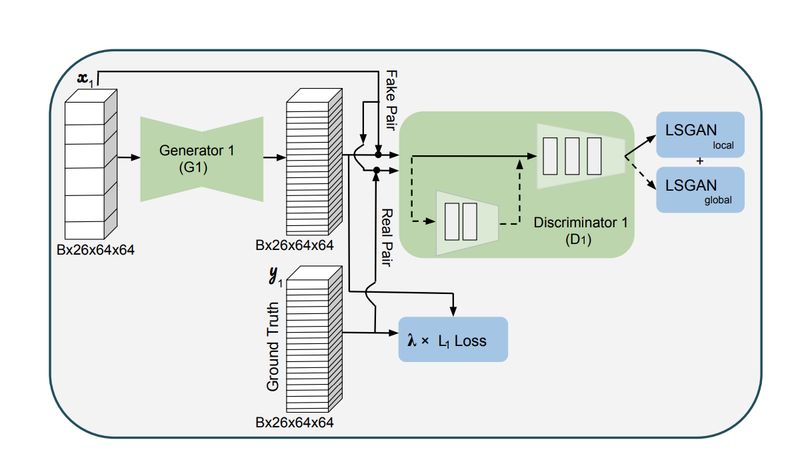
▲ 图2
Ornamentation 网络架构本质上和 Glyph 网络是一样的,但不同的在于 GlyphNet 从大量的训练字体中学得字形联系,而 OrnaNet 是从少量已观察到的艺术字符中,学习如何把已观察到的字母颜色或修饰迁移到其他未观察到字母上。
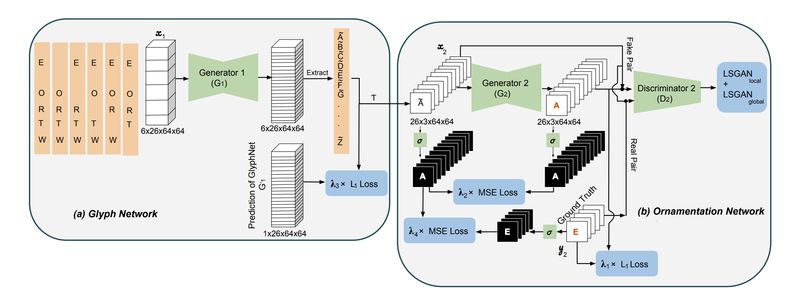
▲ 图3
最后要 end2end training 两个网络,此时 GlyphNet 已经有了 pretrained model。最后的训练只是 finetune,所以理所当然地拆掉了 Discriminator 只保留了 Generator。
真正需要训练的是 random initialized 的 OrnaNet,整个网络的输入换成了图 3 所示左图,采用 leave one out 通过 GlyphNet 生成 OrnaNet 的输入。
例如图 4 原本观察到字符是 water 的艺术字,GlyphNet 的输入是便是 water 这 5 个字母依次轮流抽出一个后的其中 4 个作为输入(wate),抽出的那一个作为要 predict 的字母(r),最后是 5 个字母全部在场的情况下预测其余 22 个字母。
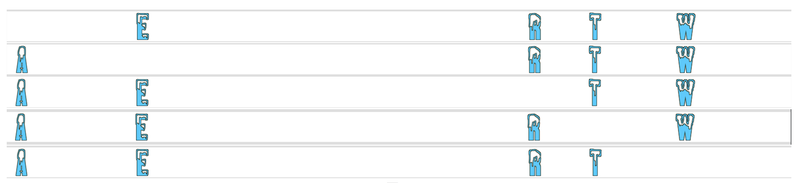
▲ 图4
换句话说就是 GlyphNet 的输出仍然是 6 X 26 X 64 X 64,但我们拿对应想要的维度拼接成 1 X 26 X 64 X 64,即 26 个灰度字形作为 OrnaNet 的输入。也就是说,OraNet 最后的输出就是最后完整的 26 个艺术字了。
为了稳定训练,OrnaNet 除了具备和 Glyph 一样的 3 个 loss,又额外增加了两个二值化掩码损失(sigmoid),分别是 Generator 的输入和输出的 mean square error,以及 Generator 的输入和 ground truth 的 mean square error,共计 6 个loss function。各个 loss 之间的权重仍是网络的超参。
实验结果
本文以 Image to Image Translation Network [5] 为 baseline,做了几个小实验:
1. Ablation Study(控制变量实验),通过是否预训练模型,去除某些模块的 loss 来体验网络各个部分对整体字体效果做出的贡献。
2. A-Z 不同字体之间的关系,Structural Similarity 是一种测量字体相似程度的标准,我们可以通过大量的 test 画出已知 A 字体,预测出的 B 字体和真实 B 字体之间的 Structural Similarity 的分布,由此我们可以定性地分析出各个字符对于任意字符预测的信息贡献量。
3. 研究关于输入字符的数量对于 GlyphNet 预测质量的影响,发现当输入字符为 6 时,Structural Similarity 的分布已经趋于稳定。
4. 主观评价:由于 task 特殊无法定量的用 metric 去衡量,找了 11 个人在 MC-GAN 和 Patch Synthesis Model [4] 产生的结果之间做选择,80% 胜出。
总结心得
文本融合已有的大量 GAN 的成果,本文将字体风格迁移的工作分为两个阶段逐个击破,首先生成字体,其次添加颜色和修饰。此外,利用字母之间相互的联系,只用少量字母就能将风格迁移到所有字母,也是本文的一大特色。
小小的不足是实验只包括了 26 个字体,实际中我们可能还需要包括数字或小写字母。虽然生成的质量和 baseline 相比有很大提高,但和 Ground Truth 比起来仍有差距。
最后,虽然文章着眼于 2D deisgn 中艺术字的风格迁移,不过把第一个网络单独拿出来用于生成 handwriting 的 data 也是值得研究的。
参考文献
[1] P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros. Image-to-image translation with conditional adversarial networks. arXiv preprint arXiv:1611.07004, 2016.
[2] J. Johnson, A. Alahi, and L. Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In European Conference on Computer Vision, pages 694–711. Springer.
[3] X. Mao, Q. Li, H. Xie, R. Y. Lau, Z. Wang, and S. P. Smolley. Least squares generative adversarial networks.
[4] Yang, J. Liu, Z. Lian, and Z. Guo. Awesome typography: Statistics-based text effects transfer. arXiv preprint arXiv:1611.09026, 2016.
本文由 AI 学术社区 PaperWeekly 精选推荐,社区目前已覆盖自然语言处理、计算机视觉、人工智能、机器学习、数据挖掘和信息检索等研究方向,点击「阅读原文」即刻加入社区!

点击以下标题查看相关内容:


我是彩蛋
解锁新功能:热门职位推荐!
PaperWeekly小程序升级啦
今日arXiv√猜你喜欢√热门职位√
找全职找实习都不是问题
解锁方式
1. 识别下方二维码打开小程序
2. 用PaperWeekly社区账号进行登陆
3. 登陆后即可解锁所有功能
职位发布
请添加小助手微信(pwbot02)进行咨询
长按识别二维码,使用小程序
*点击阅读原文即可注册

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看原论文



