Github大热论文 | U-GAT-IT:基于GAN的新型无监督图像转换

作者丨武广
学校丨合肥工业大学硕士生
研究方向丨图像生成
生成对抗网络(GAN)在这几年的发展下已经渐渐沉淀下来,在网络的架构、训练的稳定性控制、模型参数设计上都有了指导性的研究成果。我们可以看出 17、18 年大部分关于 GAN 的有影响力的文章多集中在模型自身的理论改进上,如 PGGAN、SNGAN、SAGAN、BigGAN、StyleGAN 等,这些模型都还在强调如何通过随机采样生成高质量图像。19 年关于 GAN 的有影响力的文章则更加关注 GAN 的应用上,如 FUNIT、SPADE 等已经将注意力放在了应用层,也就是如何利用 GAN 做好图像翻译等实际应用任务。
学术上的一致性也暗示了 GAN 研究的成熟,本文主要介绍一篇利用 GAN 的新型无监督图像转换论文。


论文引入
提出了一种新的无监督图像到图像转换方法,它具有新的注意模块和新的归一化函数 AdaLIN。
注意模块通过基于辅助分类器获得的注意力图区分源域和目标域,帮助模型知道在何处进行密集转换。
-
AdaLIN 功能帮助注意力引导模型灵活地控制形状和纹理的变化量,增强模型鲁棒性。
模型结构
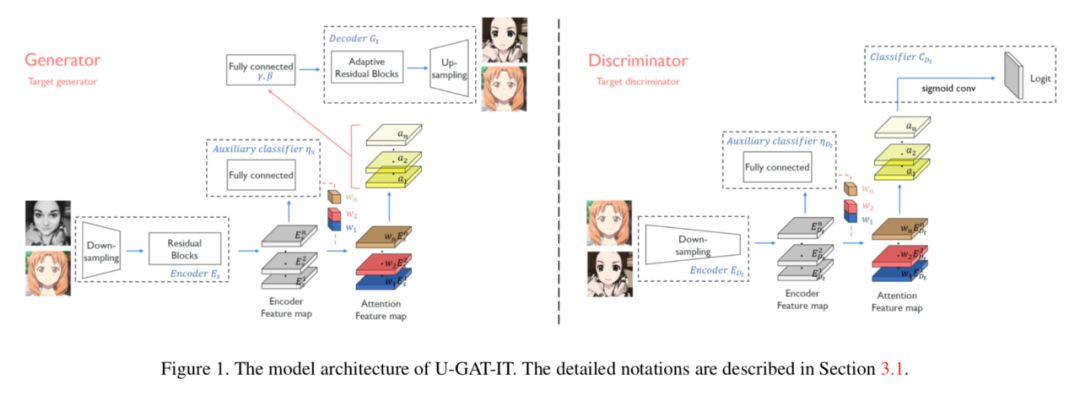
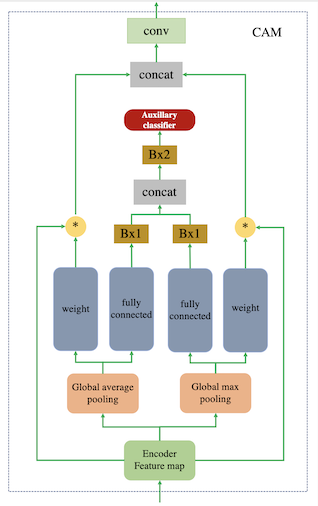
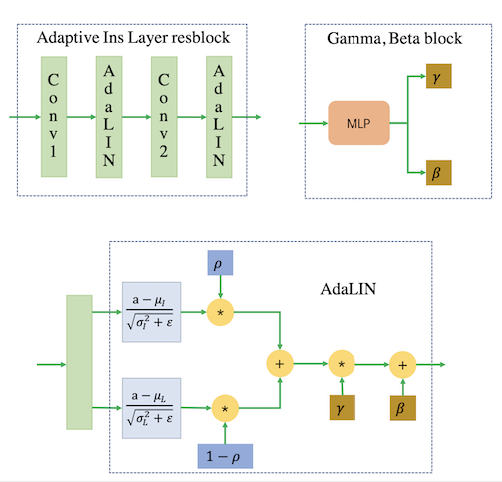
损失函数
对于利用 GAN 实现图像到图像转换的损失函数其实也就那几个,首先是 GAN 的对抗损失,循环一致性损失
,以及身份损失(相同域之间不希望进行转换)
,最后说一下 CAM 的损失。CAM 的损失主要是生成器中对图像域进行分类,希望源域和目标域尽可能分开,这部分利用交叉熵损失:
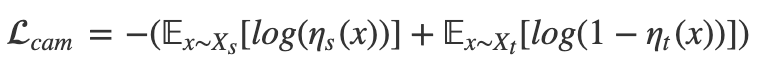
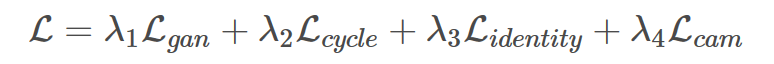
def adaptive_instance_layer_norm(x, gamma, beta, smoothing=True, scope='instance_layer_norm'):
with tf.variable_scope(scope):
ch = x.shape[-1]
eps = 1e-5
# 计算Instance mean,sigma and ins
ins_mean, ins_sigma = tf.nn.moments(x, axes=[1, 2], keep_dims=True)
x_ins = (x - ins_mean) / (tf.sqrt(ins_sigma + eps))
# 计算Layer mean,sigma and ln
ln_mean, ln_sigma = tf.nn.moments(x, axes=[1, 2, 3], keep_dims=True)
x_ln = (x - ln_mean) / (tf.sqrt(ln_sigma + eps))
# 给定rho的范围,smoothing控制rho的弹性范围
if smoothing:
rho = tf.get_variable("rho", [ch], initializer=tf.constant_initializer(0.9),
constraint=lambda x: tf.clip_by_value(x,
clip_value_min=0.0, clip_value_max=0.9))
else:
rho = tf.get_variable("rho", [ch], initializer=tf.constant_initializer(1.0),
constraint=lambda x: tf.clip_by_value(x,
clip_value_min=0.0, clip_value_max=1.0))
# rho = tf.clip_by_value(rho - tf.constant(0.1), 0.0, 1.0)
x_hat = rho * x_ins + (1 - rho) * x_ln
x_hat = x_hat * gamma + beta
return x_hat
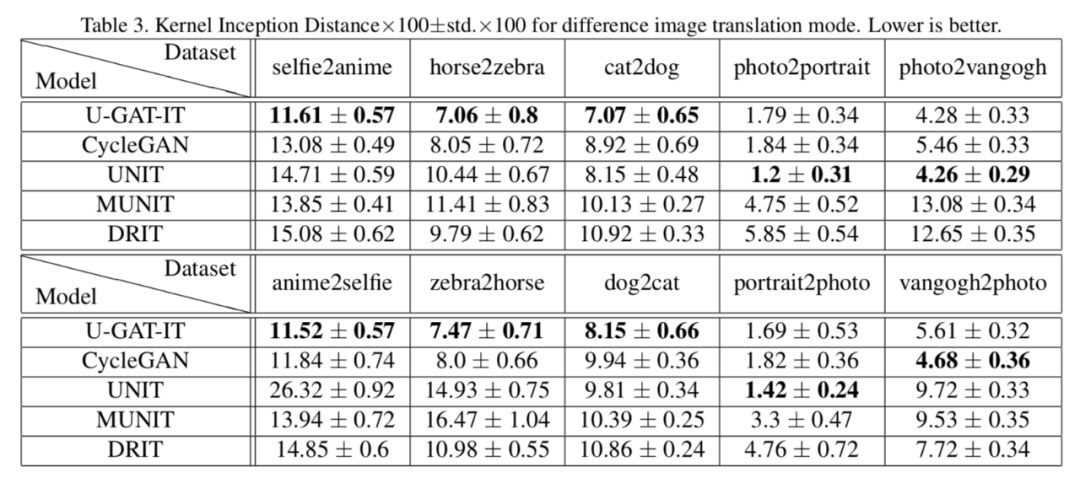
实验

总结
参考文献
[1] Goodfellow I, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets[C]//Advances in neural information processing systems. 2014: 2672-2680.
[2] B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba. Learning deep features for discriminative localization. In Computer Vision and Pattern Recognition (CVPR), 2016 IEEE Conference on, pages 2921–2929. IEEE, 2016. 2, 3
[3] H. Nam and H.-E. Kim. Batch-instance normalization for adaptively style-invariant neural networks. arXiv preprint arXiv:1805.07925, 2018. 2, 3

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 下载论文 & 源码



