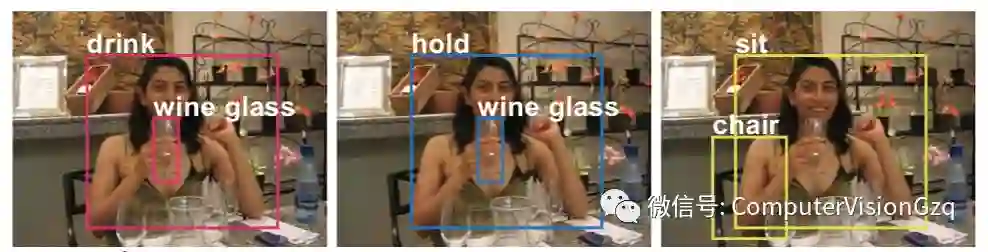
检测与识别人与目标之间的互动
深度学习有在新的高度得到大家的认可,并驱使更多的爱好者去学习、去探索,已不仅仅在图像、视频及语音领域得到重视。现在在SLAM、NLP、医学、经济学等领域都得到愈来愈多的研究者的重视,今天我们就和大家说说人与物体目标之间的互动检测识别,有兴趣的您可以接下来慢慢享受~
01 概述
——————
要理解视觉世界,机器不仅必须识别单个目标,还必须识别它们是如何交互的。人类往往处于这种相互作用的中心,而检测人与目标之间的相互作用是一个重要的实践和科学问题。
在本次分享中,其提出了在挑战日常照片中检测⟨人类、动词、目标⟩三元组的任务。提出了一种新的模型,它是由一种以人为中心的方法驱动的。
具体的假设是,一个人的外表-他们的姿势、衣服、动作-是一个强有力的线索,可以帮助他们定位与互动的物体。为了利用这一线索,模型学会了根据被检测的人的外观来预测目标对象位置上的特定动作密度;模型还联合学习检测人和物体,并通过融合这些预测,在一个干净的、联合训练的端到端系统中,有效地推断出三元组之间的交互,称之为InteractNet。
对COCO(V-COCO)和HICO-Det数据集中最近引入的动词验证了该方法,在这些数据集中展示了令人信服的结果。
那接下来开始我们今天的主题:
02 背景
—————————
对个体实例的视觉识别,例如,检测对象和估计人的行动/姿势,由于深度学习的视觉表现,已经得到了显著的改进。然而,识别个体对象只是机器理解视觉世界的第一步。要了解图像中发生的情况,还必须识别各个实例之间的关系。在这项工作中,我们将重点放在人与人之间的互动。

提出了一种以人为中心的人机交互识别模型。中心观察是,一个人的外表,它揭示了他的动作和姿势,对于推断交互的目标对象可能在哪里是非常有用的(如上图B)。因此,对目标对象的搜索空间可以通过这种估计条件来缩小。虽然经常检测到许多对象(如上图A),但推断的目标布局可以帮助模型快速选择与特定操作关联的正确对象(如上图C)。
于是,将这一思想作为一个以人为中心的识别分支在Fast R-CNN框架中实现。具体来说,在与人相关的感兴趣区域(ROI)上,该分支对动作的目标对象位置执行动作分类和密度估计。密度估计器预测每种行为类型的四维高斯分布,它模拟目标对象与人的可能相对位置。这种预测完全基于人类的外表。
这个以人为中心的识别分支,以及一个标准的对象检测分支和一个简单的两两交互分支(后面描述),构成了一个可以联合优化的多任务学习系统。
03 方法
—————————
我们现在开始描述检测人-对象交互作用的方法。
目标是检测和识别三元组的形式⟨人类,动词,对象⟩。要检测三元组的交互,我们必须准确地定位包含人和目标的框,以关联交互对象(分别由bh和bo表示),以及识别正在执行的操作(从A行为中选择)。
提出的解决方案将这个复杂和多方面的问题分解成一个简单和可管理的形式。其扩展了Faster R-cnn目标检测框架,增加了一个以人为中心的分支,该分支对行为进行分类,并估计每个行为在目标位置上的概率密度。
以人为中心的分支利用Fast R-CNN提取的特征进行目标检测,其边缘计算是轻量级的。具体来说,给定一组候选框,Fast R-CNN为每个框输出一组对象框和一个类标签。模型通过给候选人/对象框bh、bo和动作a分配一个三元组得分s来扩展这一点。为此,将三元组分数分解为四个项:
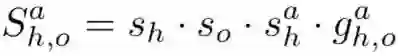
接下来,将讨论每个组件,然后是一个扩展,它将动作分类输出s替换为一个专门的交互分支,该分支根据人和对象的外观为动作a输出评分。最后给出了训练和推理的细节。下图展示了整个框架中的每个组件。
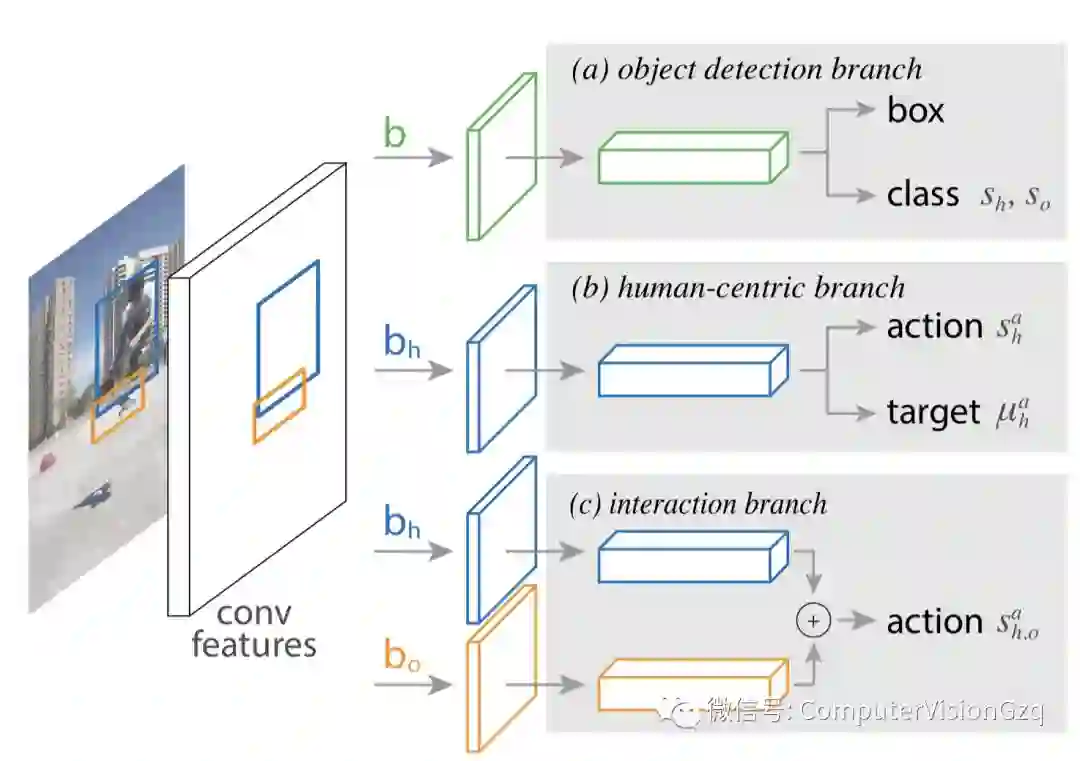
目标检测
网络的目标检测分支,如上图(A)所示,与Faster R-CNN完全相同。首先,使用区域候选网络(RPN)生成目标候选。然后,对于每个候选框b,使用RoiAlign提取特征,并执行目标分类和边界盒的回归,以获得一组新的框,其中每个框都有相关的分数(如果将框分配给Person类别,则为sh)。这些新框仅在推理时使用;在训练期间,所有分支都使用RPN候选框进行训练。
行为分类
以人为中心的分支的第一个角色是为每个人的框、bh和动作a分配一个行为分类得分sah。就像在目标分类分支中一样,使用RoiAlign从bh中提取特征,并预测每个动作a的得分。由于人类可以同时执行多个动作(例如坐姿和饮料),输出层由用于多标签动作分类的二进制sigmoid分类器组成。训练目标是最大限度地减少真实动作标签与模型预测的得分之间的二元交叉熵损失。
目标定位
以人为中心的分支的第二个角色是根据人的外观(同样表示为从bh集合的特性)来预测目标的位置。然而,仅根据bh的特征来预测精确的目标位置是一项具有挑战性的工作。
相反,本次的方法是预测可能位置上的密度,并将此输出与实际检测目标的位置一起用于精确定位目标。将目标物体位置上的密度建模为一个高斯函数,该函数的均值是根据人的外观和正在执行的动作来预测的。形式上,以人类为中心的分支预测,目标的四维平均位置给定人类边界框bh和动作a。然后,将目标定位写成如下:
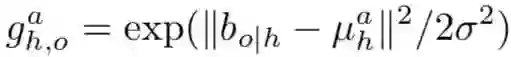
下图可视化了目标位置上的预测分布,例如人工/动作对。
正如我们所看到的,下图所示描述的黄色虚线框是从bh和a推断出来的,没有直接访问目标的权限。

从直觉上讲,模型的公式是基于这样一个假设,即从bh计算的特征包含指向某一动作目标的强信号,即使该目标在bh之外。
我们认为,这种“outside-the- box”回归是可能的,因为人的外表为目标位置提供了强有力的线索。此外,由于这一预测是特定于行为和具体实例的,即使我们使用单峰分布来建模目标位置,模型的公式也是有效的。后面我们讨论了该方法的一个变体,它允许我们有条件地处理多模态分布并预测单个动作的多个目标。
交互识别
以人为中心的模型根据人的外表来评分动作。虽然有效,但这并没有考虑到目标的外观。为了提高模型的识别能力,并展示框架的灵活性,可以将SAH替换为交互分支,该分支基于人和目标的外观来记分动作。我们使用s来表示这个替代项。
04 多任务训练
——————————
我们将学习人-对象交互作为一个多任务学习问题:上图所示的所有三个分支都是联合训练的。
总体损失是模型中所有损失的总和,包括:
目标检测分支的分类和回归损失;
以人为中心的分支的行为分类和目标定位损失;
交互分支的行为分类损失。
这与我们在前面描述的级联推理形成了对比,其中目标检测分支的输出被用作以人为中心的分支的输入。
采用以图像为中心的训练。所有的损失都是在RPN候选和真实框上进行的,就像在Faster R-CNN中一样。从目标检测分支的每幅图像中抽取最多64个边界框,正负比为1:3。以人为中心的分支最多在与人类类别相关联的16个框bh上计算(即,它们的IOU与一个真实人框重叠为≥0.5)。相互作用分支的损失仅在正例子三元组(即⟨bh,a,bo⟩必须与真实互作用三元组相关联)上计算。所有损失项的权重均为1,但以人为中心的分支中的行为分类项的权重为2,实验发现这一项的性能更好。
05 Cascaded Inference
———————————————
在推理中,我们的目标是根据S找到高分三元组。虽然原则上这具有O(N2)复杂度,因为它需要对每对候选框打分,但提出了一种简单的级联推理算法,其主要计算具有O(N)复杂度。
目标检测分支:首先检测图像中的所有对象(包括Person类)。将非极大抑制(NMS)的IOU阈值设置为0.3应用于分数高于0.05的框(保守地设置为了保留大多数目标)。这一步产生了一组新的更小的n个框b,分数为s等等。与训练不同,这些新框用作其余两个分支的输入。
人类中心分支:接下来,将以人为中心的分支应用于所有被归类为人类的检测对象。对于每个动作a和检测到的人类边界框bh,计算s,分配给a的分数,以及μ,预测的目标位置相对bh的平均偏移量。这个步骤的复杂性为O(N)。
交互分支:如果使用可选的交互分支,必须计算每个动作的s,o和一对框bh和bo。为此,首先独立的计算每个框bh和bo的两个动作分类heads的逻辑,即O(N)。然后,为了得到分数s,o,这些逻辑被求和,并通过一个sigmoid。虽然最后一步是O(N2),但实际上它的计算时间可以忽略不计。
06 实验
———————————————
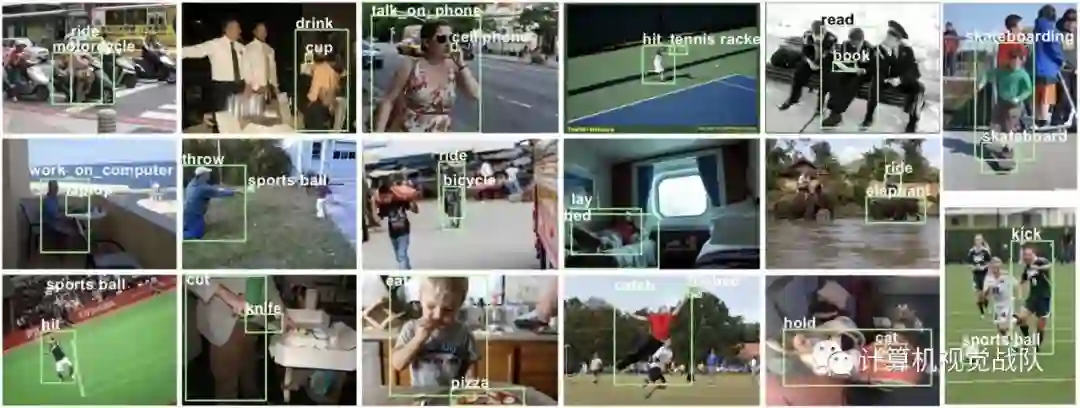
在V-COCO测试集上的结果

All detected triplets on two V-COCO test images

InteractNet在测试图像上的结果。每个子个体可以采取多个操作并影响多个对象。
其他方法的比较:

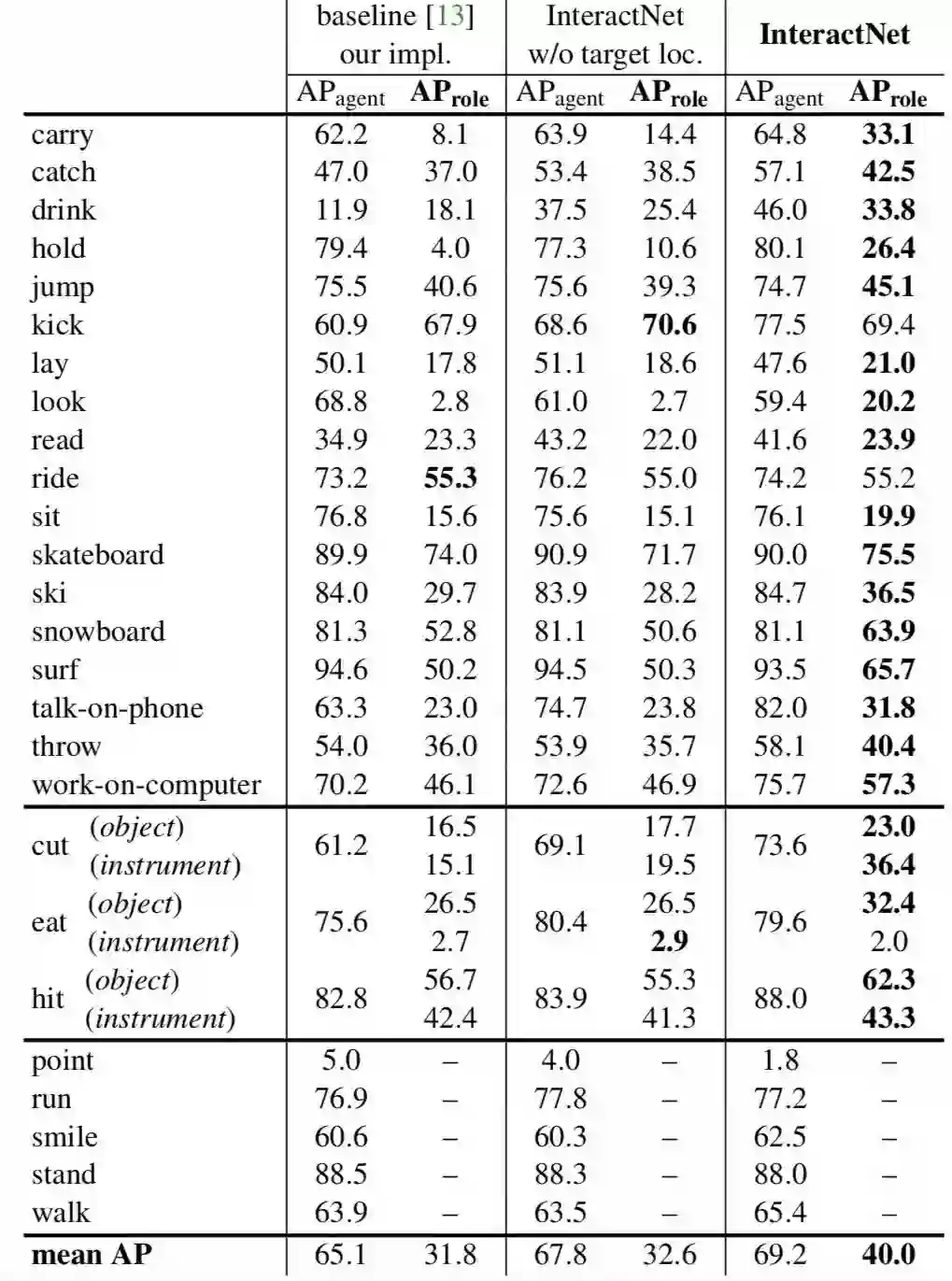
V-COCO试验的详细结果。为每个动作显示两个主要基线和InteractNet。在[13]中定义了26个动作,由于3个动作(cut, eat, hit)涉及两种目标对象(instrument and direct object),因此有26项。在AProle上大胆地展示了领先的项。

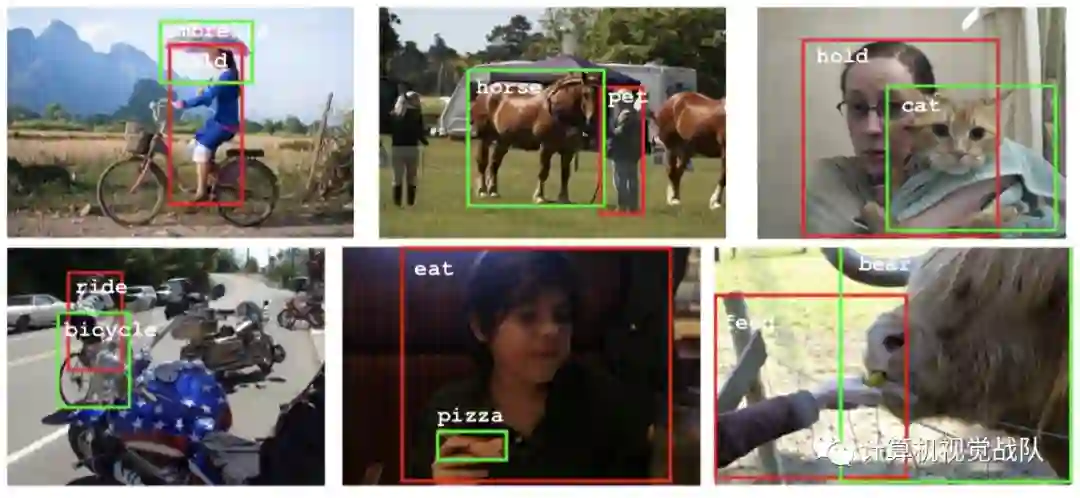
False positive detections of our method
在HICO-DET测试集上的结果
文章下载地址:
https://pan.baidu.com/s/1B5f4zt4FttrKHb6LXM4fGQ
如果想加入我们“计算机视觉战队”,请扫二维码加入学习群,我们一起学习进步,探索领域中更深奥更有趣的知识!





