Performer: 基于正交随机特征的快速注意力计算

最近要开始使用Transformer去做一些事情了,特地把与此相关的知识点记录下来,构建相关的、完整的知识结构体系。
以下是要写的文章,本文是这个系列的第二十篇:
-
Transformer:Attention集大成者 -
GPT-1 & 2: 预训练+微调带来的奇迹 -
Bert: 双向预训练+微调 -
Bert与模型压缩 -
Transformer + AutoML: 进化的Transformer -
Bert变种 -
Roberta: Bert调优 -
Electra: 判别还是生成,这是一个选择 -
Bart: Seq2Seq预训练模型 -
Transformer优化之自适应宽度注意力 -
Transformer优化之稀疏注意力 -
Reformer: 局部敏感哈希和可逆残差带来的高效 -
Longformer: 局部attentoin和全局attention的混搭- Linformer: 线性复杂度的Attention -
Performer: 基于正交随机特征的快速注意力计算(本篇) -
XLM: 跨语言的Bert -
T5 (待续) -
更多待续 -
LAMB: 76分钟训练Bert -
Meena: Google的开放域聊天机器人 -
GPT-3 -
更多待续
Overall
在前面的文章中,我们介绍了Reformer,Longformer和Linformer来对attention的计算进行了优化。已经遗忘的同学可以在上面的链接中出门左转复习一下。
本文则介绍的Performer是一个更新的优化方法,是2020年9月发出的论文,目标和Linformer类似,都是达到了线性复杂度的效果,但Linformer依赖的是将矩阵转成低秩矩阵进行计算,虽然有理论的保证,但实际使用中不免效果有所折扣。
Performer则不依赖于注意力的稀疏性和低秩矩阵,也能达到线性的效果。它使用了FAVOR+的方法,全称为Fast Attention Via positive Orthogonal Random features approach。接下来,我们就来一步一步的进行解释。
回顾Attention
首先,让我们来回顾一下Attention的计算方法,attention的计算公式其实就是 softmax(QKT/sqrt(d_k))*V,而在本文中,采用了另一种等价的表达形式,如下所示,其中diag是将一个输入向量变成对角矩阵,1L则是一个长度为L的全为1的向量。
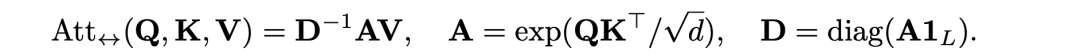
这里的不同点就是把softmax进行了拆分,其中,diag(A1L)是为了求和,D-1则是将这些和变成倒数,所以D-1A跟softmax(QKT/sqrt(d_k))是等价的。
核技法与注意力的碰撞
在上面的公式中,A是两个矩阵的乘积除以常数后再做一个指数操作,得到一个注意力矩阵,在这里,引入核技法来对这个注意力矩阵A做近似。
具体的方法如下:
对于Q和K中的任何一个向量qi和kj,它们原来的相似度不考虑归一化的是是exp(qikj)。在引入核技法后,计算方式变为:
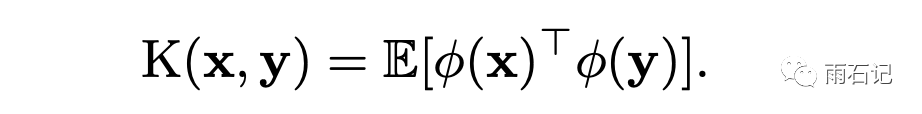
其中φ是一个d为到r维的映射。假设能够找到φ使得这个相似度计算跟之前计算方式的结果一样。那么Q,K,V的计算就可以通过结合律来进行降低。如下图:
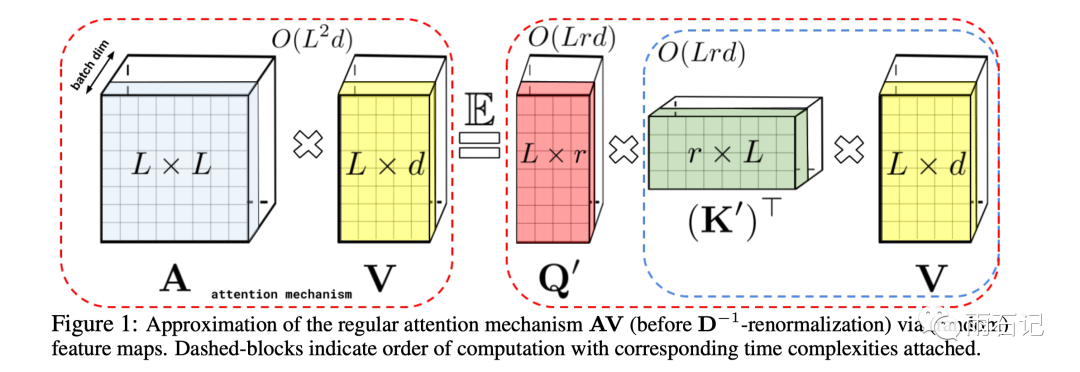
可以看到,原来是LxL的矩阵和Lxd的矩阵相乘,需要的计算复杂度是O(L2d),而在改变后,变成了O(Lrd),其中r和d都是常数。
原来的相似度计算中,指数操作的存在使得Q,K,V的矩阵操作无法换顺序。
经过这个变换后,FAVOR+中的FA我们就解释了。
核技法近似exp
继续看核技法。不失通用性,将核技法的映射函数φ定义如下:
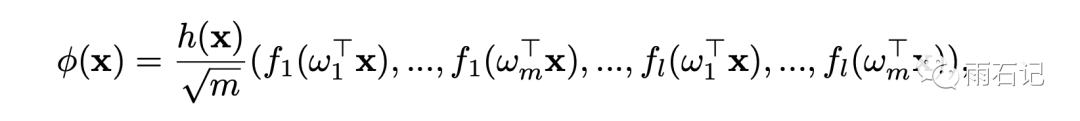
其中f1, ..., fl是不同的映射函数,w1, ..., wm则是从一个分布D中采样出来的,即它们是独立同分布的。
当h(x)=1, l=1, D=N(0, Id)的时候,这个核就是所谓的PNG-kernel。
当h(x)=1, l=2, f1=sin, f2=cos的时候,就是shift-invariant核。此时如果D=N(0, Id),那么就是高斯核。
对于softmax核来说,需要拟合的是SM(x, y) = exp(xTy)。而这个公式和如下公式是等价的:
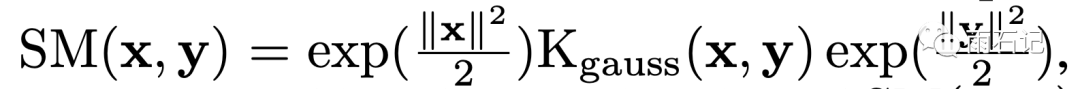
上面公式的最后一部分是水印可能看不清楚,是 exp(||y||2/2)
此时h(x) = exp(||x||2/2),f1=sin, f2=cos, l=2。
在这里,我们需要得到的权重都应该是正值,而这个替换后的公式中因为有sin和cos的存在,有可能是负值,一旦有负值,经过多层的计算之后,会使得和原始计算方法的方差变得非常的大,造成不好的后果。
在这里,提出了一种无偏近似,同时又能保证得到的结果是正值。

因为参数w都是随机生成的,所以这里解释了FAVOR+的R部分。
正交
为了进一步降低方差,一般会考虑多组正交的w参数。这是个常用的技巧,在Gram-Schmidt重归一化的时候,不管使用什么分布,都要保证无偏性即可。这部分可以在参考文献[2]中详细了解。
这就解释了FAVOR+的O部分。
加了正交后,上面的PRF就变成了ORF。PRF和ORF可以使我们能够尽可能的减小r从而获得更好的加速比。
论文的绝大部分都在做这个近似方法的理论证明,本文科普性质,所以不涉及,感兴趣的朋友可以去读原始论文。读懂了才算得上入门深度学习了呢。:)
实验
使用了Jax上Transformer的实现来进行的实验,Jax是DeepMind常用框架。
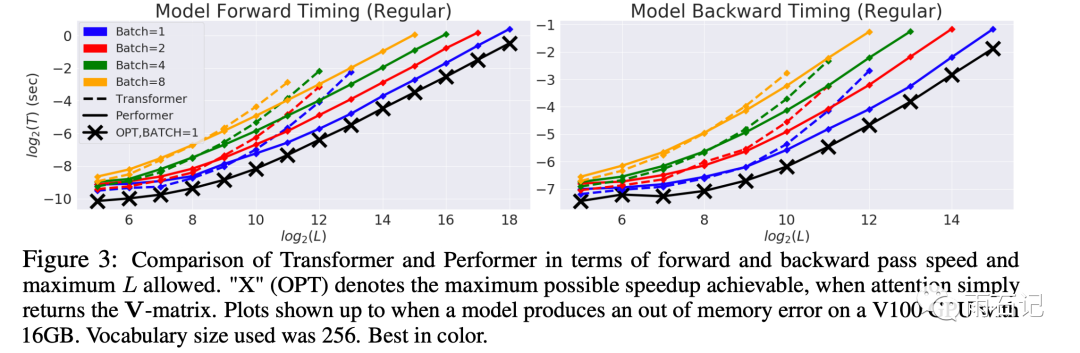
Performer和Transformer的对比如下,可见,Performer相对于Transformer速度上优势显然,尤其是输入比较长的时候。
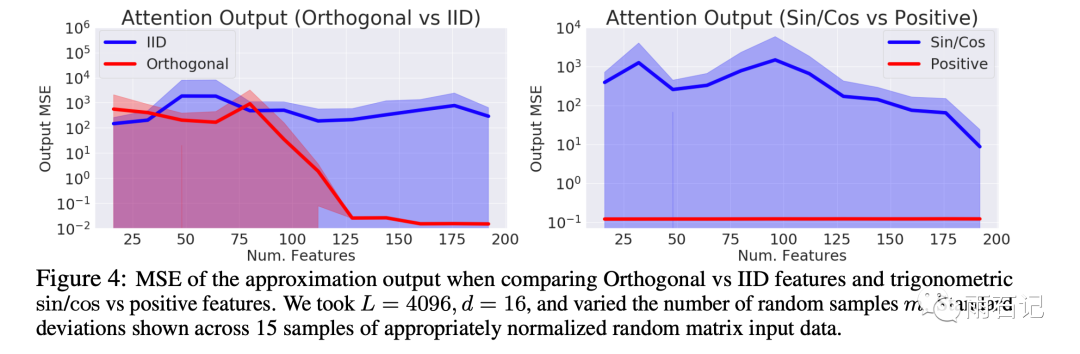
再来看一下论文提出的方法的方差对比,如下,左图是独立同分布和正交的对比,右图则是sin/cos和positive的对比。可以看到,Performer中的正交和positive特性都是必不可少的。
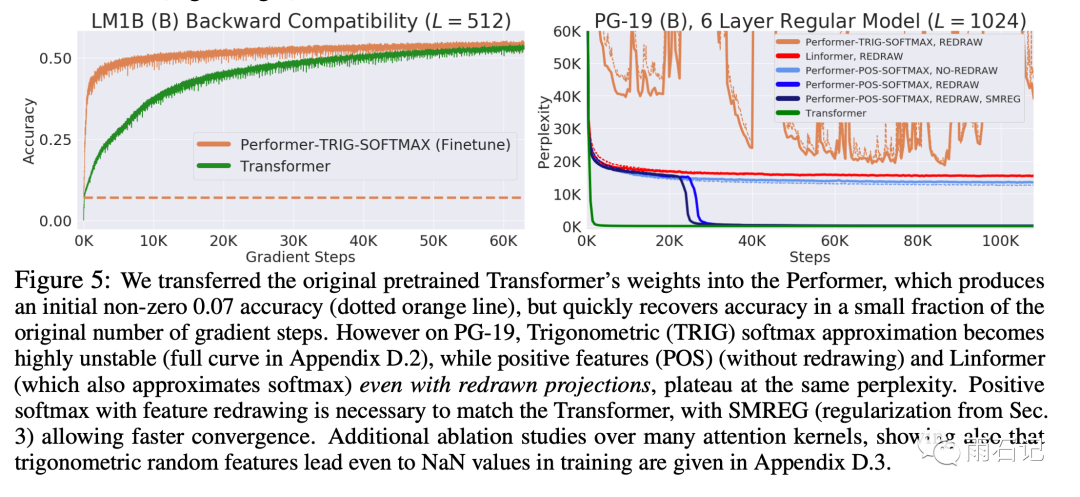
另外,还有一些比较有意思的结论,如下图所示:
-
Performer具有后向兼容性,可以用之前训练好的transformer来初始化Performer,经过fine-tune后可以快速还原到原来Transformer的结果。同时更快,见左图。 -
正值特性是必不可少的,用sin/cos会导致loss不稳定,见右图。
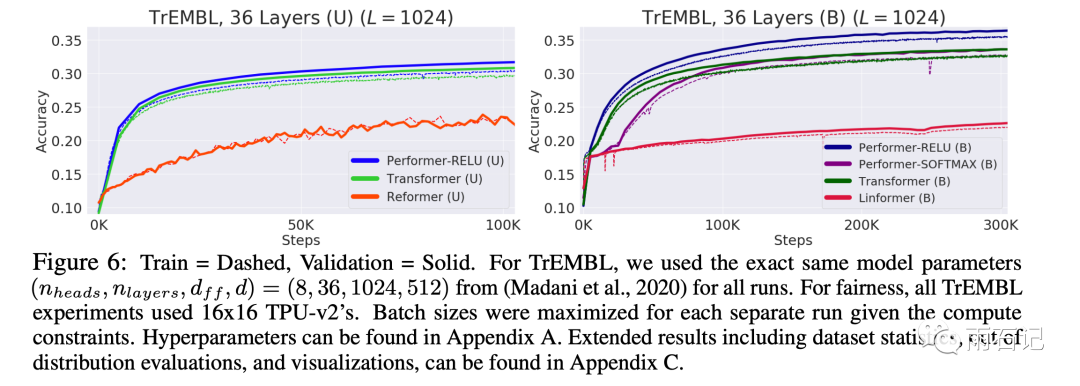
在蛋白质序列建模上的对比, 其中U代表的是单向Transformer,B则是双向。Performer的动机就是在蛋白质序列建模上达到更好的效果。可以看到,Performer要远远优于Reformer和Linformer。
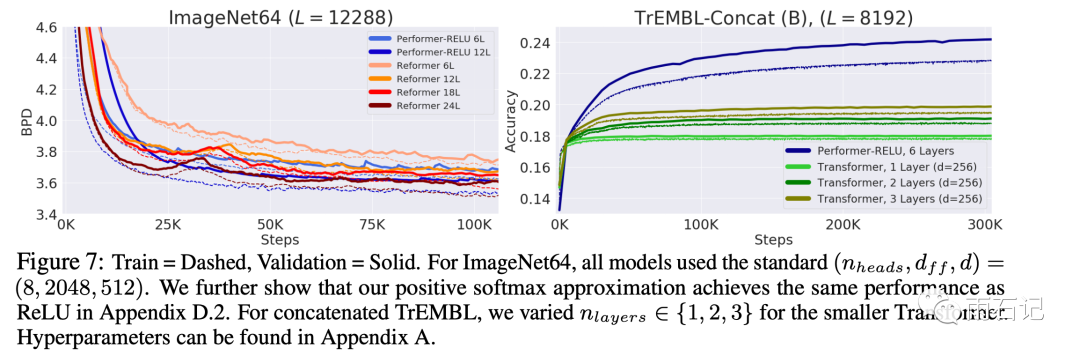
在更长的任务上的表现,如下图,在ImageNet上,Performer要比Reformer快2倍。而在蛋白质序列建模上,Performer甚至可以超过Transformer,因为Transformer无法使用更深的层次了。
总结与思考
Performer通过将指数操作进行拆分近似,换取了两种优化:
-
近似算法上的优化,使用尽可能小的r来达到。 -
矩阵乘法结合律上的优化。
在保证近似的程度上,使用了核技法,正值和正交技巧。
本文的数学性很强,感觉有一些细节我没有说清楚,不过脉络都梳理清楚了,十分鼓励感兴趣的同学去看原文,感觉非常强大。
勤思考,多提问是Engineer的良好品德。
-
Performer如何保证向后兼容,即如何用训练好的Transformer去初始化Performer? -
核方法不止一种,有没有其他的核方法能达到更好的效果(假设暂时不考虑性能)?
参考文献
-
[1]. Choromanski, K., Likhosherstov, V., Dohan, D., Song, X., Gane, A., Sarlos, T., ... & Belanger, D. (2020). Rethinking attention with performers. arXiv preprint arXiv:2009.14794. -
[2]. Krzysztof Marcin Choromanski, Mark Rowland, and Adrian Weller. The unreasonable effectiveness of structured random orthogonal embeddings. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, 4-9 December 2017, Long Beach, CA, USA, pp. 219–228, 2017.
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏



