万字长文带你一览ICLR2020最新Transformers进展(上)

Transformer体系结构最初是在Attention is All You Need[1]中提出的,它是顺序语言建模方法(如LSTM[2])的有效替代方法,此后在自然语言处理领域变得无处不在,从而推动了大多数下游语言的发展相关任务。
今年的国际学习表示法会议(ICLR[3])中有许多文章对原始的Transformer及其最新的BERT[4]和Transformer-XL[5]进行了改进。这些改进措施解决了Transformer众所周知的弱点:
-
优化自我注意力计算。 -
在模型架构中注入出于语言动机的归纳偏差。 -
使模型更具参数和数据效率。
这篇文章希望总结并提供这些贡献的高层概述,重点介绍更好和更快的自然语言处理模型的当前趋势。所有图像版权归其各自的论文作者。
1. Self-atention的变体
可缩放的点积自注意力是标准Transformer层中的主要组件之一,无论依赖关系在输入中的距离如何,都可以对其进行建模。自注意力机制大家都已经很熟悉,其公式为:
进一步,多头自注意力机制的公式为:
本节介绍了自我注意组件的一些变体,使其在上下文处理中更加有效。
Long-Short Range Attention
Introduced in: Lite Transformer with Long-Short Range Attention[6] by Wu, Liu et al.

通过将输入沿通道尺寸分成两部分并将每个部分输入两个模块,Long-Short Range Attention (LSRA) 可使计算效率更高。两个模块分别是使用标准自注意的全局提取器和使用轻量级深度卷积的局部提取器。作者指出这种方法可以减少一半模型的整体计算,使其适合于移动端。
Tree-Structured Attention with Subtree Masking
Introduced in: Tree-Structured Attention with Hierarchical Accumulation[7] by Nguyen et al.
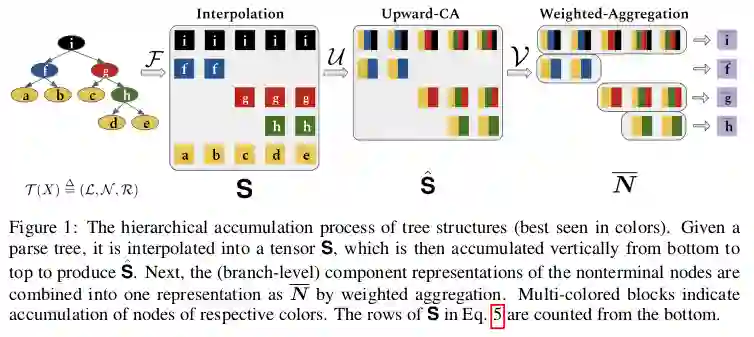
标准Transformer的一个缺点是缺少归纳偏差来解释语言的层次结构。这部分是由于通常通过递归或递归机制建模的树状结构,难以保持恒定的自我注意时间复杂性。
本文所提出的解决方案是利用输入文本的句法分析来构建隐藏状态树,并使用分层累加将非叶子节点的值用子节点聚合来表示。最终的输出表示通过分支级表示的加权聚合来构建。
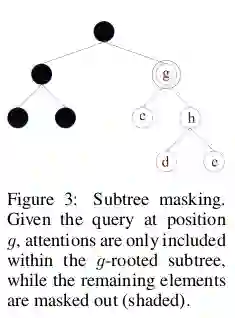
本文另一个有趣的想法是通过限制每个节点查询仅关注其子树,使用子树遮罩来过滤掉多余的噪声。这种归纳偏差的引入方式会增加计算和存储成本,文章使用参数共享来减轻这种成本。
Hashed Attention
Introduced in: Reformer: The Efficient Transformer[8] by Kitaev et al.

由于self-attention的时间复杂度与序列长度的平方成正比,给建模长序列带来了困难。Reformer提出将每个查询所涉及的候选者池限制为通过本地敏感哈希(LSH)找到的一小部分邻居。由于LSH分桶采用随机投影的方法,因此类似的向量有时可能会落在不同的邻域中。文中使用多轮并行哈希处理来缓解此问题。使用LSH注意可以将自我注意操作的计算成本降低到 ,允许模型在更长的序列上运行。
关于LSH可以参考我们之前的文章REALM后续:最近邻搜索,MIPS,LSH和ALSH。
eXtra Hop Attention
Introduced in: Transformer-XH: Multi-Evidence Reasoning with eXtra Hop Attention[9] by Zhao et al.
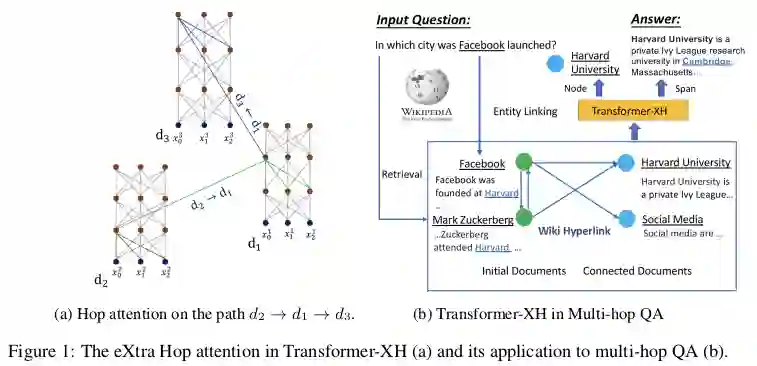
尽管对Transformer可以在单个序列或序列对上进行操作获得很好结果,但它们却很难推广到证据分散在多段文本中的情况,例如颇具挑战性的多跳问答任务。
Transformer-XH引入了一种新的注意力变体eXtra Hop Attention,可以将其应用于由边(例如,超链接)连接的文本序列图。这种新的注意力机制将每个序列开头的特殊标记[CLS]用作关注中心(attention hub),该中心attend到图中的其他相连接的序列。然后将所得表示通过线性投影的标准自注意力机制进行组合。模型展示出对需要对图进行推理任务的显着改进,但新的注意力机制引入了额外的计算代价。
2. 训练目标
Transformer模型的预训练通常是通过多个不受监督的目标来实现的,并利用了大量的非注释文本。用于此目的的最常见任务是自回归语言建模(也称为标准语言建模,LM)和对掩码输入的自动编码(通常称为掩码语言建模,MLM)。
标准的Transformer实现及其GPT变体采用自回归方法,利用序列内部的单向上下文(正向或反向)估计下一个token的概率分布:
类似BERT的方法使用双向上下文来恢复输入被特殊[MASK] token替代的一小部分。事实证明,此变体对下游自然语言理解任务特别有效。
除了单词级建模之外,由于许多重要的语言应用程序都需要理解两个序列之间的关系,因此通常在训练过程中添加诸如下一个句子预测(NSP)之类的句子级分类任务。关于BERT,可以参考我们之前的文章[预训练语言模型专题] BERT,开启NLP新时代的王者。
尽管这些任务可以获得有意义的token和句子层表示,但本节将介绍一些更好的替代方法,这些方法可以使学习更加有效。
Discriminative Replacement Task
Introduced in: ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators[10] by Clark et al.
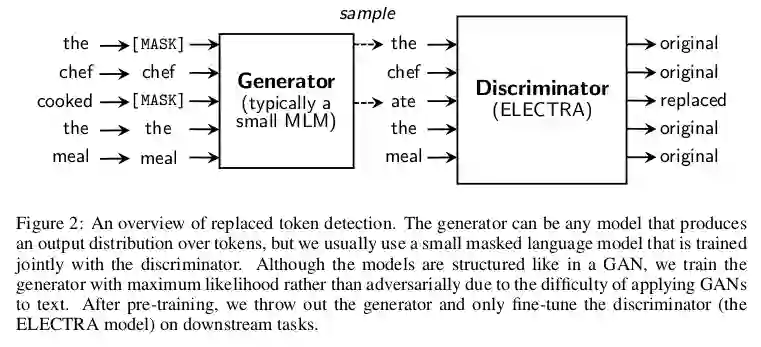
在类似BERT的模型中使用的掩蔽策略在数据上效率很低,仅使用约15%的输入文本来完成MLM任务。但是,由于过多的masked token可能会使整体上下文信息损失严重,因此很难增加屏蔽数据的百分比。
ELECTRA提出了一种简单而有效的方法来应对这种效率低下的问题。像普通的MLM一样,训练一个小的屏蔽语言模型,然后将其用作生成器,用其填充输入中被屏蔽的token。但是,主模型的新任务将是一个分类任务:除了预测掩盖的token之外,该模型还必须检测生成器替换了哪些token。这允许利用整个输入序列进行训练。正如作者所提到的,在相同的计算预算下,这种方法始终优于MLM预训练。
关于Electra,可以参考我们之前的文章性能媲美BERT却只有其1/10参数量? | 近期最火模型ELECTRA解析。
Word and Sentence Structural Tasks
Introduced in: StructBERT: Incorporating Language Structures into Pre-training for Deep Language Understanding[11] by Wang et al.
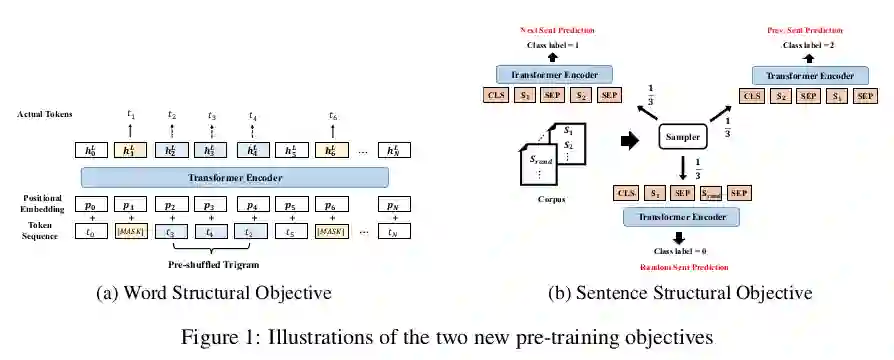
如前所述,Transformers并未明确考虑输入中存在的语言结构。虽然树状结构的注意力在模型体系结构中注入了很多的结构信息,但StructBERT采用了两种更轻便但有效的方法,使生成的表示形式更了解语言的基本顺序。
第一个是单词结构目标(word structural objective),即输入的三字组(trigram)被随机打乱,模型必须重新构造其原始顺序。这是与常规MLM并行完成的。句子结构目标(sentence structural objective) 是ERNIE 2.0中句子重排任务和ALBERT中SOP任务的轻量级变体:给定一对句子对(S1, S2)作为输入,我们要求模型区分S1是在S2之前、之后或与之无关。这项新任务扩展了标准的NSP任务,NSP对于学习有意义的句子关系来说太容易了。这些改进带来了自然语言理解能力的提升。
Type-Constrained Entity Replacement
Introduced in: Pretrained Encyclopedia: Weakly Supervised Knowledge-Pretrained Language Model[12] by Xiong et al.

尽管很多研究已经显示,经过预训练的Transformer模型隐式地捕获了现实世界的知识,但是它们的标准训练目标并未明确考虑到在现实世界中进行可靠推理所需的以实体为中心的信息。
带类型约束的实体替换(Type-constrained entity replacement) 是一种弱监督的方法,文本中的实体随机地被具有相同实体类型的其他来自Wikidata的实体替换。然后,该模型使用类似于ELECTRA的判别目标来确定实体是否被替换。这是在多任务设置中与MLM一起完成的,并且作者报告说,由于更深入地了解实体,该模型在例如开放域QA和实体类型预测等问题中有显著的提升。
万字长文实在是太长了,今天又是周末,所以我们决定分两天放送。明天将介绍Embedding和模型结构两方面的内容,不见不散哦~
参考资料
Attention is All You Need: https://arxiv.org/abs/1706.03762
[2]LSTM: https://www.researchgate.net/publication/13853244_Long_Short-term_Memory
[3]ICLR官网: https://iclr.cc/
[4]BERT: https://www.aclweb.org/anthology/N19-1423/
[5]Transformer-XL: https://www.aclweb.org/anthology/P19-1285/
[6]Lite Transformer with Long-Short Range Attention: https://iclr.cc/virtual_2020/poster_ByeMPlHKPH.html
[7]Tree-Structured Attention with Hierarchical Accumulation: https://iclr.cc/virtual_2020/poster_HJxK5pEYvr.html
[8]Reformer: The Efficient Transformer: https://iclr.cc/virtual_2020/poster_rkgNKkHtvB.html
[9]Transformer-XH: Multi-Evidence Reasoning with eXtra Hop Attention: https://iclr.cc/virtual_2020/poster_r1eIiCNYwS.html
[10]ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators: https://iclr.cc/virtual_2020/poster_r1xMH1BtvB.html
[11]StructBERT: Incorporating Language Structures into Pre-training for Deep Language Understanding: https://iclr.cc/virtual_2020/poster_BJgQ4lSFPH.html
[12]Pretrained Encyclopedia: Weakly Supervised Knowledge-Pretrained Language Model: https://iclr.cc/virtual_2020/poster_BJlzm64tDH.html
推荐阅读
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。





