校招基础算法 | SVM常见问题
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
原文作者:Jack Stark
原文连接:https://zhuanlan.zhihu.com/p/81890745
支持向量机(SVM)是机器学习中在数学理论上非常完善的一种模型,李航的《统计学习方法》和网上都有比较详细的解释。本文参考了一些资料,对见到的SVM相关问题进行汇总,便于自己复习,也希望对大家有用。
SVM是什么及其优化目标是什么?
SVM的基本模型是一个二分类模型,是定义在特征空间上的间隔最大的线性分类器。它的优化目标是找到几何间隔最大的分离超平面。
SVM分为三种:线性可分支持向量机、线性支持向量机和非线性支持向量机。它们的区别如下:
当训练数据线性可分时,通过硬间隔最大化,学习一个线性分类器,即线性可分支持向量机。
当训练数据近似线性可分时,通过软间隔最大化,学习一个线性分类器,即线性支持向量机。
当训练数据线性不可分时,通过使用核技巧及软间隔最大化,学习非线性支持向量机。
SVM中的核方法是什么?
当输入空间为欧式空间或离散集合、特征空间为希尔伯特空间时,核函数表示将输入从输入空间映射到特征空间得到的特征向量之间的内积。通过核方法可以学习非线性支持向量机,等价于在高维的特征空间中学习线性支持向量机。
核方法是比SVM中更为一般的机器学习方法,可以用到PCA、K-means等多种模型中。
SVM中的函数间隔和几何间隔是什么?
对于训练样本 



对于一个训练集来说,函数距离越小,超平面越好。但是函数距离有一个问题,仅仅增加w和b的值就可以放大距离,这并非我们想要的结果。因此对上式进行归一化,得到几何间隔如下:

讲一下SVM中松弛变量
和惩罚因子
 和惩罚因子
和惩罚因子 
松弛变量和惩罚因子是为了把线性可分SVM拓展为线性不可分SVM的。只有被决策面分类错误的点(线性不可分点)才会有松弛变量,然后惩罚因子是对线性不可分点的惩罚。 增大惩罚因子,模型泛化性能变弱,惩罚因子无穷大时,退化为线性可分SVM(硬间隔);减少惩罚因子,模型泛化性能变好。
并非所有的样本点都有一个松弛变量与其对应。实际上只有“离群点”才有,或者说,所有没离群的点松弛变量都等于0
松弛变量的值实际上标示出了对应的点到底离群有多远,值越大,点就越远。
惩罚因子C决定了你有多重视离群点带来的损失,显然当所有离群点的松弛变量的和一定时,你定的C越大,对目标函数的损失也越大,此时就暗示着你非常不愿意放弃这些离群点, 最极端的情况是你把C定为无限大,这样只要稍有一个点离群,目标函数的值马上变成无限大,马上让问题变成无解,这就退化成了硬间隔问题。当C无穷大时,为了最小化损失函数,只能使松弛变量 无穷小(趋近于0),等价于线性可分SVM。
为什么要将求解 SVM 的原始问题转换为其对偶问题
使对偶问题更易求解,当我们寻找带约束的最优化问题时,为了使问题变得易于处理,可以把目标函数和约束全部融入拉格朗日函数,再求解其对偶问题来寻找最优解。
可以自然引入核函数,进而推广到非线性分类问题。
SVM中系数的求解
SMO(Sequential Minimal Optimization)算法。有多个拉拉格朗日乘子,每次只选择其中两个乘子做优化,其他因子被认为是常数。将N个变量的求解问题,转换成两个变量的求解问题,并且目标函数是凸的。
为什么SVM对缺失数据敏感
这里说的缺失数据是指缺失某些特征数据,向量数据不完整。SVM 没有处理缺失值的策略。而 SVM 希望样本在特征空间中线性可分,所以特征空间的好坏对SVM的性能很重要。缺失特征数据将影响训练结果的好坏。
SVM的损失函数
SVM的损失函数如下,第一项称为经验风险(Hinge loss), 度量了模型对训练数据的拟合程度; 第二项称为结构风险(正则项), 度量了模型自身的复杂度。正则化项削减了假设空间, 从而降低过拟合风险。λ 是个可调节的超参数, 用于调整经验风险和结构风险的相对权重。
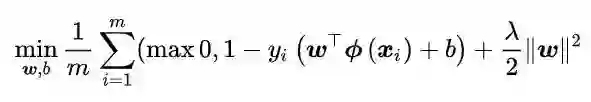
SVM中的核函数的优缺点及如何选择
常用的三种核函数的优缺点如下:

如何选择核函数?
当特征维数 d 超过样本数 m 时 (文本分类问题通常是这种情况), 使用线性核;
当特征维数 d 比较小,样本数 m 中等时, 使用RBF核;
当特征维数 d 比较小,样本数 m 特别大时, 支持向量机性能通常不如深度神经网络。
讲一下SVR(支持向量回归)
传统回归模型的损失是计算模型输出f(x)和真实值y之间的差别,当且仅当f(x)=y时,损失才为零;但是SVR假设我们能容忍f(x)和y之间有一定的偏差,仅当f(x)和y之间的偏差大于该值时才计算损失。
SVM的优缺点
优点:
由于SVM是一个凸优化问题,所以求得的解一定是全局最优而不是局部最优。
不仅适用于线性线性问题还适用于非线性问题(用核技巧)。
拥有高维样本空间的数据也能用SVM,这是因为数据集的复杂度只取决于支持向量而不是数据集的维度,这在某种意义上避免了“维数灾难”。
理论基础比较完善。
缺点:
二次规划问题求解将涉及m阶矩阵的计算(m为样本的个数), 因此SVM不适用于超大数据集。(SMO算法可以缓解这个问题)。
当样本数量比较大时,效果通常不如神经网络。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、检测分割识别、三维视觉、医学影像、GAN、自动驾驶、计算摄影、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
投稿、合作也欢迎联系:simiter@126.com
长按关注计算机视觉life
推荐阅读
干货总结 | SLAM 面试常见问题及参考解答
2019 最新SLAM、定位、建图求职分享,看完感觉自己就是小菜鸡!
2019暑期计算机视觉实习应聘总结 2019秋招AI算法岗复盘
最新AI干货,我在看




