前沿 | 不使用深度学习,进化算法也能玩Atari游戏!
选自arXiv
作者:Dennis G Wilson等
机器之心编译
深度学习因为其强大的表征能力,在很多方面都有非常优秀的性能,它不论是在计算机视觉、自然语言处理,还是在游戏智能体上都能构建出优秀的模型。而最近图卢兹联邦大学等研究者表示进化算法也有着与深度学习相类似的潜力,它可以进化出一些能玩 Atari 游戏的智能体,并取得与人类相匹配的性能。
近期街机学习环境(ALE)被用于对比不同的控制器算法,从深度 Q 学习到神经进化算法。Atari 游戏的环境在一个通用界面上提供了大量不同任务、可理解的奖励度量和令人兴奋的研究领域,且它所需的计算资源相对有限。无怪乎该基准套件得到了如此广泛的应用。
Atari 领域中的一个困难在于使用纯像素的输入。尽管与现代游戏平台相比,Atari 的屏幕分辨率不算高,但处理这类视觉信息对于人工智能体来说仍然是个挑战。人们使用目标表征和像素缩减方法,将该信息压缩成更适合进化控制器的形式。这里深度神经网络控制器表现更加优秀,原因在于卷积层和在计算机视觉领域的长期应用。
笛卡尔遗传规划(Cartesian Genetic Programming,CGP)在计算机视觉领域的应用也有很长的历史,尽管比深度学习稍微短了一些。CGP-IP 能够创建图像滤波器,用于去噪、目标检测和质心定位(centroid determination)。在强化学习任务中使用 CGP 的研究相对较少,本论文将展示首次使用 CGP 作为游戏智能体的研究。
简单而言,笛卡尔遗传规划是遗传规划的一种形式,其中程序表征为有向的、通常由笛卡尔坐标索引的非循环图。其中功能性节点通常由一组进化的基因定义,并通过它们的坐标连接输入与其它功能性节点。程序的输出由任何内部节点或程序输入基于进化的输出坐标得出。
ALE 提供了 CGP 和其他方法之间的定量对比。直接将 Atari 游戏分数与之前研究中的不同方法结果进行对比,以对比 CGP 与其他方法在该领域的能力。
CGP 的独特优势使得其应用在 ALE 上非常合适。通过定长的基因组,小型程序能通过进化生成并被读取以理解。虽然深度 actor 或进化神经网络的内部机制可能难以了解,但 CGP 进化的程序可以让我们深入理解玩 Atar 游戏的策略。最后,通过使用用于矩阵运算的函数集,CGP 能够仅使用像素输入而不使用先验游戏知识,在多种游戏上实现与人类相当的性能。
论文:Evolving simple programs for playing Atari games

论文地址:https://arxiv.org/abs/1806.05695
项目地址:hps://github.com/d9w/CGP.jl
摘要:笛卡尔遗传规划(Cartesian Genetic Programming,CGP)之前已被证明在图像处理任务中具备使用计算机视觉专用的函数集来进化程序的能力。类似的方法也可用于 Atari 游戏。使用混合型 CGP 和适用于矩阵运算的函数集(包括图像处理)来进化程序,但是允许出现控制器动作。尽管这些程序相对较小,但很多控制器的性能与 Atari 基准集的最优方法不相上下,且需要的训练时间更短。通过评估最优进化的程序,我们可以找到简单却有效的策略。
3 方法
尽管有很多在图像处理中使用 CGP 的案例,但在玩 Atari 游戏时这些实现必须进行修改。最重要的是,输入像素必须通过进化程序处理以确定标量输出,这需要程序减少输入空间。本研究选择的方法可确保和其它 ALE 结果的可比较性,同时鼓励有竞争力且简单的程序的进化。
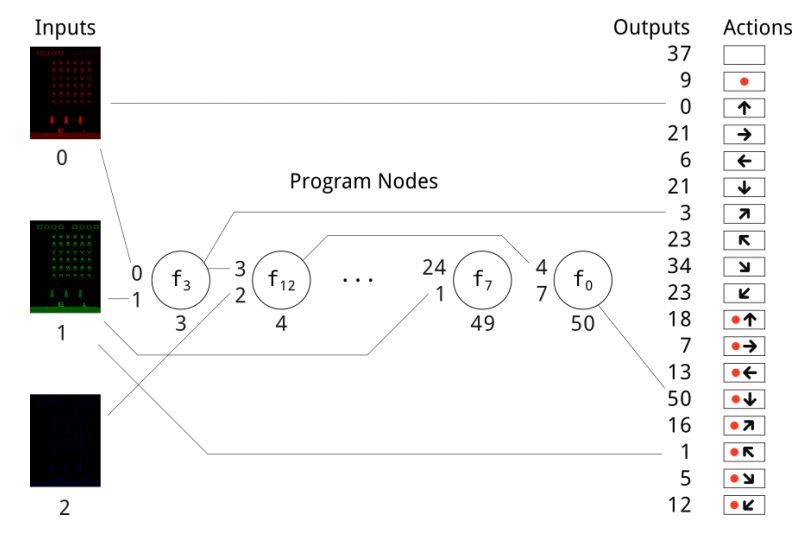
图 1:使用 CGP 来玩 Atari 游戏,蓝色像素矩阵是进化程序的输入,进化的输出决定最后的控制器动作。这里展示了所有控制器动作,但大多数游戏仅使用可用动作的子集。带红色标记的动作表示一个按钮。
4 结果
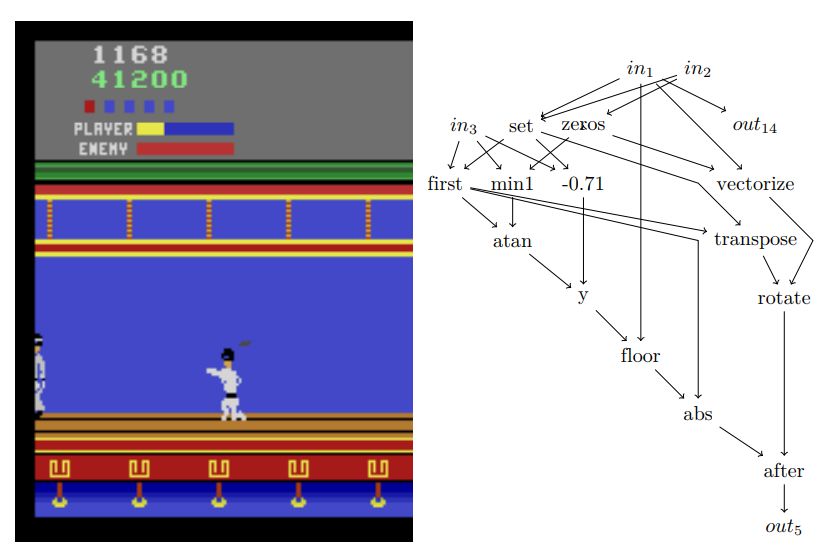
图 2: Kung-Fu Master 游戏的蹲伏方法和玩家功能图。为简洁起见,这里忽略未激活的输出和导致这些输出的计算图。
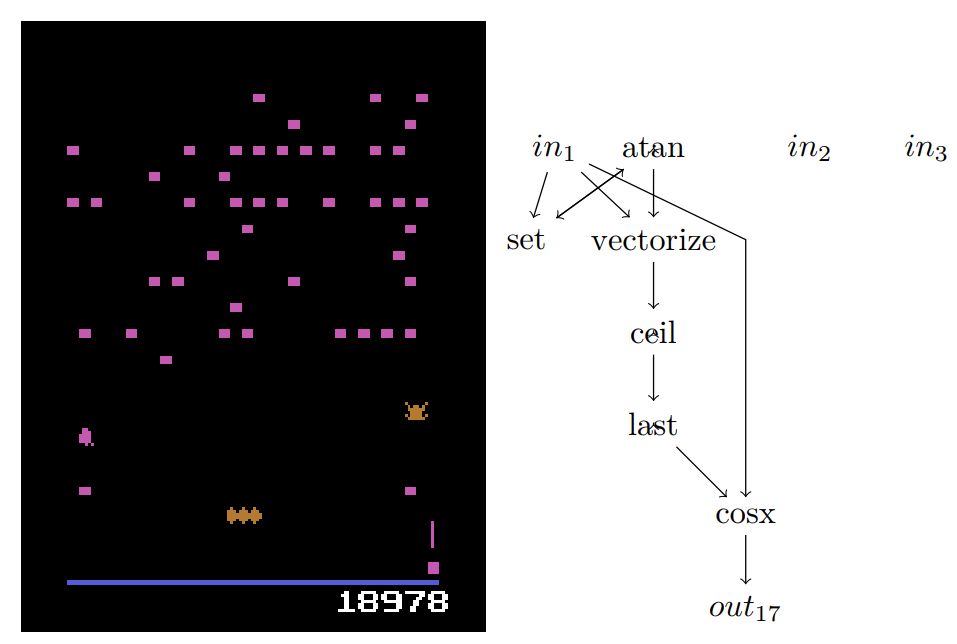
图 3:Centipede 玩家,仅激活了输出 17,下-左-开火。所有其它输出导致空值或恒定零输入,此处未展示。
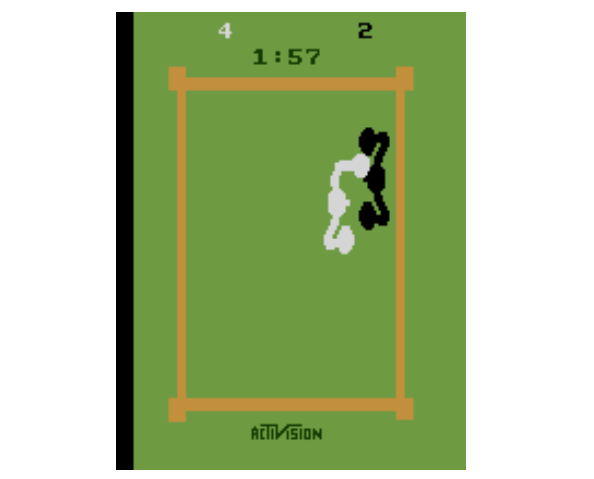
图 4:Boxing 游戏,使用像素输入来连续移动和采取不同动作。这里,CGP 智能体通过不断打击 Atari 玩家来缓慢移动,将 Atari 玩家逼到围绳处。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


