干货 | 算法工程师入门第二期——穆黎森讲增强学习(二)

雷锋网(公众号:雷锋网)按:大牛讲堂算法工程师入门系列第二期-穆黎森讲增强学习(二),上一讲内容主要涉及增强学习基本概念及Deep Q Learning的相关内容,本讲除了Deep Q Learning的相关拓展内容、DQN和近期的一些进展。

Beyond Deep Q Learning
DQN将一个强大的工具deep neural network 引入RL,解决了这中间遇到的很多新问题,收到了很好的效果。自从这篇工作以后,一方面,大家希望更强的工具能解决更难的问题,比如上面DQN还玩的不是很好的游戏,或者游戏之外的问题;另一方面,大家也希望已经能够解决的问题能做得更好,更快。近两年,学术界和工业界做了很多工作,不断将RL的效果和性能推到新的高度。不论是学术界还是企业界,都认为RL的潜力是很大的。但是在什么时候,能够以一个合理的代价解决一个现实的应用场景,这个问题目前还处在探索之中。
在这个探索的过程中,最重要的一步,是如何发现现有算法方案的缺陷和短板;其次是以什么样的思路去解决它;然后是算法的实现与工程细节。这一节中,重点是前两个方面,特别是第一个:DQN之后,大家都是从什么样的视角,去不断改进RL算法的效果的?
连续动作问题
下面是DQN的一个示意图。
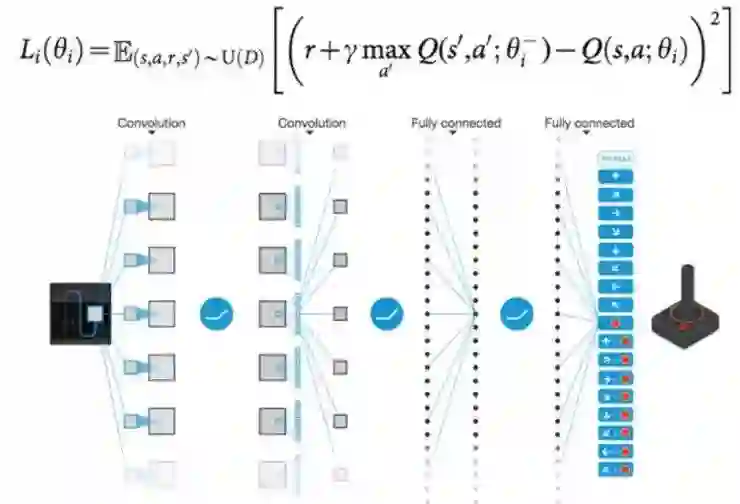
可以看出,这种形式的网络结构以及loss function的定义,只能处理离散action,即策略需要从N个action中挑选一个的情况。在实际的应用场景中,很多时候,action是多维连续的值,比如机器人控制中各个电机的控制量。在连续action维度非常低的时候,我们可以把连续的值离散化成为几个区间,然后按照离散action处理;但在action维度较高的情形,这种方法就不适用了。这个时候,显式的值函数就只能将state,action作为输入,而无法同时输出所有action对应的Q值。
所以,我们需要显式的策略函数:α=π(s) or π(α|s)
接下来要介绍的两个方法中,既使用了显式的值函数,又使用了显式的策略函数,它们可以被归类为actor critic 方法:
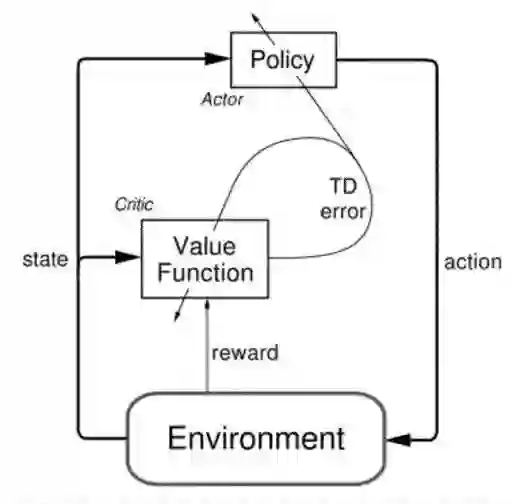
随着训练的进行,value function 和 policy 都会得到更新:value function 一般会根据temporal difference迭代更准确的Q值(或者V值,称为状态价值state value;相对的,Q为动作价值action value);policy function会根据value function 以及从环境中收集到的trajectory,迭代更新更好的策略。
Deterministic Policy
第一种思路,策略函数形式为:α=π(s)
也就是确定性的策略。这个方法称为Deterministic Policy Gradient(DPG)其策略函数输出一个确定的action,这个action可以是高维连续的。其网络结构示意为:
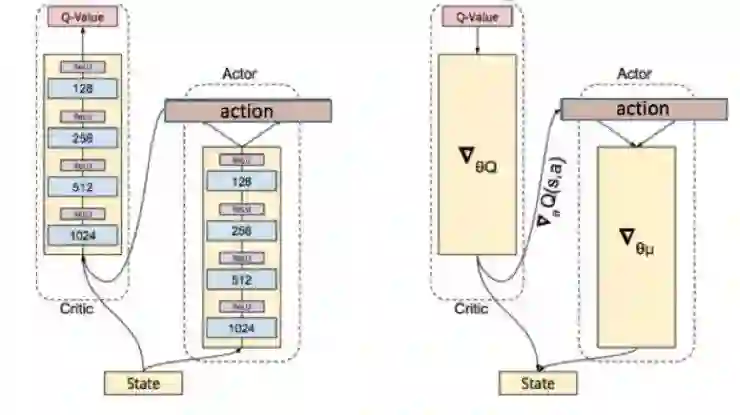
Q网络,即值函数部分,训练的更新依然通过通过TD loss 来更新;π网络,即策略函数部分,其更新的梯度方向为使得输出的action对应的Q值变大,也就是说,loss function为 -Q。具体证明过程在此不展开了。
Stochastic Policy
第二种思路,策略函数形式为:π(α|s)
也就是随机性策略。对于随机性策略,Policy function应该输出action的概率分布。对于连续的action来说,Policy function可以输出action的概率密度函数。所以,假设action的分布符合多维正态分布:
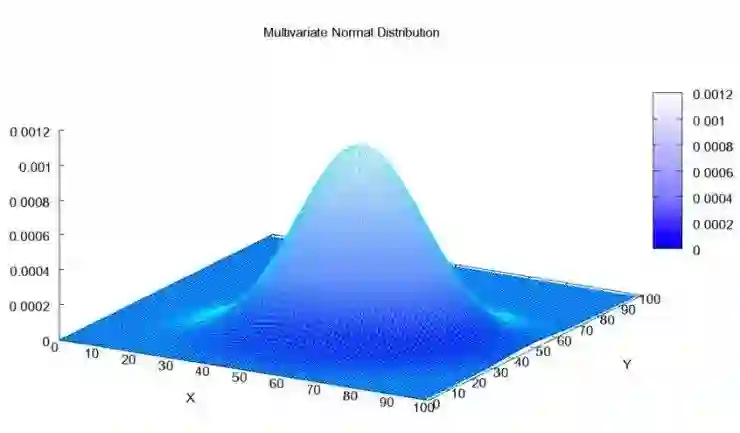
那么,策略网络可以输出正态分布的均值和方差来代表这个分布。于是,关于策略梯度的更新方法就都可以应用在这个策略函数上:只要能构造一个loss function,使得“更好”的action对应的概率密度变高,“更差”的action对应的概率密度变低就可以了。
Action的概率分布符合正态分布这个假设,可以说是一个很强的假设。但是在实际使用当中,这个假设下,在不少问题中是可以得到还不错的策略的。这个方法在Asynchronous Advantage Actor Critic(A3C)这个工作中有提及,关于A3C,后面还会有介绍。
更好的模型结构
既然使用了model来近似表示希望获得的策略/价值函数,那么我们总是可以问的一个问题是:有没有更好的模型来解决我的问题?
在这之前,得首先回答一个问题:什么叫更好的模型?
关于模型(model),有三个互相关联的特性:
· Non-Linearity,非线性。通常我们希望拟合的真实函数,其输入到输出的对应关系是非常复杂的,或者说,具有非常大的非线性。所以模型的非线性是否足够,决定了最终拟合的结果误差可以有多小。
· Capacity,容量。即模型的自由度。自由度越高的模型,能拟合的函数的集合就越大,但同时因为搜索空间的变大,训练的代价就越大;自由度越低的模型,能拟合的函数的集合就越小,相应的,训练的代价也会变小。
· Computation Cost,计算代价。计算越复杂的模型,其使用以及训练所消耗的计算资源也越多。
通常情况下,以上三个特性是成正比的。例如,如果对某个神经网络增加其层数,那么其非线性会增加,可以表示更复杂形状的函数;其次参数量会增加;最后,其计算代价也会上升。
但是,如果有可能,我们总是希望模型能够更准确的表示真实函数的同时,尽量不要增大搜索的空间,以及计算复杂度。翻译一下,就是在增加non-linearity的同时,可以相对减小capacity和computation cost。
如果能面向要处理的问题的特点,有针对性的设计模型结构,是有可能做到这一点的。这就是所谓“更好的模型”。
那么,在RL中,要解决的问题有什么特点呢?以下,举几个这方面的例子。
LSTM的应用
我们知道,RNN或者说LSTM,是具有一定的记忆能力的,适合于处理序列的输入情况。例如语音识别、机器翻译等领域,LSTM被用来处理语音、句子等序列输入;或者在计算机视觉(CV)中,用来实现attention 机制,即网络需要的输出只和输入图像的一部分关系密切的情形。
而以上两点,在RL中,都存在相似的情形:
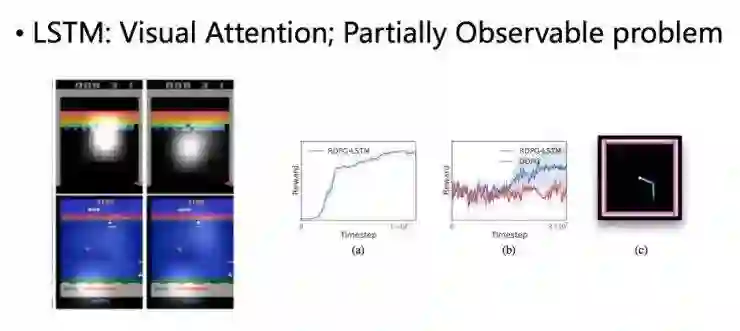
例如,在游戏任务中,通常对策略决策比较重要的信息都来自于屏幕上很集中的部分区域。
例如,RL agent和环境交互的过程本身就是个序列过程,而很多时候,agent只能接收到环境的部分信息;agent的当前决策需要依赖于若干步之前收到的信息。这种情况被称为Partially Observable problem,形式化的描述是可以用LSTM将partially observable markov decision process 转化为fully observable markov decision process,在此不做展开。
其中,上面第二点可以说是很多RL问题的共性,因此应用也更加广泛。
Dueling Network
LSTM可以说是其他领域成功应用的模型结构,应用在RL中应对类似问题的例子。那么,在RL中特别是value based method中,神经网络是用来拟合值函数Q的。值函数Q有没有什么特有的结构可以被用来设计模型呢?
设想一下:在学习骑自行车这个任务中,假设agent所处的状态是轮胎与地面成30°角。可以想象,无论这个时候agent采取什么action,多半都会收到一个很糟糕的reward:摔倒在地面上。这里,一个直觉的推断是:在很多问题下,Q值的一大部分由输入的state决定;在此基础上,不同的action会造成小部分的差别;另外一方面,对于策略来说,Q之中仅由state决定的这部分没有什么作用,更重要的是不同action之间的差别。
这就是Dueling Network的思路:把Q网络的结构显式地约束成两部分之和。
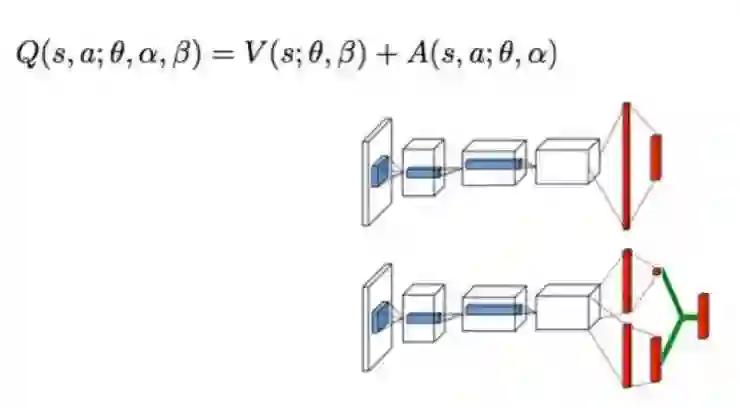
这样,V的部分只依赖于state,训练起来更容易;不同action之间的差别只体现在A部分,这部分通常被叫做action advantage。这部分的收敛也可以与V独立开来,使得action之间的相对差别可以独立学习。
关于Q值函数形状的约束假设,还有更激进的工作如NAF(Normalized Advantage Functions),在此不做展开了。
Value Iteration Network
Dueling Network可以说是利用Q值函数的形状特性。那么Q值迭代的计算过程,是否有特性可以利用呢?
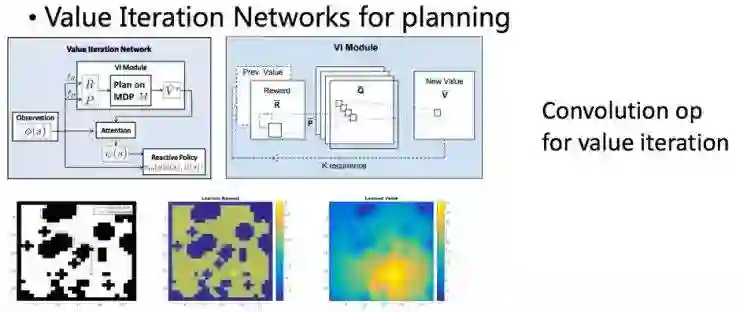
Value Iteration Network这个工作的思路正是如此,其利用了Q值迭代过程和convolution/max pooling 过程形式上的一致性:二维平面状态空间下,假设每个状态只能转移到和其相邻的状态中,那么根据bellman equation对平面内所有状态做一次值迭代的过程,就可以表示成在这个二维图上的一次卷积操作。这样,通过若干轮卷积,网络可以提取出若干步后的所有状态的Q值,这种look ahead 的行为正是规划(planning)所需要的。所以,VIN可以用来实现带规划功能的策略函数。算法的其余细节不再展开。
更快的收敛速度
我们先比较一下增强学习(DQN)和监督学习的loss function:

可以看出,两者的loss function 形式上有一定的相似性,都是让模型的输出趋近于一个目标值(图片中红色的部分)。
对比可以看出,DQN的训练过程有如下几个特点。
第一,基础事实(ground truth)非常稀疏。原因来自于两方面:
首先,对于不同的任务来说,环境给出的r的密度不一样,有些任务的r可能会很稀疏,甚至于只有在任务最后成功/失败的时候才会有非零的r,其余时候r都是0。
其次,监督学习的loss function中,目标值完全来自于外界输入的正确信息,也就是ground truth。而DQN的loss function中,目标值只有r的部分来自ground truth,另外一部分来自于前一版本的网络的输出Q值,这只是一个真实值的近似。
第二,对目标Q值的估计存在偏差。这个偏差正是来自于上面所说的前一版本网络输出的Q值上:网络训练的过程中,其输出和真实值可能差距较大;其次,在不准确的Q值基础上应用操作,会导致估计的Q值系统性地偏大。
第三,DQN这个loss也被称为1 step TD loss,也就是说,在s’处估计的目标值沿着trajectory倒推一步s’处,用来更新s处的Q值。这样,transition中<s,a,r,s’>所蕴含的ground truth需要很多轮迭代才能传播到离和更远的地方去,得到比较精确的Q值。以下几个工作,就是针对上面说到的DQN的收敛性问题所做的改进。
Prioritized Experience Replay
在某些任务中,既然对训练有价值的reward比较的稀疏,那是否可以着重利用这些采集到的reward呢?Prioritized Experience Replay就是基于这个思路,从replay中采样的时候,提高训练的时候loss高的transition被采样到的概率,从而更有效率的学习。
Double DQN
这个工作对目标Q值的计算做了如下的修正:
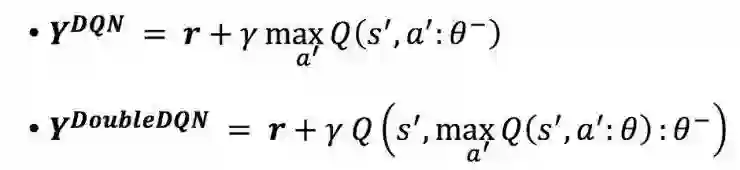
使得对目标Q值的估计偏高的问题得到了改善:

Optimality Tightening
前面提到DQN的一个问题是1 step td loss在state空间中传播ground truth太慢的问题。事实上,DQN属于值方法,而很多策略方法是可以利用N step TD的。为什么DQN不能用呢?因为N step TD是从序列:[r[t], r[t+1], …, r[t+i]] 计算而来,而从replay buffer中提取出来的trajectory序列可能是根据比较早版本的Q网络生成的,这就无法真实的反映出最新的target Q网络的表现情况。而单步td只关心r,而不用关心r的序列,所以不用担心生成这个序列的策略和当前策略不一样的问题。更详细的分析可以去了解一下on-policy和off-policy的相关概念。
Optimality Tightening 这个工作的思路是,虽然不能直接用N step TD来计算当前的目标Q值,但是用来给当前Q目标值加一个上下界的约束:
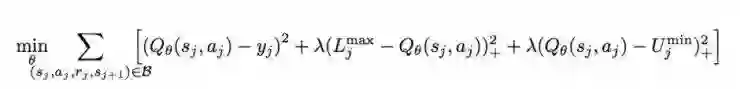
这样,相当于在DQN里面,应用上了N step TD的信息,让ground truth 沿着trajectory的轨迹传播得更快。
更好的探索策略
探索是RL的重要话题。想象人类学习玩游戏的过程,在游戏的开始,玩家会尝试一些操作;并逐渐掌握一些基本的策略,完成简单的挑战;然后根据这些策略,达到离初始状态较远的状态,然后不断探索尝试面临的新的挑战。在RL中也是如此,一方面,策略需要保持一定的探索以发现新的策略;另一方面,策略需要利用之前学到的知识,才能保证探索的时候更有效率。
在DQN中,?−??????方法是一种比较基础的探索策略,是在greedy策略(选取Q值最大的action)基础上,以一定比例加入随机选择的action而来。通过调整?的大小,可以控制随机探索与应用现有策略之间的比例。
但是,在稍复杂一些的问题下,?−??????是一种比较低效的探索方法。因为很显然,在?值也就是随机的比例一定的情况下,Agent到达某个状态s的几率,随着s离初始状态距离的增加是成指数级降低的。我们需要除了简单的随机策略以外,更加有效的探索方式。
Intrinsic Rewards
既然RL的训练过程会让agent的策略倾向于尽可能多地收集累积回报,那我们是不是可以自己构造回报函数,来指导agent的探索呢?
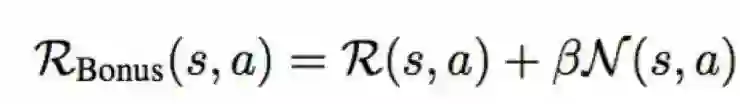
这是一种比较通用的办法。即在agent收到的环境reward之上,加入自己设计的intrinsic reward,指导agent趋向于这个reward所指引的方向。至于如何构造这个intrinsic reward,不同的工作有不同的思路,这里仅举一个例子:
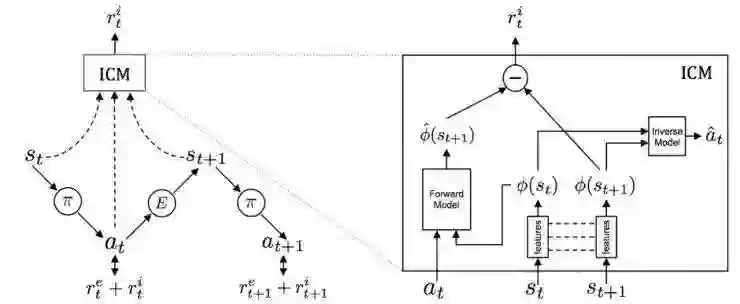
即构造一个专门的网络来预测环境的transition model;这个transition model跟着策略/值网络一起训练,只是以更慢的学习速度进行。那么这个transition model预测环境变化的准确度高的state,就认为agent已经很熟悉这个state了;反之,就认为这个agent对当前所处的环境不是很熟悉。所以,就是用transition model的training loss 来当做intrinsic reward。这个training loss的方法被形象地称为Curiosity Driven Exploration。
Deeper Exploration
前面提到,简单的随机策略会让agent很难到达离初始状态较远的状态,就像布朗运动很难远离原点一样。这样的探索是一种很“浅”的探索,那如何让探索更深呢?直观的想法是减少随机性,以避免在初始状态原地打转的情况;但随机性太小的话,又会导致agent采集到的transition趋同,不利于训练。如何来平衡这两点呢?
假设有一个团队来执行探索迷宫的任务。其中A喜欢贴着右边墙走;B喜欢贴着左边墙走。那每次探索,团队都派不同的人出去执行任务,是不是就可以实现每个人都深入到迷宫的不同部分了呢?
Bootstrapped DQN这个工作所采取的思路是这样的:
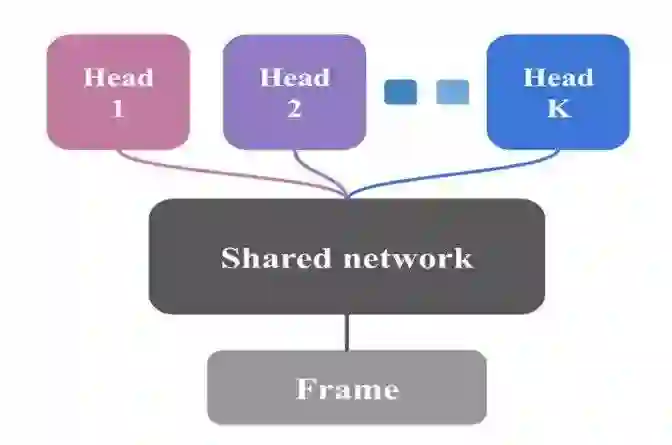
每个head都是一组Q值;每个Episode仅根据一个head的Q值做greedy的探索,直到下一个Episode,再随机选取一个head执行探索。这样,每个episode都会依据某一个head的策略执行到底,保证了探索的一致性和深入;同时,只要能保持不同head之间的多样性,从统计上来看,探索得到的transition也比较多样化。
Hierarchical RL
我们知道,人是有比较强的信息抽象能力的。对于数据的抽象,深度的神经网络也具备相似的能力,可以从高维度的、低层次的输入数据(比如图像),提取出低维度的,高层次的信息(比如图片里有一只喵的概率)。但是对于行为来说,人同样是具有很强的抽象能力的:可以从高维度、低层次的行为的基础上,逐渐建立出低维度、高层次的行为。
举一个例子,需要完成的任务是通过键盘猜测两位数的密码。正常的人类在完成这个任务的时候,其实际需要探索的状态空间只有10²个状态,也就是两位数密码的所有组合;而按照普通的RL方法,agent输出机械臂的所有控制信号来敲键盘的话,其探索的状态空间是一个大得多的高维空间。
这就是层次式RL:Heirarchical RL的出发点:把策略(或者动作)本身划分为不同的层次,底层的策略负责完成一些底层的任务;上层的策略负责把底层策略结合起来,完成更复杂的任务。这样,无论上层策略还是底层策略,其探索空间都大大减小。
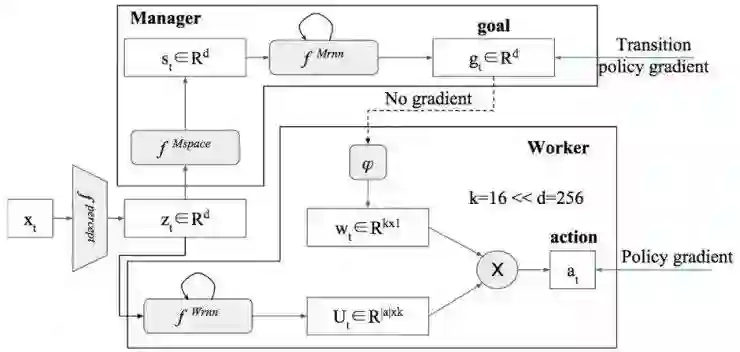
通常,Heirarchical RL会把策略分为至少两层,上层的策略负责输出底层策略的阶段性目标,称为goal或者option;然后底层策略在一定的时间周期内,负责实现这个目标。上层策略可以在此期间,负责输出reward给底层策略,用来评价底层策略的执行情况。
属于这类的工作有很多,在此就不一一举例了。
向专家学习
在RL的框架下,agent可以从零开始,探索环境,逐渐学习得到越来越好的策略。由于前面提到的各种原因,对比监督学习来说,RL是个相对较慢的过程。
反观人类学习某项任务的过程:人类具有很强的模仿能力,如果在学习的过程中,有老师示范的话,人类的学习速度将会大大提升。那是否可以让RL中的agent,也能像人类一样,从专家的行为中学习呢?
一个传统的思路是Inverse RL:给出专家在完成任务的一些例子,先对环境的reward做出假设:R(s, a);然后设法求出使得专家的例子收到的奖励最大化的R(s, a),再反过来用R(s, a)指导agent的训练。通常这样的R(s, a)返回的奖励是比环境本身的奖励要更稠密的,所以在R的指导下,agent学习会更快。
这种方法比较间接。还有更直接的做法:imitation learning,即设法让agent的策略输出和专家的输出更接近。Imitation learning也有很多做法,这里就举一个例子:
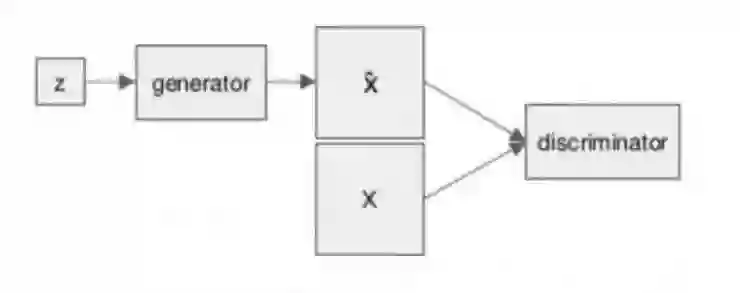
熟悉深度学习近期进展的同学能看出来,这是一个对抗学习(Generative Adversarial Network,GAN)的结构。在Generative Adversarial Imitation Learning这个工作里面,通过对抗学习,使得generator也就是policy输出的trajectory的分布,尽量靠近专家的trajectory 的分布。然后可以再放进RL的框架下,进一步学习得到更好的策略。
分布式算法
RL的训练过程是很慢的。一个很花时间的程序,设法改成分布式以加速,是个很自然的想法。
那么,RL训练过程中,哪些部分可以并行化呢?
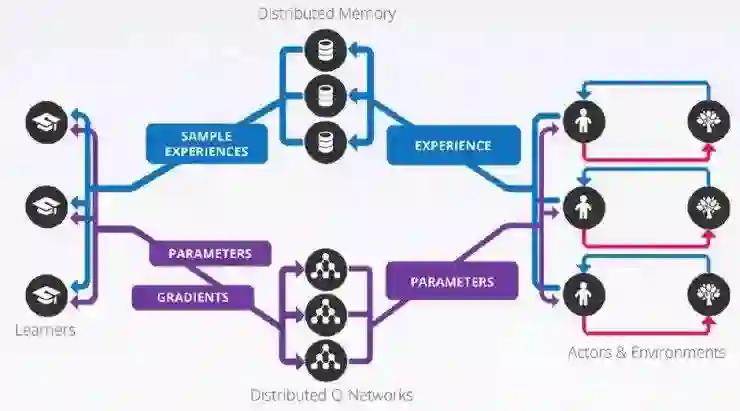
GORILA
上图来自于Google Reinforcement Learning Architecture(Gorila)这个工作。我们会发现,只要有需要,RL过程中的各个部分皆可并行化:
· Environment:不同的环境实例之间相互独立;
· Agent:Agent与environment一一对应,只与自己的environment交互,所以也可以并行;
· Replay Memory:当需要存储超过单机容量的replay的时候,可以用多机存储; learner, parameter, agent。
· Learners:不同的learner可以独立地从experience replay中采样数据并计算梯度,类似于监督学习中的数据并行;
· Parameters:如果网络规模比较大,那么可以用多机来保存和更新网络参数,类似于监督学习中的模型并行。
A3C
如果系统的部署规模还没有到google这么大,那么Asynchronous Methods for Deep Reinforcement Learning这个工作比较值得关注:
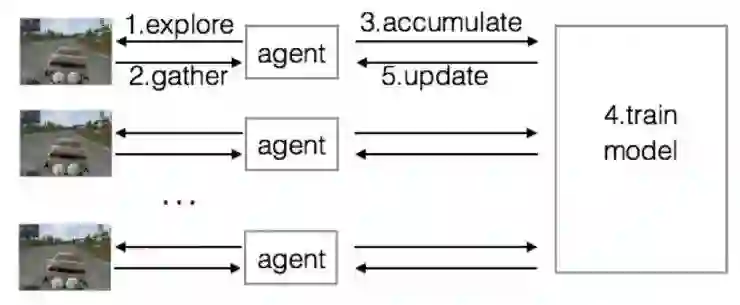
从架构上来说,比Gorila要简单。细节先不展开了,这里有一个比较有意思的结论:
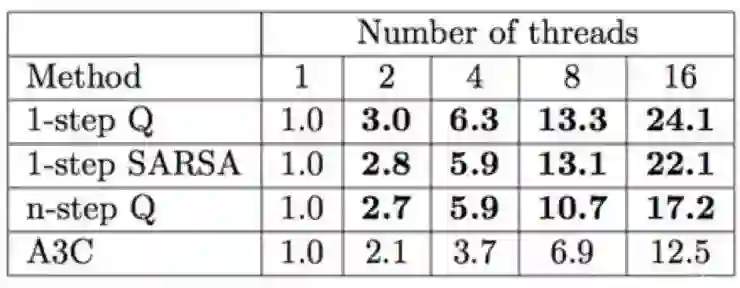
我们看到,当把单机的算法改成分布式之后,有些算法获得了超过1的加速比。这个在分布式计算中并不常见,因为单机的算法很可能有一部分是没法并行化的,同时并行化还带来了通讯和调度的开销。
原因在于,多个agent同时探索,往往会探索到environment的不同状态。这样,在训练的时候,采样得到的训练数据之间相互的独立性会更强。所以分布式训练除了利用了更多计算资源以外,对RL而言对于训练时候的样本独立同分布还有额外的好处。
文中提到的asynchronous advantage actor-critic, A3C算法是一个效果比较好的算法,值得感兴趣的同学关注一下。
多任务和迁移
迁移学习不是一个新的话题。模型的训练是一件花时间的事情;人们希望训练好一个模型以后,能让这个模型能完成不同的任务,或者至少对训练其他任务的模型有所帮助。在RL的领域,多任务和迁移的话题变得越来越重要,原因包括:
· 在现实的场景中,agent需要面临的情况是很复杂的,可能不时会有新的情况发生;如果能让agent学会处理新的情况速度大大加快,无疑是很有价值的。
· 我们知道,虚拟的Environment的执行和探索的成本很低,而在真实的物理世界里探索成本非常高。但是通常,虚拟环境和真实环境总会有一些差异。如果能有办法帮助在虚拟环境里训练好的agent更快地适应真实环境的话,就可以让在虚拟环境中训练、在实际场景下使用变得更加容易。
· 即使是完成单个任务,任务本身可能也有一些结构值得探索,就像在Hierachical RL一节所思考的一样。那么,将多任务的一些方法应用在单个任务的训练中,也可以起到加快训练的作用。
Target Driven Navigation
有一个完成单一任务的程序,现在想让它能完成更多任务?
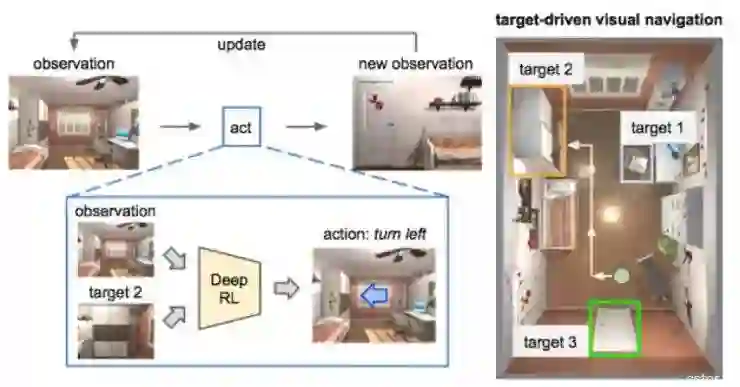
从软件工程的角度,最直接的办法是把要完成的任务,也当成程序输入的一部分。这也是Target driven visual navigation in Indoor Scenes using deep RL这个工作的思路。
Progressive Neural Networks
上述方法要求任务之间具有比较强的一致性。如果还是希望分别训练多个网络对应多个任务呢?
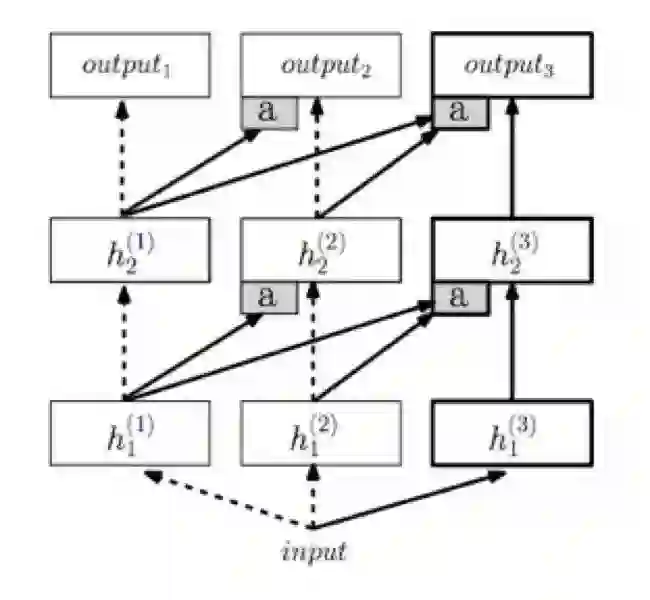
这篇工作的思路是,让已经训练好的网络也参与到新的任务网络的训练过程中:因为已经训练好的网络所具有的信息抽取的能力,可能对新的任务有一定的参考价值。
Elastic Weight Consolidation
那么,是否真的就不能让同一个agent或者说网络,具有完成多个任务的能力呢?

从训练的角度来讲,一个神经网络在两个task下表现好,就意味着这个网络的参数对于两个task对应的loss 都比较低。也就意味着,在训练好task A以后,在训练task B的时候,希望能保留对task A重要的参数,只改变对task A不重要的参数,来寻找能完成task B的策略。参数对task的重要程度,正好有个直接的衡量标准:即训练这个task的时候,loss对参数的梯度。这样,只要调低对task A重要的参数的学习率,就能让网络不会“忘记”task A。
RL with unsupervised auxiliary tasks
如果是人类来学习完成某项任务的话,人类不会仅仅习得在某种state下应该执行某个action,而是会逐渐掌握这个任务的环境的一些一般规律,并利用这些知识,更快地习得更鲁棒的策略。
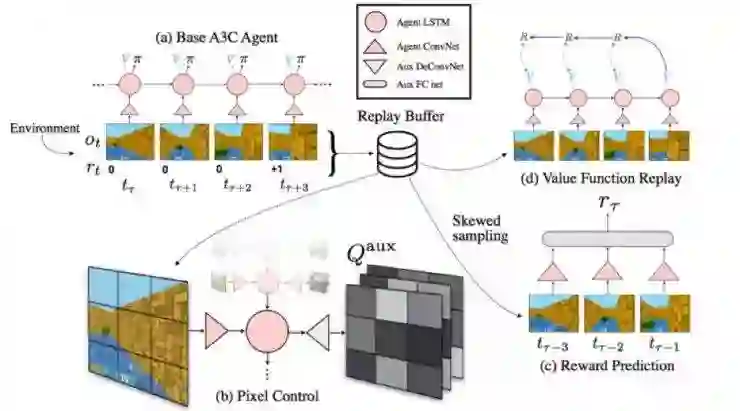
在这个工作中,除了主要的训练流程之外, 还加入了几个辅助的任务,来预测收集到的reward、迭代值函数、控制像素的变化情况,等等。这些辅助的任务和主任务之间,共享一部分网络机构。一个很合理的直觉是:一个能很好从环境中预测收到的reward的网络,它从state中提取出来的信息也对完成这个任务非常有用。
Curriculum Learning
人类在学习某项技能的时候,如果先从简单的情形开始学起,循序渐进提高难度,那么学习很容易很多,这就是所谓的学习曲线。相同的思路应用在RL上,就是课程表学习:

以上是个玩射击游戏的例子,不同的class 实际上是不同难度的同一个任务。Class 0是最容易的,意味着更容易收集到有意义的reward,所以训练起来比较容易;能顺利完成class 0的agent,相比未经训练的agent来说,在class 1里面收集到reward的难度要低,所以训练起来也比较容易,以此类推,就能逐渐完成我们最终设定的任务。
后记
可以看出,上述的各种进展,是用新的手段,解决更复杂的任务,同时不断定位问题并解决改善的过程。由于篇幅和角度所限,不少近期的进展并没有覆盖到;同时,上述所有的工作所声称要解决的问题,还远未达到解决得很好的程度,他们各自起作用也有一些假设和作用范围,所以这些问题都还是开放性的话题。相信不久的将来,RL的进展会体现在更多的实际应用场景中,甚至催生出很多新的产品形态,这也是学界和业界共同努力的方向,让我们拭目以待。

媒体合作请联系:
邮箱:contact@dataunion.org


