“表情移植神器”上线,我家爱豆的面瘫演技是不是有救了!
作为一个有底线的颜控,追剧总是很烦恼:那些好看的小鲜肉小鲜花,演技大多不咋样。有些粉丝甚至会想:可不可以把戏骨的演技嫁接到全程“瘫痪”的爱豆身上?这听上去太难了吧。
不过最近,发明GPU的公司核弹厂英伟达(NVIDIA)发布了两项重磅技术,让这个有望实现了。一个技术是上个星期发表的与MIT联合研究的“视频-视频合成”技术(video-to-video synthesis,下文简称vid2vid)。

图 | 参考资料1
另一个是礼拜一德国发布会上黄仁勋(Jensen Huang)重磅推出的新一代“图灵框架”卡皇 RTX,实现了实时光线追踪(Real-time ray tracking)技术。

图 | 官方发布会截图
被黑科技闪瞎双眼的吃瓜群众们瞬间脑洞大开:这两个堪称“表情移植神器”和“实时渲染怪力圣器”的家伙,是不是可以让影视特效技术大飞跃、能让流量明星从此年产无数部高质量抠图剧呢?

现有的抠图 | 《孤芳不自赏》
vid2vid:由视频合成视频
/*
别走,这段强行科普后面有新垣结衣!
*/
NVIDIA与MIT的联合研究团队发表的这篇文章名为《视频-视频合成》(Video-to-Video Synthesis),顾名思义,就是从一个原始输入视频,经过合成处理,输出一个新的视频。
输入的内容主要有两个:一个是主体视频,叫做“语义图”(semantic maps),我们可以把它看作是视频动作的“骨架”;另一个是“现有图像”(past images),我们可以把它看作是视频内容的“皮肉”。
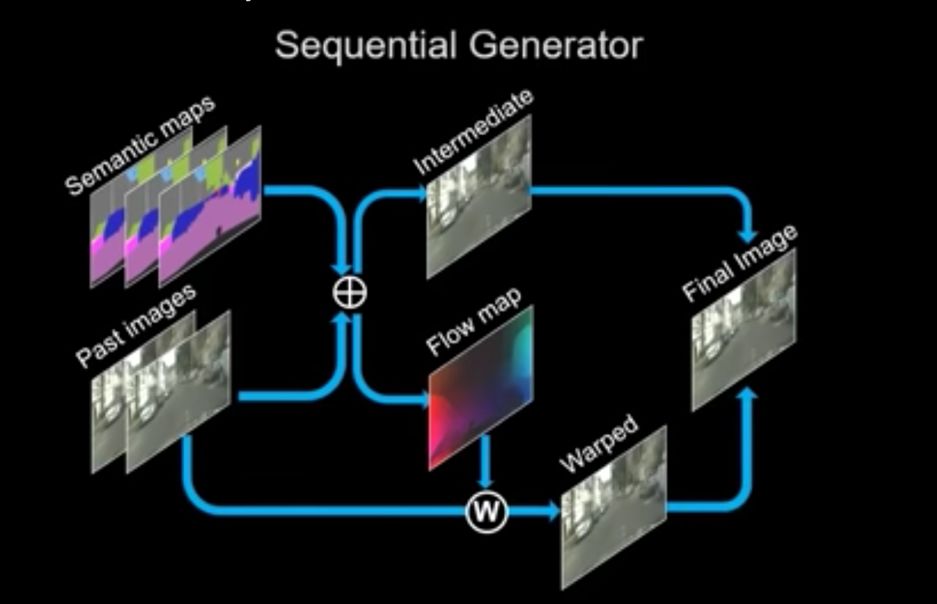
图 | 参考资料1
语义图和现有图像作为原材料,喂进了一个叫做“顺序生成器”(sequential generator)的模型当中,输出两样东西:“中间帧”(intermediate frame)和 “流谱”(flow map )。“流谱”被用来使“现有图像”产生变化,变化后的图像与“中间帧”结合生成“输出图像”(也可以叫做“输出帧”,毕竟,常识告诉我们,视频是一帧一帧的画面连接起来的)。这个“输出图像”,被迭代进模型,作为下一次运算输入的“现有图像”。
此外,还有两个“鉴别器”——“图像鉴别器”(image discriminator)和“视频鉴别器”(video discriminator)。它们被用来评估每一帧画面中的各个特点,以及时间上的连续,来确保输出视频的清晰度、逼真程度、以及时间一致性。
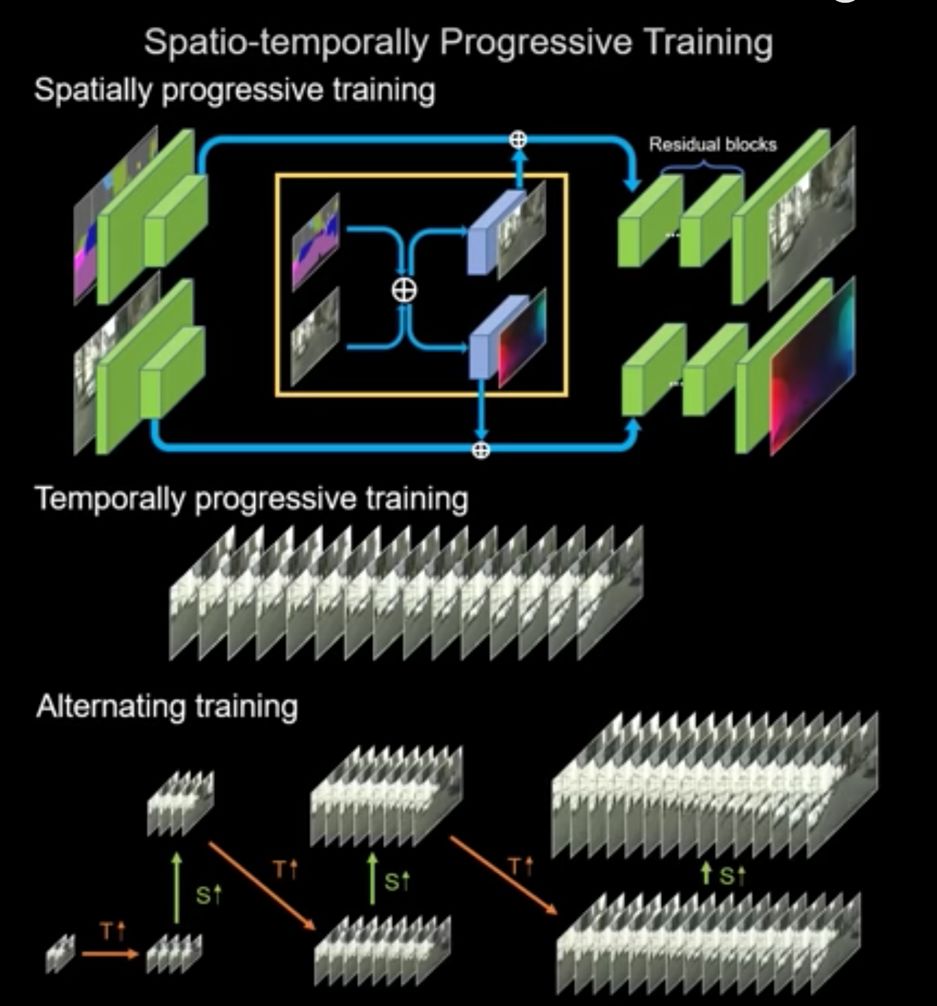
图 | 参考资料1
嗯,我猜大家并不想看这样👇
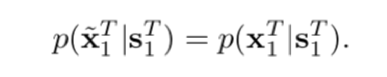
这样👇
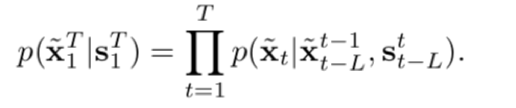
以及这样👇的模型
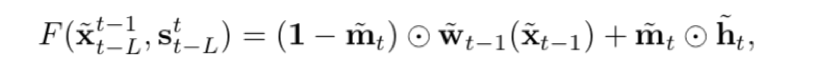
那我们来看视频。

图 | 参考资料1
在研究团队放出的视频中,作为“原材料”被输入的视频,也就是我们说的“骨架”,都是一些抽象的、表示动作的“语义图”。
比如这个👇

图 | 参考资料1
这段是从开放城市数据平台Cityscape上下载的街景视频,通过一系列算法处理成格式统一的“语义图”视频流。我国城市也有类似的信息,比如Apolloscape这个城市街景数据平台,目前就有73个关于北京的街景视频,在这个项目中被用作训练数据和检验数据。有兴趣的小伙伴可以点进去玩儿(复制右边的链接去浏览器打开 → http://apolloscape.auto )。
还比如这个👇
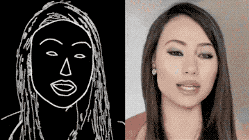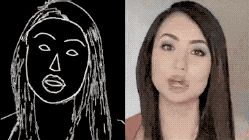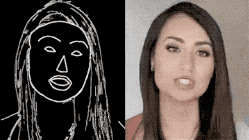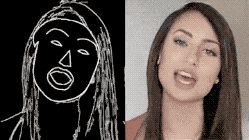
图 | 参考资料1
研究团队从FaceForensics这个有大量记者视频的数据库中搜集原始材料,通过一系列算法,提取出“颅面特征点”,进而生成“表情速写视频”。
动作信息,也是一样的,只不过换了几种算法。
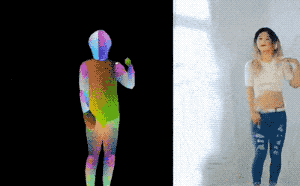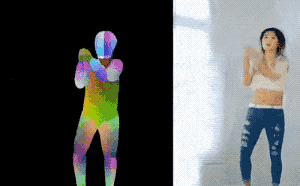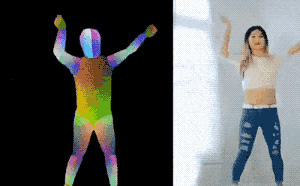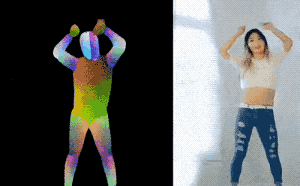
图 | 参考资料1
研究团队在视频讲解中说,这样“把一个人的舞蹈动作转移给了另一个人”(transform dancing motion from one person to another person)。研究团队给的demo,不知大家有没有认出来是新垣结衣在《逃避虽可耻但有用》里的那一段!

图 |《逃避虽可耻但有用》
/*
有了黑科技,手脚不协调的人也可以跳跟新垣结衣一样的舞!
*/
RTX:加速图形运算
NVIDIA老板黄仁勋手上拿的企图亮瞎所有观众的这款“神器煤气灶”RTX,号称世界上第一款光线追踪GPU,据说最大的特点是能到到“10 giga rays/sec ray tracing”,意思就是说每秒100亿的光线追踪。

煤气灶兄弟 | 左:NVIDIA官网;右:fang.com
/*
数字听上去很厉害,愣是mega,giga的数了好半天的零……
*/
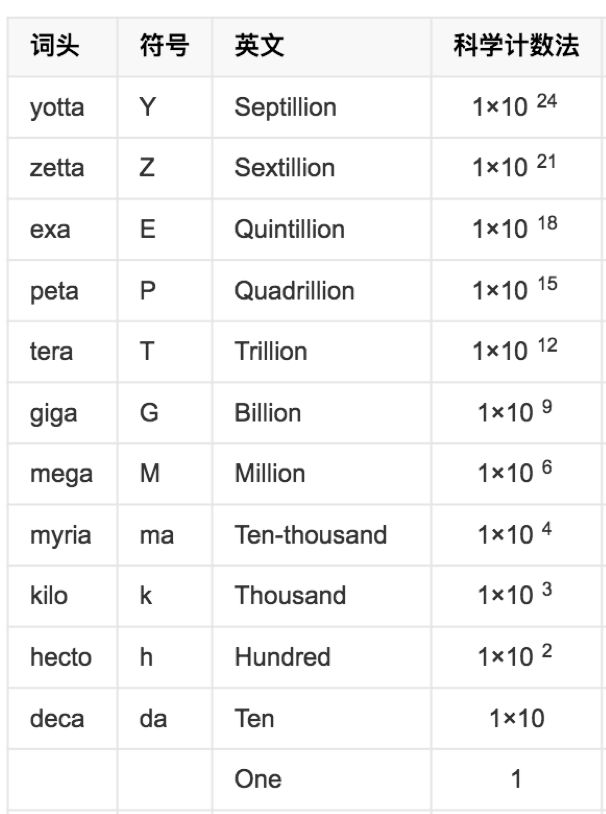
国际单位制前缀表 | 百度百科
要理解这个数字在描述什么,我们首先来了(ke)解(pu)一下我们经常听到、但是未必清楚的“渲染技术”到底是什么。
/*
敲黑板,阅读以下内容有利于向小伙伴们卖弄知识,简称装B……以及后面有更多爱豆图片!
*/
“渲染”用通俗直观的人类语言来说,就是把计算机里的三维模型(图中左边)经过仿真或抽象真实世界的物理过程来计算并呈现最终的视觉结果的过程,结果可以非常还原现实场景,也可以具有特殊的艺术风格。
如果作者被以上解释打脸了(因为好像并不通俗直观),那就看下面的图。左边为计算机中的三维模型,右图为经过渲染处理后呈现的视觉效果,科幻电影都这么做的,后期技术我们先不做讨论。

图 | techterms.com
用来实现渲染过程的计算机软件也叫做渲染器。早一些年代在电脑硬件技术还没有那么发达的时候,计算一张渲染图是非常耗时费力的,几乎要花费十几个甚至几十个小时,电影则是由每秒24帧的静帧渲染图来实现,可想而知是多么庞大的计算工程。
渲染是一个模拟过程,其对质量与效率的追求是一对矛盾:追求好的质量往往成倍增加花费的时间。因此,根据渲染的应用情况的不同,衍生出了很多不同的渲染技术,大体分为两类:静帧渲染和实时渲染。
静帧渲染追求画面质量的极致,例如各类好莱坞大片中的场景画面,概念产品的概念图,建筑设计的效果图;而实时渲染追求效率最大化,例如3D电脑游戏。随着硬件技术和GPU技术的提升以及渲染算法的进步,效果与效率的矛盾一定程度上被缓解。实时渲染也越来越接近静帧渲染的视觉效果,由于效率高,也越来越多地被应用到原先静帧渲染的领域,例如电影行业。

对ESTCube-1卫星的渲染 | Taavi Torim/Wikimedia Commons
那渲染这个“模拟”过程是怎么实现的呢?我们都知道(也不一定都知道,不过反正你们要知道),电脑中的三维物体我们俗称素模型(就是只有网格构成的形态模型),渲染的过程就是要模拟“素模”在真实场景下的视觉效果。
简单的说,就是把画有各种色彩或者信息的图按照某种映射规则(俗称UV)贴到素模型上,然后用场景中模拟的光线照射它们,最后通过模拟的摄像机抓住这些模拟的光线,来形成最终的视觉呈现。
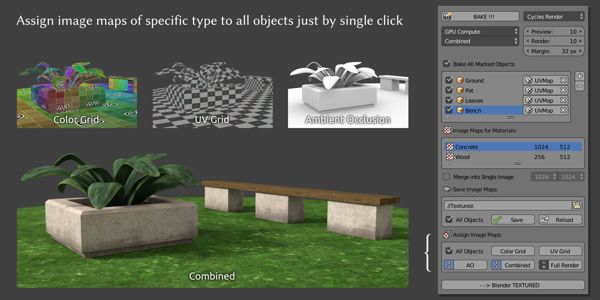
简单的UV映射 | MeshLogic
贴图技术和环境模拟的技术千差万别,这里不细说,不过大体原理就是这样。贴图一般分为非常多层,就像PS里的图层,每个贴图图层各司其职,有主管色彩的贴图,有主管纹理的贴图,有主管凹凸的贴图等等,贴图技术结合光线模拟以及相机或者摄像机的模拟的技术计算出最终的视觉结果,这就是一般的渲染实现过程。
RTX的厉害之处,我们可以通过一个侧面来了解,就是在场景中“模拟光线照射物体”。物体反射的光线越多,效果越真实。现在最牛的计算机,能够达到的是几十万级别的光线追踪,而RTX达到了100亿,中间差了多少个零大家慢慢数哈。
脑洞时间:这些能干嘛?
看完了技术,我们来开一下脑洞:这些技术能用来干嘛?
RTX的本质是大大提升了图形运算的效率,会使我们在现有技术上更快更好地得到相应的视觉产品。而vid2vid的脑洞空间则大得多!
比如,年纪大的演员不得不从少年时期开始塑造角色时,可以用自己的表情生成“骨架”输入视频,用自己年轻时的照片P上相应的妆容作为“皮肉”的“现有图像”输入,就可以避免很多尴尬了👇

直接输入13年前的图片作为“皮肉”输入,就不必尴尬地等消肿了 | 左:《橘子红了》;右:《如懿传》

当年45岁的陈宝国老师演出了18岁白景琦的少年神情,但是脸上嘛…… |《大宅门》
再比如,等到技术成熟了,也许影视公司可以每个角色请不同的演员拍一组定妆照,然后该角色只要捕捉记录一个演技超棒的戏骨的表演(神情、动作等)。这样就可以根据不同演员提供的“皮肉”图像输入数据,生成不同演员版本的影视作品。这避免了各家粉丝对选角不满互喷的状况,各买各家爱豆专辑版,从此天下太平。

女主看张曼玉、汤唯还是倪妮的版本呢?| 《花样年华》《色,戒》《金陵十三钗》

男主看胡歌、吴磊还是刘昊然的版本呢?| 《仙剑奇侠传》《斗破苍穹》《琅琊榜之风起长林》
对于没啥演技的小鲜肉小鲜花,也许“抠图”不再会被骂,反正大家都是合成的!
想想未来的影视作品真是激动啊:布景是假的,化妆是P的,声音是配的,表情和动作是别人的,小鲜肉小鲜花们只有脸是真的……等等,脸真的是真的吗?那我还看什么小鲜花啊,为什么不看合成的赫本的新片?或者更符合我审美的虚拟偶像呢?
/*
脑洞结束
*/
其实,目前能合成最长30秒的vid2vid技术,画质细节也有很大提升空间。

目前的画面仍有部分变形 | 参考文献1
但这是一类新技术的重大飞跃,会给我们带来无数新的可能。
《三体》中三体人在距现在100年后拍出了的足以以假乱真的地球人电影,而vid2vid技术可能在不远的将来就能实现科幻小说中强大外星文明的手段,我们拭目以待。

图 |《一出好戏》
作者:樟脑玩、喝啤酒的猫
编辑:Mo、麦麦
一个AI
能跟新垣结衣跳一样的舞,但也没法跟她一样好看啊。
本文来自果壳,谢绝转载.如有需要请联系sns@guokr.com
(欢迎转发到朋友圈~)
招聘启事
看了这么久果壳,不想加入我们吗?
新鲜空缺的职位就等你来填补
快戳下方查看
↓↓↓
本AI这样的同事,用过的都说好
果壳
ID:Guokr42
整天不知道在科普啥的果壳网
建议你关注一下


