【强化学习炼金术】李飞飞高徒带你一文读懂RL来龙去脉
| 转自新智元(微信号:AI_era)
新智元推荐
来源: 心有麟熙
作者: Jim 范麟熙
编辑:常佩琦
【新智元导读】斯坦福大学博士生、师从李飞飞教授的Jim Fan(范麟熙)带你一文读懂强化学习的来龙去脉。本文以轻松有趣的方式介绍了强化学习的概念和目的,早期功不可没的宗师泰斗,理解算法所需要的预备知识,还从仿生学和心理学的角度介绍了强化学习的历史背景。

强化学习炼金术 · 背景介绍(上)
欢迎来到《强化学习炼金术》第一讲。手摇芭蕉扇,支起八仙炉,再点上三昧真火。各位炼金术师,你们都准备好了吗

在这一课里,我会跟大家说说强化学习的概念和目的,早期功不可没的宗师泰斗们,以及理解算法所需要的预备知识。不方便看视频的朋友们,请下拉阅读图文

首先,我们重温一下,在心有麟熙导读里提到的【薄荷大法 MINT】。
Motivation,确定到底要解决什么样的问题。
分为三小步,第一个是理解这个算法的精髓insight,然后把insight变成自己的直觉intuition,最后把intuition变成解决未来问题的inspiration。
最后才是technicality技术细节,我们会推一些公式或者看一些简单的伪代码。
其次,我们这门课将会从First Principle(第一原则)开始讲,意思是我会一步一步告诉大家那些很炫酷的看上去非常复杂的算法是怎么搭起来的。
再者,我们这门课是Self-contained(自成一体)。当然如果你感兴趣的话,可以阅读更多的材料,我会在以后的图文中加一些链接。每段视频控制在五到十分钟之内,这样大家听的话也不会分神。

我们先提一下听懂强化学习需要做的一些准备工作。
其实强化学习的数学并不复杂,最多就到大一大二的数学水平就可以了。如果你对以下这三个领域的基本概念很熟悉的话,那么你可以直接跳过准备阶段。
微积分,如果你知道上图符号是什么意思就可以pass了(偏微分 partial differentiation、梯度 gradient)。
线性代数,如果你知道上图符号是什么意思也可以pass了(逆矩阵 matrix inverse、转置 matrix transpose)。
基本的概率和统计,你如果熟悉什么是正态分布,什么是一个随机变量的期望值(expected value),也就pass了。对那些不是特别熟悉的同学,之后我也会做一些短视频给大家补一补。

什么是强化学习?我们为什么需要强化学习?
我觉得骑自行车是一个非常好的例子。大家虽然现在骑车的时候都是凭感觉的,你不会去思考每一步在干什么,但如果你仔细回想一下,其实驾驭自行车是一个很复杂的过程。比如说你刚骑上去踩那个踏板,踩踏板你到底用多大的力度才好呢?太轻的话,速度不够,你就无法平稳前进。
在转弯的时候,难道只是转一下龙头就够了吗?答案是No,你需要整个身体一起配合,重心要跟着龙头一起微调,这样你才能保持平衡。虽然我们不用动脑筋,但骑车是一个需要全身协作的复杂决策过程。
我们再来回想一下,小时候是怎样学骑自行车的?我记得第一次骑车的时候,年轻气盛,自信满满,在直行还没学会就想来一个90°大转弯,结果摔得人仰马翻,鼻子肿成了圣诞老人🎄。我当时想,如果在每一个时刻都有一个老师可以精确地告诉你,你重心需要偏移多少,身体需要怎样转动,那该有多好 
如果有这样一个老师的话,他会在每一个时间点都告诉你正确的踏板力度F,比如说27牛顿、正确的转弯角度,比如42.7°,以及身体重心需要左移3.5厘米,等等。但可惜你没有这样的老师,即便有也记不住那么多数据。那你是怎么学会自行车的呢?
其实很简单,你用了一个方法叫trial and error(试错法)。当你摔倒时,你就知道之前的那个骑车方式是不对的,然后下次、再下次不断调整,直到你能顺利地全速前进。
在强化学习里有这样一个概念,叫做reward(奖励)。reward不一定都是好的。正的reward是我们通常意义上的奖励

比如说你现在往前骑了三十米,没有摔跤,那么你的奖励就是+30。每摔一跤都减10。你可能骑得特别糟糕,摔得特别惨,就像我小时候摔成了圣诞老人,那么奖励就是-100。
你在学习骑车的过程,就是把奖励的总和最大化的过程。比如你今天骑了100米,摔了两跤,那你的总分数是+80。你明天根据昨天的经验调整姿势,得分+90。后天再改进一下,终于达到了+100,掌握了骑自行车的秘诀 💯。
这整个过程并没有一个广大神通的老师参与,告诉你每一步应该转几度,重心应该偏移多少。从头到尾,你都是用trial an error,不断尝试,在每一次尝试中总结经验,然后再提高下一次的reward。这就是强化学习的精髓。

我们来追溯一下强化学习的源头。强化学习英语叫Reinforcement Learning(简称RL)。RL的历史几乎和人工智能本身的历史一样长。早在1948年的时候,现代计算机之父Alan Turing(图灵)提出了一个叫pleasure-pain system的概念。Pleasure是享乐,pain是痛苦:如果一个系统能够把享乐值最大化,把痛苦值最小化,那它就相当于从经验中不断“学习”。

第二个要为大家介绍的历史人物是大名鼎鼎的Claude Shannon(香侬)。他在1948年写了一篇划时代意义的论文“Mathematical Theory of Communication”,创立了现代信息学(Information Theory)。
当然香侬的简历还有更牛逼的亮点。1937年,他二十一岁,在MIT攻读硕士学位。他的硕士毕业论文(对,你没听错,是硕士毕业

1952年,那是个计算机还处于“黑魔法”阶段的年代。香侬设计了一个机械装置(右图的箱子)。箱子下面有很多复杂的电路,上面是一个带磁铁的小老鼠模型。在这个电路里,他实现了最最基本的强化学习算法。这个小老鼠会用我们刚才说到的trial and error(试错法),自己学会如何走出这个迷宫。

第三位泰斗级的人物是Marvin Minsky。Minsky是现代人工智能先驱之一。他奠定了深度学习的基础,因为他当年做了好多早期的关于神经网络的研究。后来他去MIT创立了人工智能实验室CSAIL。
1961年,他写了一篇论文《走向人工智能之路》。论文里他就提到了trial an error这种学习方式,以及一个新的概念 “credit assignment”。比如你连续三天吃了三种药:A、B和C。然后第四天你的病好了。请问到底哪个药对你痊愈的贡献最大?是A?是B?还是A+C?还是ABC同等重要,缺一不可?
Credit assignment是强化学习的核心问题之一,我们之后会仔细讲解。
Minsky大师在2016年逝世,精确地说是2016年1月份。2016年3月,AlphaGo以4比1击败了世界围棋冠军李世乭。非常可惜的是,这位人工智能的泰斗没有活着看到强化学习走向世界之巅的那一天。命运女神就是喜欢玩黑色幽默 。

下一位大师Arthur Samuel,他是IBM的研究员。他最著名的成就就是引入了Machine Learning(机器学习)的概念。其实“Machine Learning”这个词组就是他首创的。

Samuel在IBM设计了一台能下跳棋的电脑。这台机器的“大脑”叫TD Learning,是强化学习的一个重要算法,之后我们会仔细谈到。所以说Samuel也是最早的几位加入强化学习阵营的科学家。
强化学习炼金术 · 背景介绍(下)
欢迎来到《强化学习炼金术》Introduction第二讲,大家元旦快乐!2018,让我们共筑AI的灯塔,照亮人类前行的道路 
在这一课里,我会跟各位炼金术师们从仿生学和心理学的角度聊聊强化学习的历史背景。不方便看视频的朋友们,请下拉阅读图文

说起强化式学习在动物界的灵感,我们不得不提到俄罗斯著名的心理学家Ivan Petrovich Pavlov。巴普洛夫被公认为是二十世纪最伟大的心理学家之一,他提出的最重要的概念就是Classical Conditioning(条件反射),我今天这一课可以用一条狗和一只猫来概括。
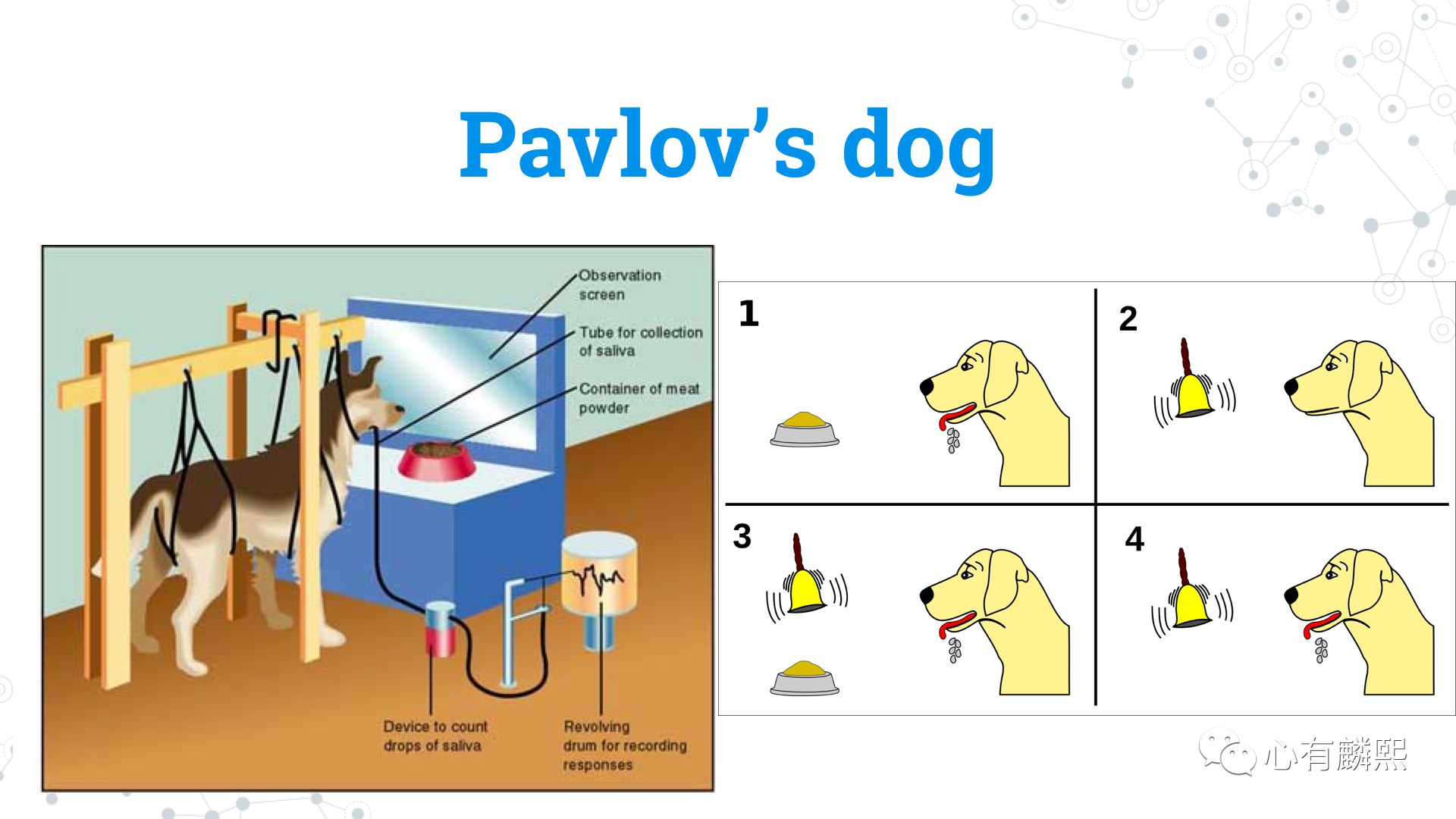
这条狗就是巴普洛夫的🐶。图左这套装置可以检测狗分泌唾液的多少,右边则是实验的示意图。比如,狗看到食物时会流口水,但一般情况下狗听到铃铛并没有任何反应。但当你把铃铛和食物配对很多次后,哪怕没有食物,只响一下铃铛,你也会看到狗在分泌唾液,这就是经典条件反射。

有这样一个笑话,巴普洛夫在观察狗的时候,其实狗也同时在观察人的反应。在这幅漫画里,狗狗是这样说的:“你看,每次我流口水时,对面那个老头他就会微笑,然后在小本子上记点东西。”
所以,我们可以认为,在强化学习里,经典条件反射,对应的就是Prediction(预测)。当你看到一个信号(比如铃铛)时,你会预测将获得怎样的奖励,然后再根据这个预测来采取行动。当然,经典条件反射是一个相对被动的过程,之后我们会谈到一个主动的过程。

下一位心理学大师是Edward Thorndike(桑代克)。 Thorndike是我们哥大的校友,他在Teacher's College,即哥大主校园对面的一片楼。那片楼非常漂亮,我记得第一次看到时,还以为是哈利波特的一个拍摄场景呢。
Thorndike提出了Law of Effect(效果律),维基百科上的定义是,在一个特定的情景下可以得到满意的效果的反应,在该情景下重复出现的概率会上升,而得到不满意的效果的反应重复出现的概率则会下降。
这句话非常拗口,简而言之就是:当你做一件事,如果你发现奖励很多,你就会多做这件事;反之亦然,如果你做的事得到了不好的回报,你就会少做这件事。这就是效果律的概念。

大家都知道薛定谔的猫,其实还有一只猫也特别有名:Thorndike's Cat。为了验证效果律,Thorndike设计了一个装置。在这个笼子里,如果🐱按了踩板,那么笼子的门就会打开。实验发现,开始时,猫咪会在笼子里不停地打转,一点头绪都没有,但是偶尔会随机地踏到踩板,然后笼子就打开了。之后第二次,猫咪再被放到笼子里时,它就会直接去踏踩板,而不会再像无头苍蝇一样浪费时间。

如果说巴普洛夫的狗是一种非自愿的条件反射,那么上述Thorndike的猫就是一种自愿的条件反射。这种自愿的行为,在后来被心理学巨匠B. F. Skinner总结为Operant Conditioning(操控反射)。
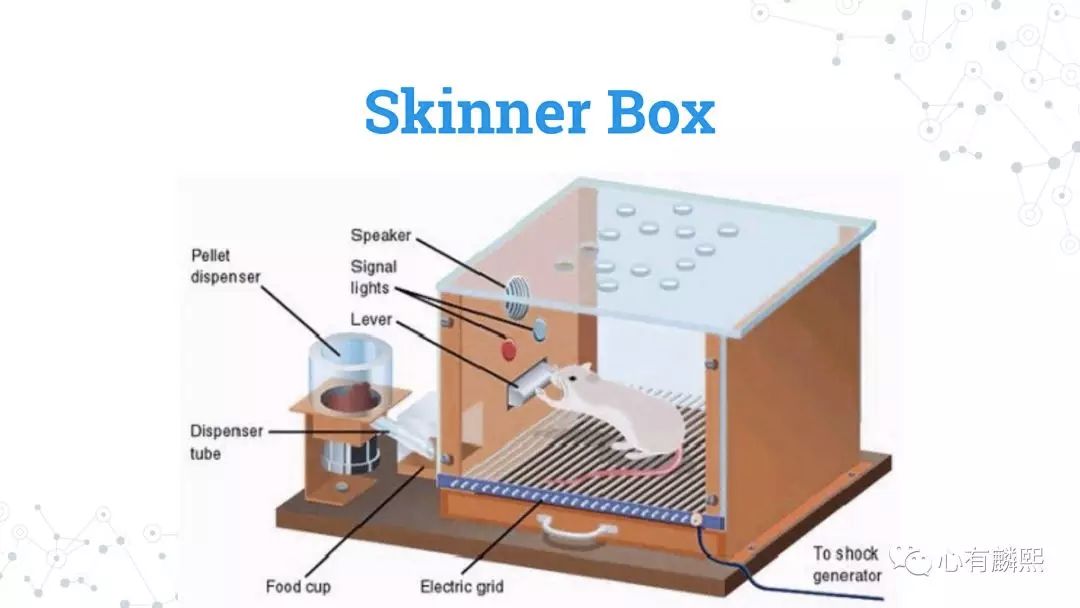
在研究操控反射时,Skinner设计了一个动物实验装置 ── Skinner Box。在这个盒子里,设有一只老鼠,和一个它能够操控的装置。如果按下杠杆,就会有食物从管中掉落;亦或是在另一种实验中,如果小鼠按下杠杆,盒子就会发出很大响声让小鼠受到惊吓。
Skinner就用这样一种装置来研究动物行为,和动物与环境的交互,即获得奖励(食物)或是惩罚(响声)。Skinner观察到,当获得奖励时,小鼠会非常频繁地按动杠杆;而当获得惩罚时,小鼠则会尽力避免触动杠杆。

在强化学习的语言里,Skinner的Operant Conditioning(操控反射)对应的概念是Control,即能够根据对环境的认识,来操控环境,从而使对自己的奖励最大化。

至此,我们一直说,Trial & Error(试错法)是强化学习的核心思想,但它并不是唯一的思想。Trial & Error 及其对应的一套算法,称为Model-free Reinforcement Learning,即没有模型的强化学习。这可认为是,人们在不断试错的过程中,养成的一种习惯。如上图,老鼠看到奶酪会扑上去,但看到奶酪旁的老鼠夹时,就会避免这个陷阱。

第二种是与Trial & Error有一定区别的强化学习,可以用1929年美国心理学家做的小鼠实验来概括。在这个实验中有两组🐭,第一组老鼠被置于迷宫里,迷宫中央设有食物。小鼠会顺着气味行动,最后取得食物,假设这组老鼠获得食物花了10分钟。这就是我们说的Trial & Error,通过不断试错(在迷宫中走到死路就往另外一边走)来达成目的。
第二组老鼠,一开始时被放置在同样的迷宫里,但这个迷宫中央并没有食物,也就是说,这个环境中并无任何奖励,小鼠在迷宫中完全是想怎么打转就怎么打转。这一阶段并不存在Trial & Error,因为小鼠没有试图去获得某种奖励。
实验人员发现,如果紧接着把这组小鼠放在相同的但是有食物的迷宫里,那么这些小鼠就能够在短短3分钟内就找到食物。这个实验结果表明,虽然在第一阶段没有任何奖励机制,但是小鼠脑子里已经建立起了一个“环境模型” ── Cognitive Map,也就是这个迷宫的地图。接着在第二阶段中设置了奖励时,小老鼠就能利用它们存在脑海里的地图,快速地找到食物。
这种强化学习涉及到Planning(规划):正因为脑海中有了环境模型,所以在第二次行动时就不需要东奔西跑,可以直接根据地图来做详细的规划。
我们给这类强化学习取个名字,叫做Model-based Reinforcement Learning,即基于模型的强化学习。




