爱因斯坦未披露演讲公开了?不,这只是一张图、一段音合成的AI视频
机器之心报道
参与:路雪、张倩、shooting
合成视频的新技术真的是层出不穷。最近,来自三星人工智能研究中心和伦敦帝国理工学院的研究人员提出一种新型端到端系统,仅凭一张照片和一段音频,就可以生成新的讲话或唱歌视频,而且视频主角不只是动嘴,整个面部表情都会有比较自然的变化。
还记得那个「会说话」的蒙娜丽莎吗?机器之心前不久报道了一项来自三星莫斯科 AI 中心和 Skolkovo 科学技术研究所的研究。在那项研究中,研究人员利用一张图像就合成了人物头像的动图,而且头像中的人物可以「说话」(只动嘴不发声)。蒙娜丽莎、梦露等名人画像、照片都可以用来作为「原料」。
如果说之前的研究成果相当于「默片」,那这次的研究结果无疑是「有声电影」了。最近,来自三星人工智能研究中心和伦敦帝国理工学院的研究人员提出:仅凭一张照片和一个音频文件即可生成会唱歌或讲话的视频。
就像之前的 deepfake 一样,这次的研究同样使用机器学习来生成合成视频。虽然达不到 100% 逼真的程度,但这项研究中所使用的数据很少,因此能达到这个程度已经很让人吃惊了。
下面这个例子中,通过将爱因斯坦演讲的真实音频片段和他的一张照片相结合,我们可以快速创建一个前所未有的演讲视频:
前面的视频很容易让人相信,毕竟用的声音和照片都属于爱因斯坦本人。不过,下面这个就有点魔幻了。让「俄国妖僧」拉斯普京演唱碧昂丝的经典歌曲《halo》?是在逗我吗?
那下面这个更逼真的例子呢?生成的视频不仅与输入音频相匹配,而且还可以传达特定的情绪。不要忘了,生成这些视频只用了一张图像、一个音频而已。其余的工作都由算法来完成。
如前所述,这项研究并不是百分百逼真,但它足以佐证 deepfake 这种技术发展有多快了。现如今,生成假视频的技术正变得越来越简单,而实现的结果却越来越让人惊叹。
最初只是把视频中的人脸换一下来生成假视频。而仅仅这样就有人利用该技术制作色情视频,或者仿制政客演讲或言论。而现在,只需少量图像和音频,就可以制作比较逼真的唱歌或讲话视频了。
这些技术在给人们带来更多乐趣的同时,也带来了更多的焦虑。关于技术不作恶的呼吁越来越多,而政府和机构也开始行动。如此种种,此处不再赘述,详情可以参考:「AI 间谍」扰乱美国政坛,众议院提出法案打击 Deepfake 换脸技术。
下面,我们将介绍这项研究的具体方法和原理。
这项新研究出现在了计算机视觉顶会 CVPR 2019 上,它提出了一个端到端系统,能够在仅提供一张人物静止图像和含语音的音频片段的情况下,生成该人物的动态视频,且不需要手动提取中间特征。此外,该方法生成的视频具备两大特点:1)视频中人物嘴唇动作和音频完全同步;2)人物面部表情自然,比如眨眼和眉毛的动作。
模型架构
该研究提出的模型架构见下图。该系统包含一个时序生成器(temporal generator)和多个判别器,每个判别器从不同视角评估生成的序列。生成器捕捉自然序列不同侧面的能力与每个判别器基于不同侧面判别视频的能力成正比。
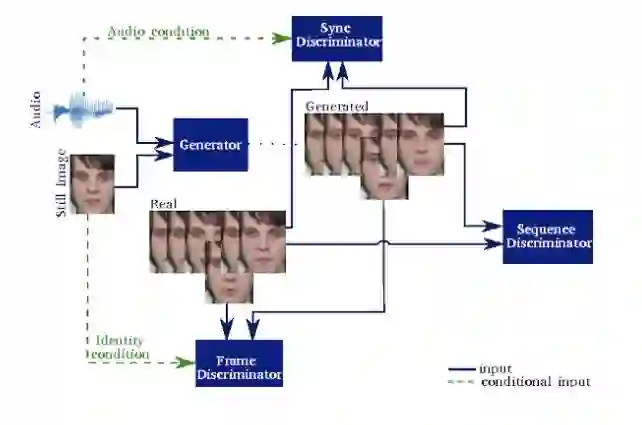
该语音驱动人脸合成方法的深度模型图示。该模型使用 3 个判别器来整合逼真视频的不同方面。
研究者表示这项新研究是对之前研究《End-to-End Speech-Driven Facial Animation using Temporal GANs》的扩展,分别处理音频-视觉同步和表情生成。此外,新模型可以在未见过的人脸图像上很好地运行,且能够捕捉到说话者的情绪,并将这些情绪反映在人脸表情中。
生成器
生成器网络有一个编码器-解码器结构,从概念上可以分为若干子网络(如图 3 所示)。研究者假设一个潜在表征由 3 个组件构成,这些组件分别负责说话者的身份、语音内容和自然的面部表情。这些组件由不同的模块生成,结合在一起形成一个可被解码网络转换为帧的嵌入。
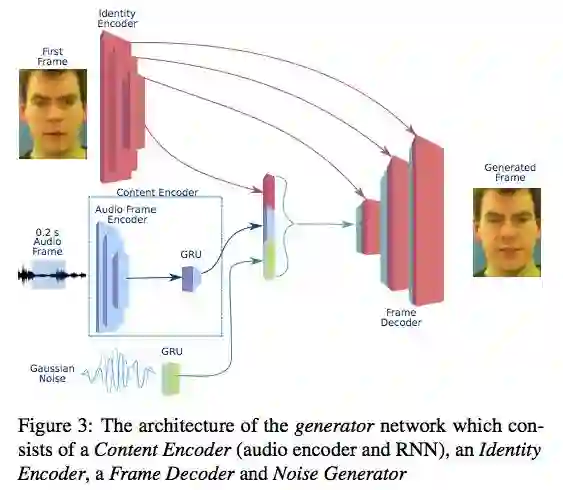
图 3:生成器网络架构图示。该网络包含一个内容编码器(音频编码器和 RNN)、一个身份编码器、一个帧解码器和一个噪声生成器。
每个帧的潜在表征由身份、内容和噪声组件联合构成。帧解码器是一个 CNN,使用步长装置卷积(strided transposed convolution)从潜在表征中生成视频帧。在身份编码器和和帧解码器之间使用 U-Net 架构和残差连接,以保存目标的身份,如图 4 所示。

图 4:将残差连接加到生成网络中后产生的影响。(a)中显示的是在没有残差连接的情况下得到的帧,该帧中的人物与(b)中的真实人物并不相似。加入残差连接可以确保将人物身份特征保存在帧中。
判别器
本文中的系统使用了多个判别器,以捕获自然视频多个方面的信息。帧判别器(Frame Discriminator)对视频中说话者的面部进行了高质量的重建。序列判别器(Sequence Discriminator)确保那些帧形成一个包含自然动作的连贯视频。最后,同步判别器(Synchronization Discriminator)强化了对视听同步的要求。

图 5:同步判别器决定某个视听对是否同步。它使用了两个编码器来获取音频和视频的嵌入,并根据二者欧氏距离决定它们是否同步。
实验
研究者使用 PyTorch 实现该模型,用大约一周的时间在一块英伟达 GeForce GTX 1080 Ti GPU 上完成训练。
数据
实验在 GRID、TCD TIMIT、CREMA-D 和 LRW 数据集上进行。这些数据集的训练、验证、测试集情况如下表所示:
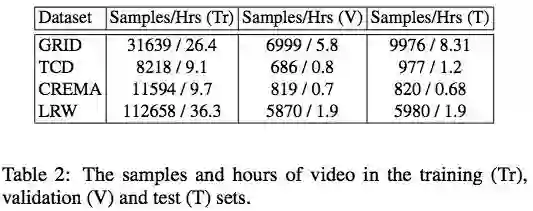
表 2:训练(Tr)、验证(V)和测试集(T)中的样本和视频长度。
度量指标
此外,该研究使用以下指标度量模型生成视频的质量。
Reconstruction Metrics
Sharpness Metrics
Content Metrics
Audio-Visual Synchrony Metrics
Expression Evaluation
其中,前两个度量指标是评估视频帧质量的传统指标,但它们无法反映视频的音画同步、面部表情是否自然,因此该研究使用 Content Metrics 评估视频的内容(视频捕捉目标身份的程度以及话语的准确率),使用 Audio-Visual Synchrony Metrics 评估视频的音画同步程度,用 Expression Evaluation 评估视频中人脸表情的自然程度。
实验结果
定性结果
本文中的方法能够生成逼真的视频,该视频由之前未见过的面孔和从测试集中剪切的音频组成。不同的人物配上相同声音的结果如图 13 所示。从视觉上可以明显看出,这些人物一直在和真实视频中的人物做着相同的嘴型运动。

图 13:不同人物利用同一个音频的效果图。
该方法不仅可以生成准确的唇形,还能生成带有皱眉、眨眼、生气大叫等面部表情的人物自然视频,如图 14 所示。
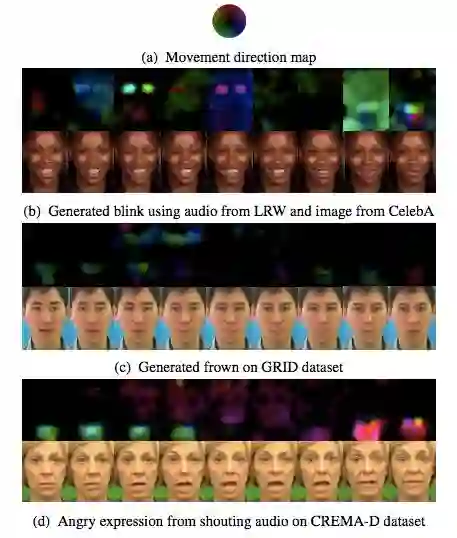
图 14:使用本文中的框架生成的面部表情,包括(b)眨眼、(c)皱眉、(d)生气大叫。对应的光流变动位置图在每个图像序列的上方。运动方向参考图(a)。
生成的表情数量和多样性取决于训练数据中的表情,因此在 CREMA-D 等表情丰富的数据集上训练的模型可以生成表情丰富的人脸,如图 15 所示。面部表情反映了说话者的情绪。

由于基线模型和 Speech2Vid 模型均为静态方法,因此它们生成的序列一致性较差,有抖动,而这一现象在没有音频的片段中(话语之间的静止时刻)更加糟糕。下图展示了静止模型在这方面的失败表现,同时展示了静态模型与该研究提出方法的对比情况。

图 17:图中的连续帧表明静态方法无法生成一致的动作。在无声片段中,静态方法生成视频中人物嘴部出现抖动。
此外,该新模型的一大优势是可以生成人物面部表情,视频中的人物不止嘴在动,面部表情也在变化,如下图所示:

图 19:本文中的模型与 Speech2Vid 的对比。很明显,后者只能生成嘴型,无法生成面部表情。
定量结果
下表 6 展示了该研究提出的方法在帧质量和内容准确率方面均优于其他方法。
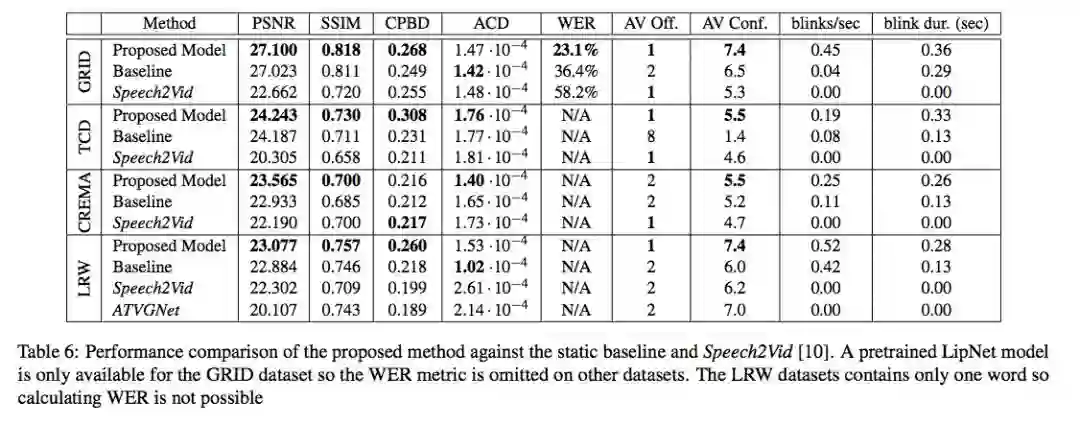
表 6:该研究提出的方法与静态基线模型和 Speech2Vid [10] 的性能对比结果。
用户调查
人类对合成视频的感知很难用客观指标进行量化,因此该研究通过在线图灵测试评估生成视频的逼真程度。
在该测试中,用户需要观看 24 个视频(12 个真实视频,12 个为合成视频),这些视频均随机选自 GRID、TIMIT 和 CREMA 数据集。用户需要将每个视频标注为「real」或「fake」。来自 66 名用户的反馈表明,平均用户标注准确率为 52%,详见下图。
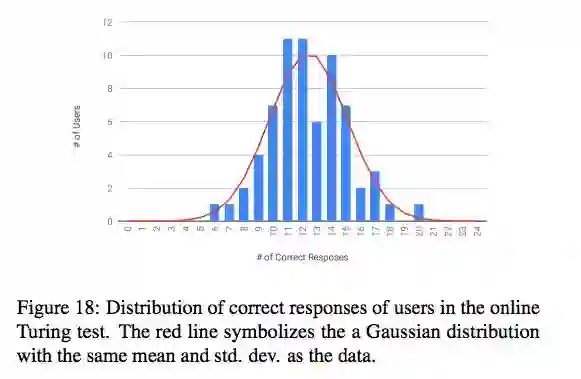
图 18:在线图灵测试中用户准确反应的分布情况。
图灵测试地址:https://docs.google.com/forms/d/e/1FAIpQLSftFTMoCmNl6evECx4LaoPqIKgZoRo1pB7GrsCmsRXDQij4Xg/viewform
打开这个链接,你也可以尝试辨别真假视频~

参考内容:https://arxiv.org/pdf/1906.06337.pdf
https://www.theverge.com/2019/6/20/18692671/deepfake-technology-singing-talking-video-portrait-from-a-single-image-imperial-college-samsung

市北·GMIS 2019全球数据智能峰会于7月19日-20日在上海市静安区举行。本次峰会以「数据智能」为主题,聚焦最前沿研究方向,同时更加关注数据智能经济及其产业生态的发展情况,为技术从研究走向落地提供借鉴。
本次峰会设置主旨演讲、主题演讲、AI画展、「AI00」数据智能榜单发布、闭门晚宴等环节,已确认出席嘉宾如下:

大会早鸟票已开售,我们也为广大学生用户准备了最高优惠的学生票,点击阅读原文即刻报名。


