编辑:袁榭
【新智元导读】现在宣布某模型是AGI几乎成了公众娱乐项目:2022年6月19日,《大西洋月刊》宣布谷歌的PaLM模型也「活了」。
「通用人工智能」现在几乎已经成了2020年代的「水变油」科技,差不多每半个月都会有人宣布发现/确信某个大模型的表现是已经觉醒了人性、AI「活过来」了。
最近此类消息闹得最凶的是谷歌。广为人知的是前研究员Blake Lemoine说大语言模型LaMDA「活了」,这位老哥不出所料地进入了被离职流程。
其实几乎与之同时的,还有《大西洋月刊》的谷歌准软文在说,另一个新款大语言模型PaLM也成了「真正的通用人工智能」(It is a true artificial general intelligence)。
只不过这篇文章几乎没人读,因此引发的讨论和抨击只有寥寥而已。
然而,世界级大刊吹捧世界级大厂的稿件,即使再没人读,也像老电影台词说的一样,「就好像黑夜里的萤火虫一样,那么鲜明,那么出众……」
2022年6月19日,《大西洋月刊》发布题为《人工意识好无聊》(Artificial Consciousness Is Boring)的文章。
而《大西洋月刊》此文的网页标题比欲盖弥彰的文章标题直白:《谷歌的PaLM AI比真实意识要奇怪得多》(Google's PaLM AI Is Far Stranger Than Conscious)。
内文不出意料,是作者采访谷歌大脑的PaLM项目组成员之后的种种溢美之词:
5400亿参数,能不预先训练就完成数百种不同的任务。能说笑话,能总结概述文本。
如果用户输入孟加拉语问题,PaLM模型可以用孟加拉语和英语答复。
如果用户要求把一段代码从C语言译为Python,PaLM模型也能快速完成。
但此文逐渐从疑似软文的夸夸访谈稿,走向了一个吹吹翻车稿:宣布PaLM模型是「真正的通用人工智能」(It is a true artificial general intelligence)。
「PaLM的功能吓到了开发者们,需要智识上的酷炫和距离、才能不被吓到且接受—PaLM具有理性。」(the function that has startled its own developers, and which requires a certain distance and intellectual coolness not to freak out over. PaLM can reason.)
这个宣称的依据何在呢?按此文作者说,是因为PaLM模型可以在没有预先特定训练的前提下,自行「跳出定式」来解决不同的智能任务。
而且PaLM模型拥有「思维链提示」功能,用白话说是将问题求解过程给PaLM模型拆解、解释、演示一遍后,PaLM就能自行得出正确答案啦。
噱头和证据之间的差距,有极大的「裤脱看这」感觉:原来《大西洋月刊》的作者,也有不查料就开始采访人写稿的习惯啊。
之所以这么说,是因为Jeff Dean老师带队推出PaLM模型时,介绍过「思维链提示」功能。但谷歌大脑可绝不敢自吹这个产品是个已经活过来的「终结者」。
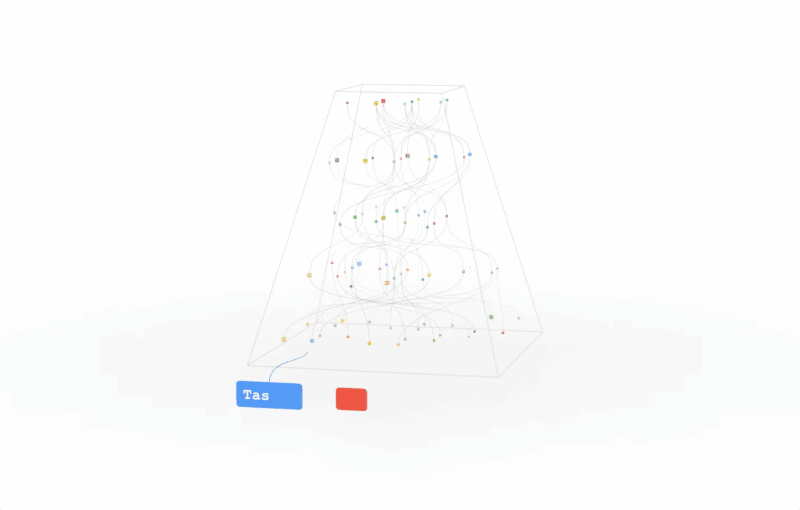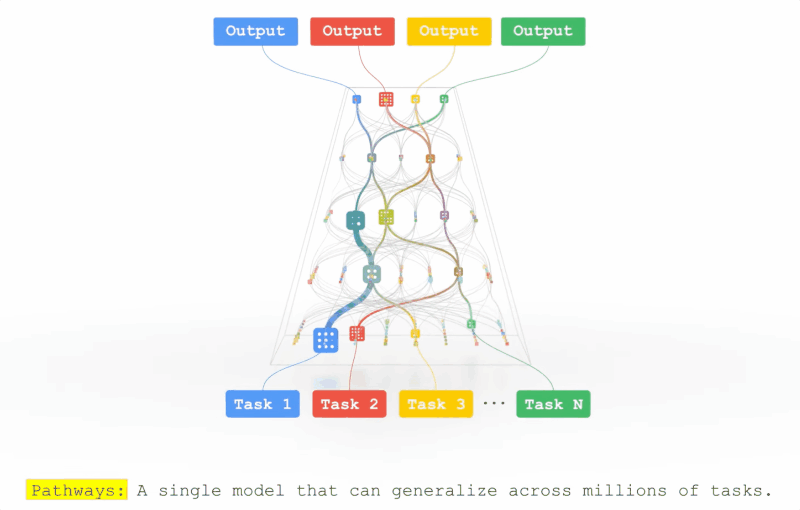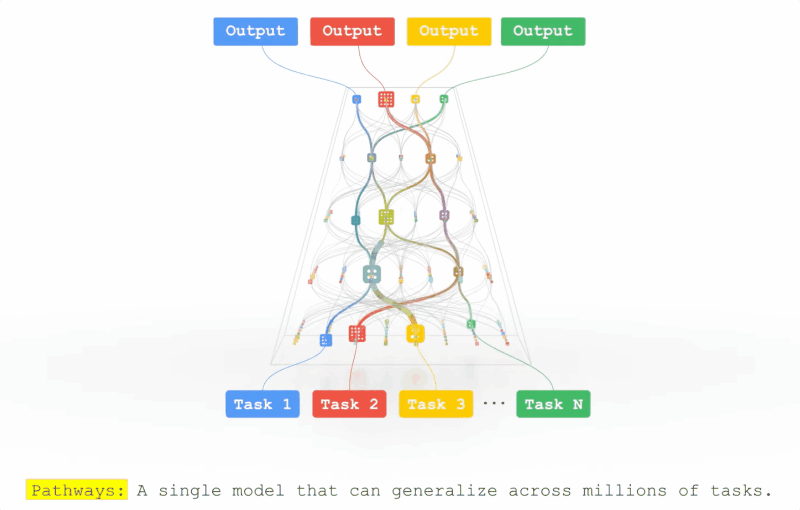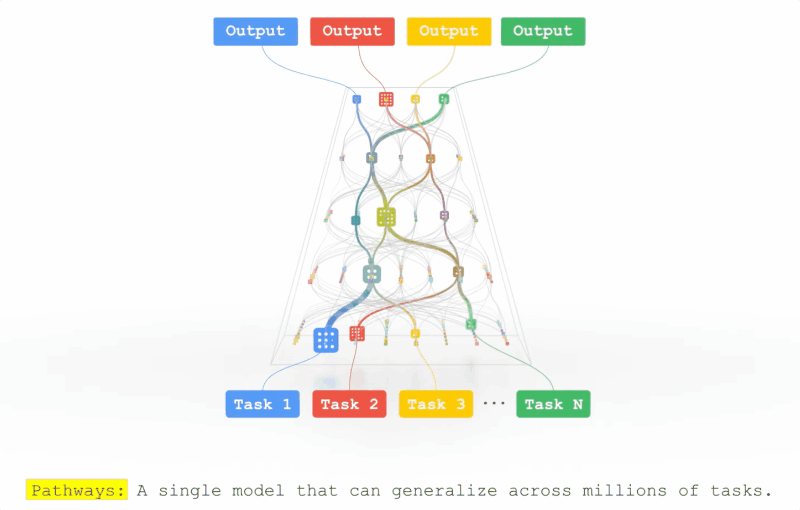
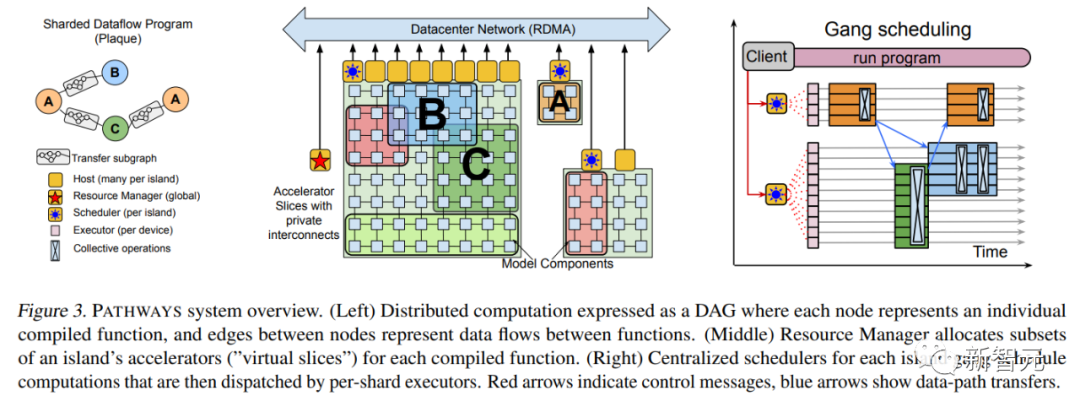
2021年10月,Jeff Dean亲自撰文介绍了一个全新的机器学习架构——Pathways。
目的很简单,就是让一个AI能够跨越数以万计的的任务,理解不同类型的数据,并同时以极高的效率实现:
在大半年之后的2022年3月,Jeff Dean终于发布了Pathways的论文。
论文地址:https://arxiv.org/abs/2203.12533
其中,补充了不少技术上的细节,比如最基本的系统架构等等。
2022年4月,谷歌用Pathways系统构造的PaLM语言模型面试世,这个拥有5400亿参数的Transformer语言模型,接连打破多项自然语言处理任务的SOTA。
除了用到强大的Pathways系统外,论文中介绍PaLM的训练用到了6144个TPU v4,使用了7800亿token的高质量数据集,并且其中有22%的非英文、多语种语料。
论文地址:https://arxiv.org/abs/2204.02311
「自监督学习」、「思维链提示」在此前就是AI业界不陌生的概念,PaLM模型只是更进一步将概念落地具现化。
而雪上加霜的是,《大西洋月刊》此文直说了「谷歌研究者们也不清楚PaLM模型为何能达到此功能」…………
果然,美国加州圣菲研究所的成员Melanie Mitchell教授在自己的社交网站账号上发连续贴,含蓄但坚定地质疑了《大西洋月刊》此文。
Melanie Mitchell表示:「这文章很有趣,不过我认为作者可能没有采访谷歌研究者以外的AI界专业人士。
比如其中种种声称PaLM模型『真正AGI』的证据。我本人是没有使用PaLM的权限啊,不过谷歌4月自己发布论文中只是在几个基准测试上有效果显著的小样本学习测试,但并非PaLM的所有小样本学习测试结果都同样稳健。
并且其中测试中使用的基准,有多少使用『捷径学习』这一简化难度的技术,论文中也未提到。
按照《大西洋月刊》文章的措辞,PaLM至少可以高可靠度、高通用度、一般精度来完成各种任务。
然而不论是此文还是谷歌4月论文,都没有详细描述PaLM模型在通用智能方面的能力与局限,也没有提及测试此方面能力的基准。
GPT系列的类似声称,因为其访问权限的开放性,已经被在其上跑各种实验的业内人士证伪了。如果PaLM要获得如此殊荣,就该接受同等程度的对抗性验证。
还有,按谷歌4月论文的自白,PaLM的理性方面基准测试也就比业内几个同类SOTA模型好一点点,优胜不多。
最关键一点,PaLM的论文未经同侪评议、模型也不对外界开放任何访问权限。所有声称都只算一张嘴在吹,无法证实、无法复现、无法评估。」
参考资料:
https://www.theatlantic.com/technology/archive/2022/06/google-palm-ai-artificial-consciousness/661329/
https://twitter.com/MelMitchell1/status/1538564756239314945
![]()