NeurIPS 2020 | MESA: 元学习驱动的采样器+集成学习解决类别不平衡问题
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文作者:刘芷宁
https://zhuanlan.zhihu.com/p/268539195
本文已由原作者授权,不得擅自二次转载
本文介绍的内容来自于我们近期被 NeurIPS 2020 接收的工作 MESA: Boost Ensemble Imbalanced Learning with MEta-SAmpler。欢迎Discussion/Star/Cite!

论文:https://arxiv.org/abs/2010.08830
代码:https://github.com/ZhiningLiu1998/mesa
Background
现有的不平衡学习方法大多建立在由观察总结出的假设上。
如SMOTE[1]类方法认为在少数类样本之间生成新的样本有助于改善少数类的表示质量从而帮助学习,一些SMOTE的变体(如Borderline-SMOTE[2])在选择种子样本时加入了其他的策略,比如选择与其他类距离更近的样本,其隐含的假设是这些样本更加靠近分类边界。Hard example mining类方法则通过学习过程中样本的分类误差来进行针对性的处理,它们的假设是分类误差更大的样本隐含更多的信息,能够帮助学习器更快地收敛,代表性的方法有AdaBoost[3]、FocalLoss[4]等。
在实际应用中,这些根据直觉或者某些特定任务上的观察建立的假设可能并不成立。比如SMOTE类方法在少数类分为多个sub-clusters时会生成分布外样本,hard examle mining 可能在数据集包含较多噪声时错误地赋予噪声样本过高权重并导致训练不稳定。
最近的一些工作尝试通过元学习来得到超越手动设计的策略,如[5, 6]。以Meta-weight-net[5]为例,它设计了一个用于给每个样本的加权的元学习器,输入为样本的损失值,输出为样本权重,这个权重被用做每个样本损失前面的系数。
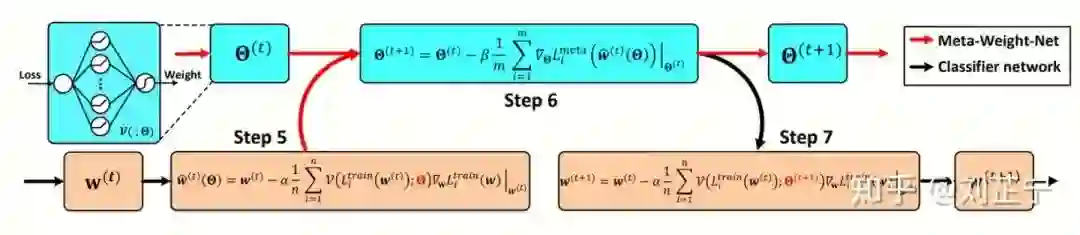
这些元学习方法是为神经网络模型特别设计的。它们的元学习器被设计为与student network以一种类似ADMM的方式共同/交替优化,因此不能直接应用于无梯度的学习器。
在应用中,深度学习方法在结构化、有领域关系的数据(如图像、文本、语音等)上有着压倒性的性能优势,但同时也需要海量的训练数据与计算资源。在非结构化的表格数据(tabular data)上,由于特征间相关性的不确定性且数据规模可能不足以支撑大容量模型(如神经网络)的训练,决策树或使用梯度提升之类的方法做弱学习器的集成更常用且更高效的选择。
因此,我们这篇工作尝试通过以一种更General的方式,而非受限于特定的学习模型,来使用meta-learning的思想解决不平衡学习问题。
The proposed MESA framework
MESA是一个串行式训练的集成学习框架,带有额外的元训练过程。我们设计的目标有:
使用更高层的meta-information来实现自适应重采样,从而进一步提升集成模型的性能。
将meta-training和model-training解耦,使得框架能应用于各种不同的机器学习模型。
设计并使用与任务无关的状态表示训练meta-sampler,赋予采样器跨任务可迁移性从而减少meta-training带来的计算开销。
MESA的内容主要包括三部分:用于训练集成模型的meta-sampling,ensemble training,以及用于训练meta-sampler的meta-training。如下图所示。
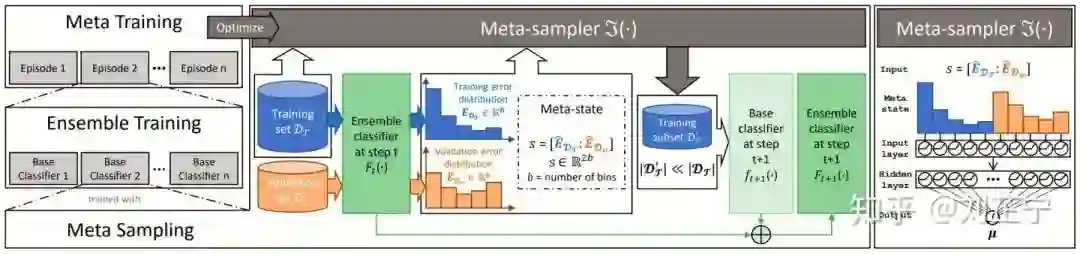
Meta-state
如前所述,我们希望找到一种与任务无关的状态表示作为元状态,给采样器提供必要的信息。受[7, 8]中的“梯度/硬度分布”概念的启发,我们最终使用训练及验证集上的预测误差分布(prediction error distribution)作为整个系统的状态表示。

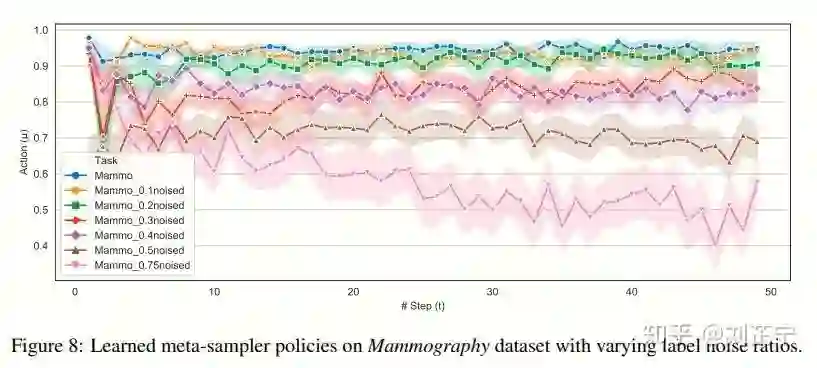
直观来讲,这种meta-state能够更细粒度地反映"easy/hard example"的数量分布,由于我们同时考虑训练集与未见的验证集(开发集),它还包含了当前模型的bias/variance的信息,从而能够给采样器做出决策提供支持性的信息。下图中提供了一个更加直观的示例。

Meta-sampling
在设计采样器时,有数种可选择的策略,最直接的方法如设置一个带有超宽output layer的network,或者使用RNN来进行迭代式地对每个样本做决策(比如[9])。这么做虽然能够对每个样本单独做出决策(instance-level decision),但代价是非常高昂的计算开销。对于一个数据集 

为了使MESA更加简洁、紧凑、高效,我们使用了一个trick来避免上述问题,将单次更新的开销从 



直观上讲,这意味着采样器倾向于保留那些预测误差接近 


Ensemble Training
MESA的集成训练过程以串行的方式训练多个基学习器。具体来说,每次迭代开始时,我们有不平衡的原始数据集以及当前的集成模型,由此可以得到我们所使用的meta-state:即预测误差分布。随后,采样器根据当前的state来对原始数据进行动态欠采样,得到一个平衡的训练集。我们用采样后的训练集训练一个基学习器并将其加入集成模型,便完成了一次更新。
Meta Training
如前所述,我们希望MESA可以直接从数据中学习最合适的采样策略(采样器参数)来优化集成模型最终的泛化性能。注意到在ensemble training的每次迭代中,都发生了采样器与外部环境的一次互动(interaction),环境提供一个状态 


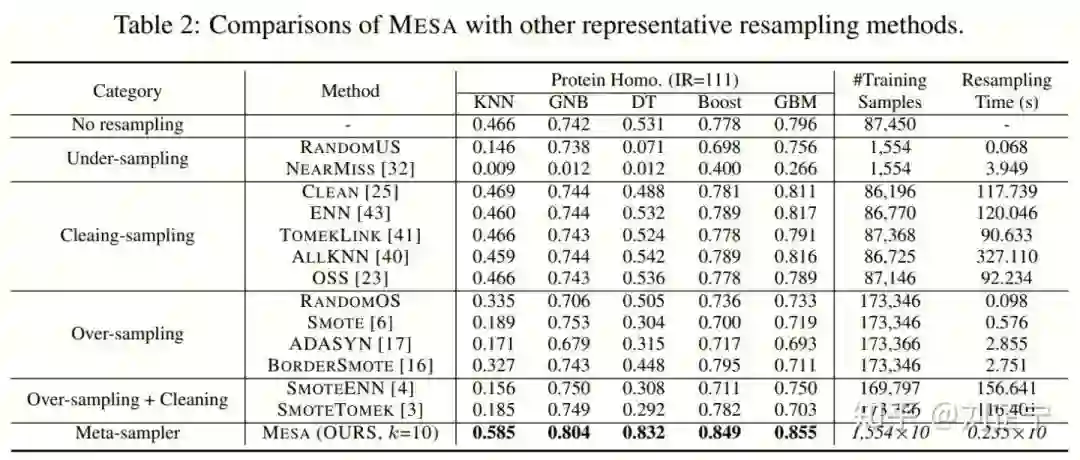
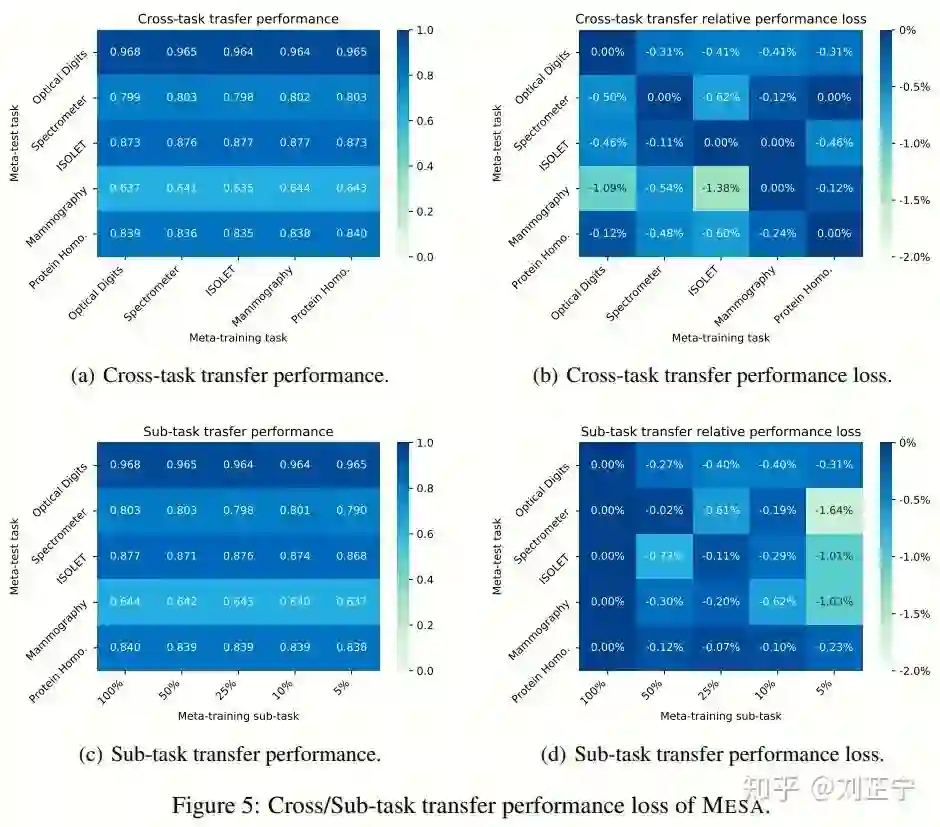
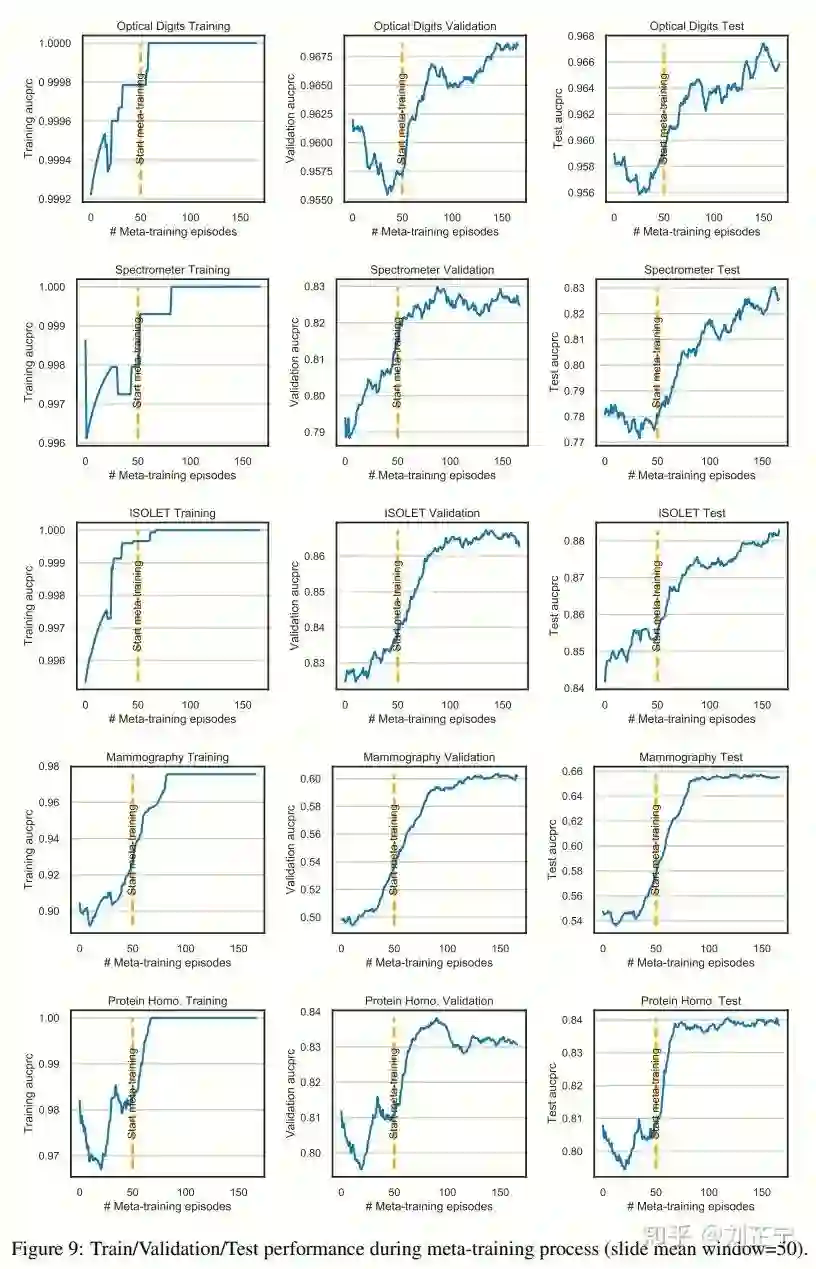
Experiments


References
| [1] Nitesh V Chawla, Kevin W Bowyer, Lawrence O Hall, and W Philip Kegelmeyer. Smote: synthetic minority over-sampling technique. Journal of artificial intelligence research, 16:321– 357, 2002. |
| [2] Hui Han, Wen-Yuan Wang, and Bing-Huan Mao. Borderline-smote: a new over-sampling method in imbalanced data sets learning. In International conference on intelligent computing, pages 878–887. Springer, 2005. |
| [3] Yoav Freund and Robert E Schapire. A decision-theoretic generalization of on-line learning and an application to boosting. Journal of computer and system sciences, 55(1):119–139, 1997. |
| [4] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision, pages 2980–2988, 2017. |
| [5] Jun Shu, Qi Xie, Lixuan Yi, Qian Zhao, Sanping Zhou, Zongben Xu, and Deyu Meng. Meta-weight-net: Learning an explicit mapping for sample weighting. In NeurIPS, 2019. |
| [6] Mengye Ren, Wenyuan Zeng, Bin Yang, and Raquel Urtasun. Learning to reweight examples for robust deep learning. In International Conference on Machine Learning, pages 4334–4343, 2018. |
| [7] Zhining Liu, Wei Cao, Zhifeng Gao, Jiang Bian, Hechang Chen, Yi Chang, and Tie-Yan Liu. Self-paced ensemble for highly imbalanced massive data classification. In 2020 IEEE 36th International Conference on Data Engineering (ICDE). IEEE, 2020. |
| [8] Buyu Li, Yu Liu, and Xiaogang Wang. Gradient harmonized single-stage detector. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 8577–8584, 2019. |
| [9] Peng M, Zhang Q, Xing X, et al. Trainable undersampling for class-imbalance learning[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33: 4707-4714. |
下载1
在CVer公众号后台回复:PRML,即可下载758页《模式识别和机器学习》PRML电子书和源码。该书是机器学习领域中的第一本教科书,全面涵盖了该领域重要的知识点。本书适用于机器学习、计算机视觉、自然语言处理、统计学、计算机科学、信号处理等方向。

PRML
下载2:CVPR / ECCV 2020开源代码
在CVer公众号后台回复:CVPR2020,即可下载CVPR 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2400+人,旨在交流顶会(CVPR/ICCV/ECCV/NIPS/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI/TIP等)、SCI、EI、中文核心等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!



