学界 | 谷歌大脑提出通过多文档摘要方法生成维基百科,可处理较长序列
选自arXiv
作者:Peter J. Liu、Mohammad Saleh 等
机器之心编译
参与:白悦、路雪
近日,谷歌大脑发布论文,提出一种通过提取多文档摘要来生成英文维基百科文章的方法,该方法可以处理长序列。
序列到序列框架已被证明在自然语言序列转导任务(如机器翻译)中取得了成功。最近,神经技术被应用于提取新闻文章中的单文档、抽象(释义)文本摘要(Rush et al. (2015), Nallapati et al. (2016))。之前的研究以端到端的方式训练监督模型的输入——从一篇文章的第一句到整个文本——来预测参考摘要。进行端到端的处理需要大量相关的文章-摘要对,因此语言理解是生成流畅摘要的首要条件。
而谷歌大脑这篇论文考虑的是多文档摘要的任务,输入是提炼过摘要的相关文档的集合。之前的研究主要是提取摘要(从输入中选择句子或词组来形成摘要),而不是生成新文本。抽象神经模型的应用有限,一个可能的原因是缺少大型标注数据集。
在这篇论文中,研究者把英语维基百科看成是一个多文档摘要的监督式机器学习任务,输入是维基百科的主题(文章标题)和非维基百科参考文献的集合,目标是维基百科文章的文本。研究者首先描述了基于参考文本抽象生成维基百科文章的第一部分或主要部分。除了在任务中运行强大的基线模型以外,研究者还将 Transformer 结构(Vaswani et al., 2017)修改为只包含一个解码器的结构,与 RNN 和传统的编码器-解码器模型相比,这种结构在长输入序列中表现更好。最后,研究者展示了可生成整个维基百科文章的优化模型。

表 1:摘要数据集输入/输出的数量级和一元回调(unigram recall)。
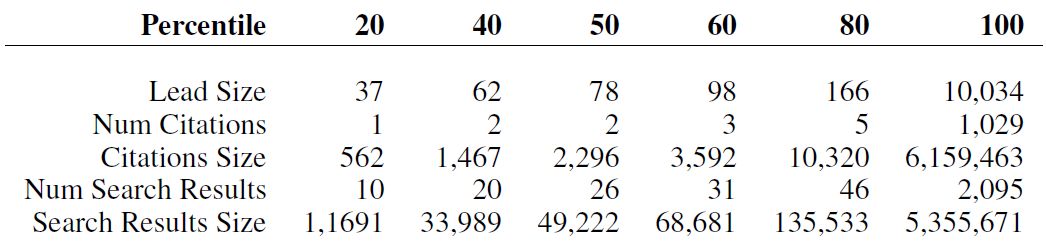
表 2:WikiSum 数据集不同属性的百分比,大小以单词数量为单位。
将英文维基百科作为一个多文档摘要数据集
作为百科全书的维基百科(Wikipedia)可以被看作是给定不同标题的各种主题摘要的集合,如「加拿大(Canada)」和「机器学习(Machine Learning)」。用于提取摘要的原始材料可以是网上或书中各种有良好声誉的文件,然而,为了使问题更加容易处理,研究者考虑所有文档的以下子集 D:
1. 引用资料:一篇符合体例指南的维基百科文章在「References」(参考文献)部分应该有引用资料。对于每篇文章,对于一篇文章 a_i,研究者从可抓取的引用文档中提取无标记的所有文本 C_i(C_i ⊂ D)作为模型的输入。
2. 网页搜索结果:为了扩展参考文档的集合,研究者使用文章标题作为搜索内容,在谷歌搜索引擎中搜索结果。每次查询收集 10 个结果页面。在此集合中,去掉维基百科文章自身(往往在最上面),同时也去掉「克隆」的结果(与维基百科文章高度重叠的结果)(A.2.1 中有详细介绍)。研究者将文章 a_i 精炼后的搜索结果表示为 S_i(S_i ⊂ D)。类似于 C_i,研究者仅提取文本作为输入。
表 2 描述了 WikiSum 数据集的整体属性。许多文章的引用资料很少,因此研究者使用网页搜索结果作为源文档的补充。不过,引用资料往往质量更高。统计数据集中的总单词数时,我们会发现它比之前的摘要数据集大一个数量集。
为了在语料库比较实验(corpus-comparison experiment)中使训练/开发/测试数据保持一致,研究者将文章的范围限制为至少具备一个可抓取引用资料的维基百科文章。研究者将文章按 80/10/10 的比例大致分成训练/开发/测试子集,分别得到了 1865750、233252 和 232998 个样本。
方法和模型
由于输入参考文档(C_i,S_i)中的文本数量会非常大(参见表 2),考虑到当前硬件的内存限制,训练端到端的抽象模型并不可行。因此,研究者首先通过抽取摘要粗略地选择输入的子集,然后基于此训练一个生成维基百科文本的抽象模型。这两步受到人们从多个长文档中提取摘要的启发:首先突出显著信息,然后基于此生成摘要。
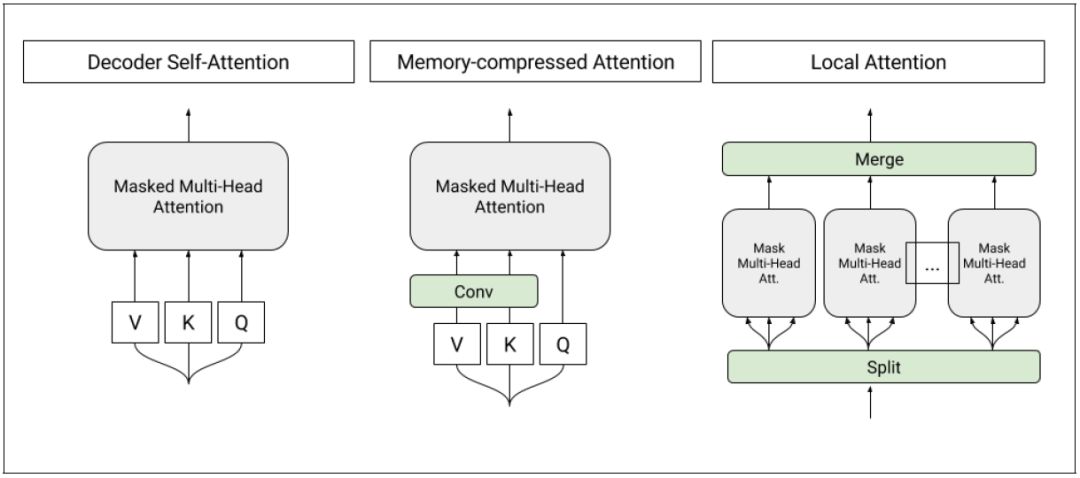
图 1:T-DMCA 模型中使用的自注意力层架构。每个注意力层都将一个符号序列作为输入,并产生一个相似长度的输出序列。左图:transformer-解码器中的原始自注意力。中图:内存压缩的注意力,减少了密钥/数值的数量。右图:将序列分割为单个较小子序列的局部注意力。之后子序列合并在一起得到最终输出序列。

图 4:相同样本在不同模型中产生的预测结果。模型输入样本可在附录 A.4 中找到。
图 4 展示了三个不同模型(使用 tf-idf 提取和组合语料库)的预测结果和维基百科原文本(输入样本)。随着复杂度的降低,我们可以看到模型输出在流畅性、事实准确性和叙述复杂性方面有所改善。特别是,T-DMCA 模型提供了维基百科版本的一个可替代性选择,并且更为简洁,同时提到了关键事实,例如律师事务所的位置、成立方式和时间以及企业的兴衰。
在模型输出的手动检查中,研究者注意到一个意想不到的副作用:模型尝试学习将英文名称翻译为多种语言,例如将 Rohit Viswanath 翻译成印地语(见图 5)。尽管研究者没有系统地评估这些翻译,但他们发现译文往往是正确的,而且在维基百科文章里找不到。研究者还证实了译文通常不是从内容源中复制的,例如目标语言不正确的示例(例如把英文名称翻译为乌克兰语)。
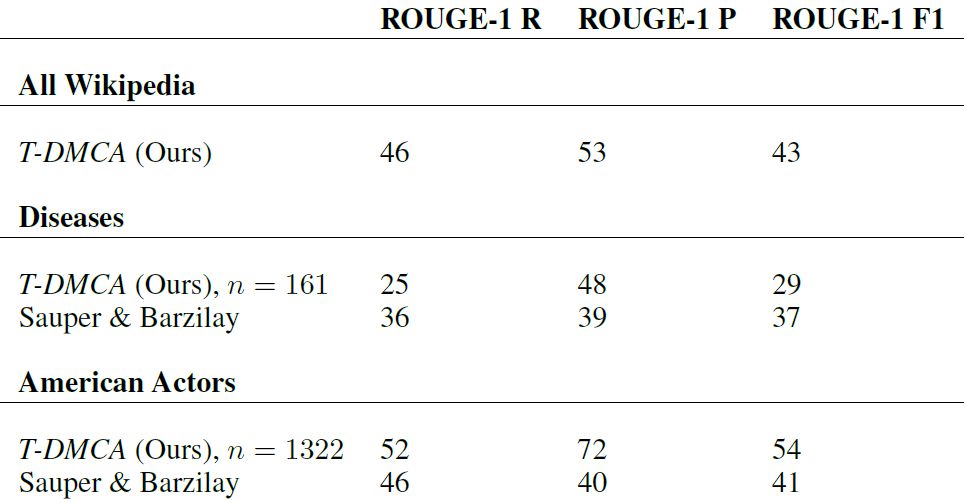
表 7:与 Sauper 和 Barzilay(2009)的论文中的结果比较。请注意,谷歌大脑这篇论文中的的结果是维基百科主要部分的报告,而 Sauper 和 Barzilay 的是文章的报告。
相关代码链接:https://gist.github.com/peterjliu/f0dc9152a630520dc604c783db963aa7
论文:Generating Wikipedia by Summarizing Long Sequences

论文链接:https://arxiv.org/abs/1801.10198
我们展示了可以通过对源文档提取多文档摘要来生成英文维基百科文章。我们通过提取摘要来粗略地识别显著信息,通过神经抽象模型生成文章。对于抽象模型,我们引入了只含一个解码器的结构,它可以处理很长的序列,比序列转导中传统的编码器-解码器架构处理的序列长得多。我们展示了这个模型可以生成流畅、连贯的多句段落,甚至生成整个维基百科文章。在给出参考文档时,我们证明了该模型可以提取相关的事实信息,以复杂度、ROUGE 分数和人类评估结果的形式呈现。)

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com




