推断速度达seq2seq模型的100倍,谷歌开源文本生成新方法LaserTagger
选自arXiv
使用 seq2seq 模型解决文本生成任务伴随着一些重大缺陷,谷歌研究人员提出新型文本生成方法 LaserTagger,旨在解决这些缺陷,提高文本生成的速度和效率。

论文地址:https://research.google/pubs/pub48542/
开源地址:http://lasertagger.page.link/code
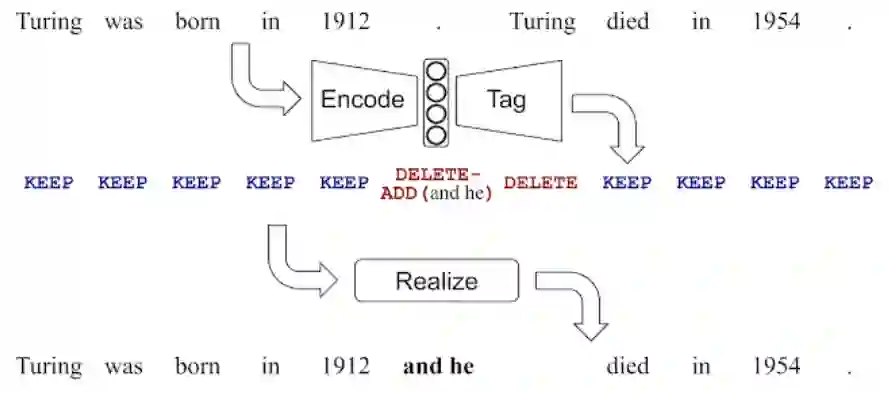
控制:通过控制输出词组表,LaserTagger 更不容易受到幻觉的影响;
推断速度:LaserTagger 计算预测的速度是 seq2seq 基线模型的 100 倍,因此适合实时应用;
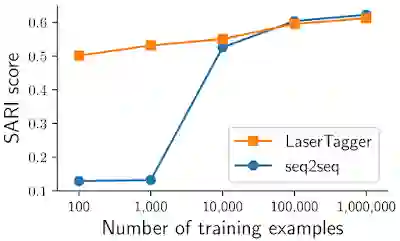
数据效率:即使训练样本只有几百几千个,LaserTagger 也能生成合理的输出文本。实验显示,seq2seq 基线模型需要数万个样本才能实现类似性能。
登录查看更多
相关内容

Arxiv
3+阅读 · 2018年3月20日




相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2018年3月20日