想效仿英伟达50分钟训练 BERT?只有GPU还不够……
选自arXiv
作者:Mohammad Shoeybi 等
机器之心编译
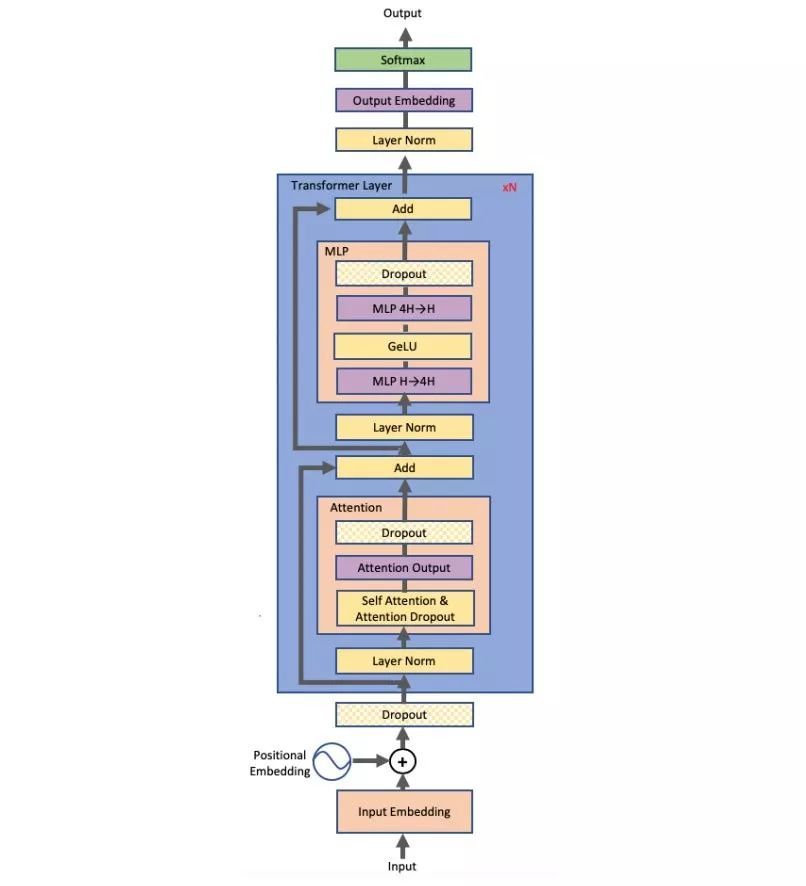
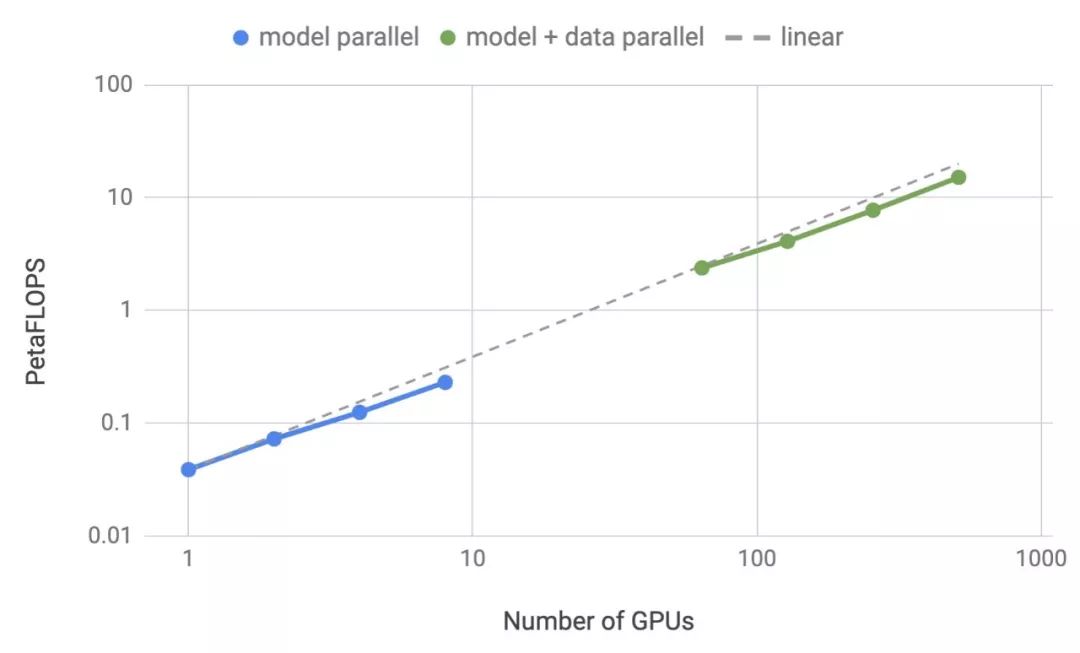
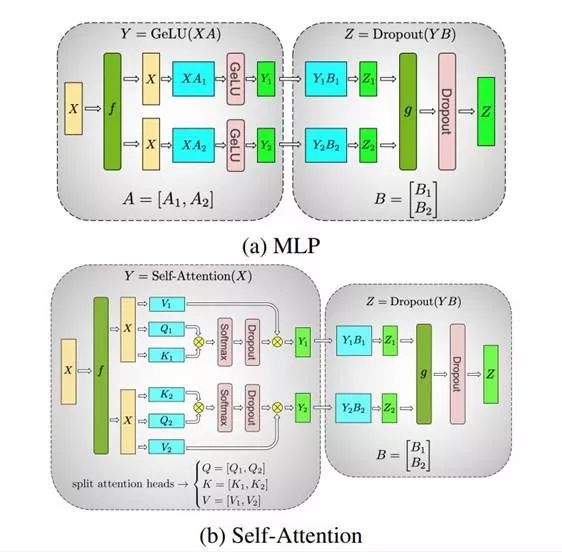
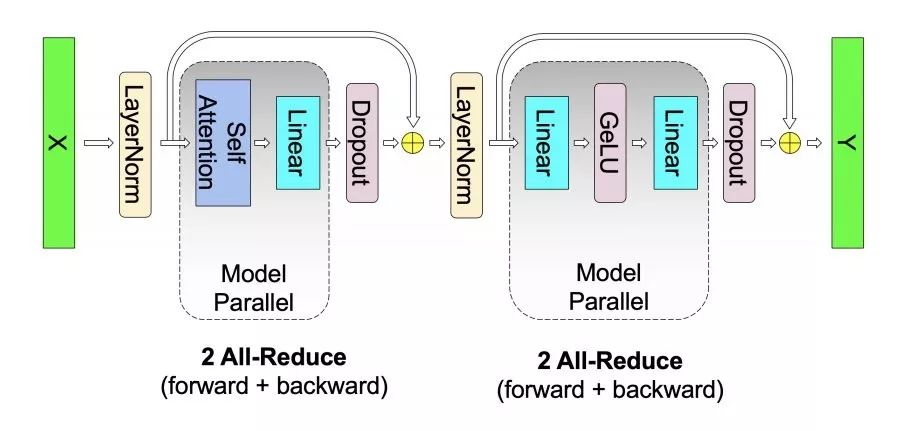
此前,机器之心曾经介绍过英伟达的一项研究,打破了 NLP 领域的三项记录:将 BERT 的训练时间缩短到了 53 分钟;将 BERT 的推理时间缩短到了 2.2 毫秒;将 GPT-2 的参数量推向 80 亿(之前 GPT-2 最大为 15 亿参数量)。很多人将此成绩归结为英伟达的优越硬件条件,反正 GPU 有的是。其实不然,英伟达近期的一篇论文公布了该研究中采用的模型并行化方法:层内模型并行化。该方法无需新的编译器或库更改,只需在 PyTorch 中嵌入几个通信操作即可完整实现。
论文地址:https://arxiv.org/abs/1909.08053v1
代码地址:https://github.com/NVIDIA/Megatron-LM
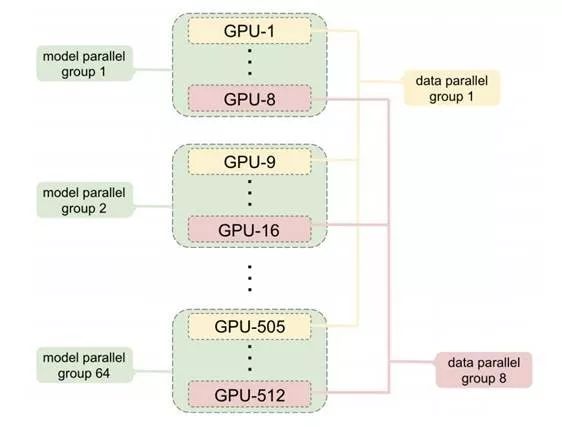
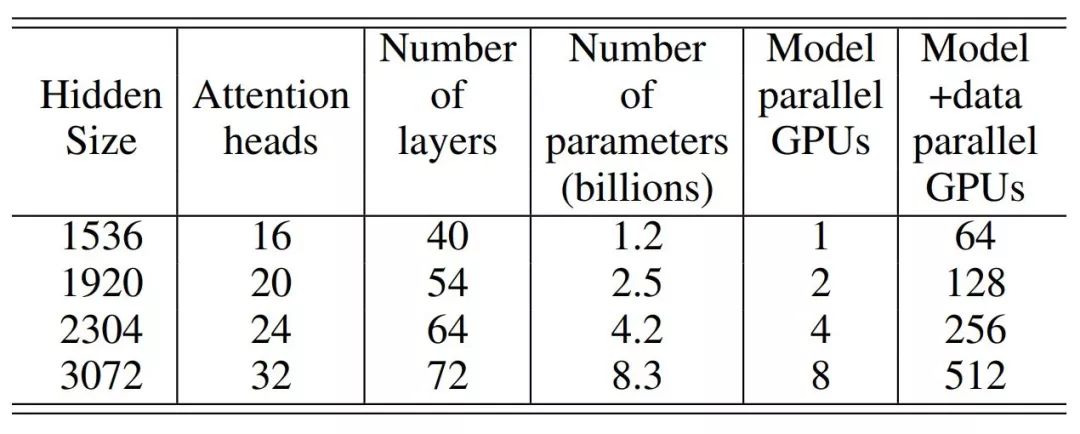
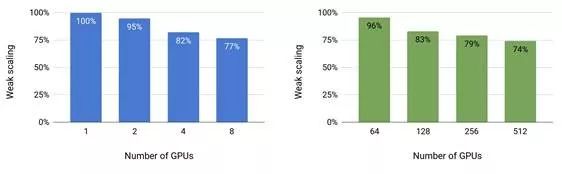

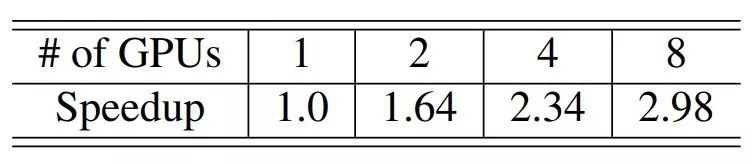
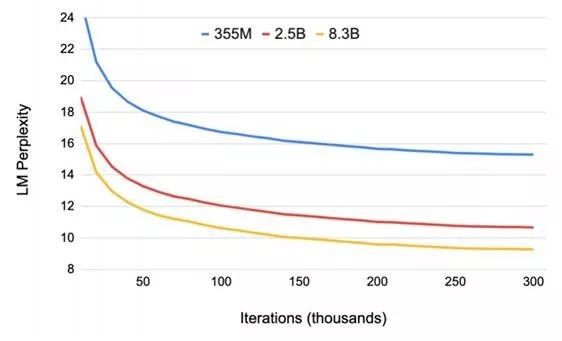
登录查看更多
相关内容

专知会员服务
36+阅读 · 2020年4月14日
专知会员服务
32+阅读 · 2020年2月21日
Arxiv
11+阅读 · 2019年10月30日
Arxiv
15+阅读 · 2018年10月11日
Arxiv
5+阅读 · 2018年5月23日
相关主题




相关VIP内容
专知会员服务
36+阅读 · 2020年4月14日
专知会员服务
32+阅读 · 2020年2月21日
相关资讯
相关论文
Arxiv
11+阅读 · 2019年10月30日
Arxiv
15+阅读 · 2018年10月11日
Arxiv
5+阅读 · 2018年5月23日