XLNet太贵?这位小哥在PyTorch Wrapper上做了个微缩版的

新智元报道
新智元报道
来源:arxiv、知乎等
编辑:大明
【新智元导读】XLNet虽然好用,但实在太费钱了!近日,一位韩国小哥成功将简化版的XLNet在PyTorch Wrapper实现,批规模仅为1,不再依赖谷歌爸爸的巨额算力,让“穷人”也能用得起。
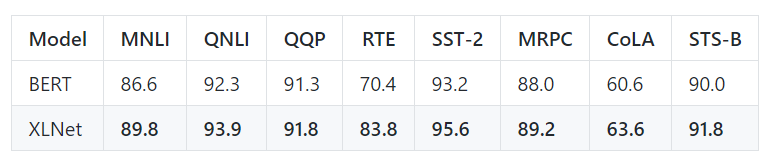
不久前,谷歌大脑和CMU联合团队提出面向NLP预训练新方法XLNet,性能全面超越此前NLP领域的黄金标杆BERT,在20个任务上实现了性能的大幅提升,刷新了18个任务上的SOTA结果,可谓全面屠榜。

论文地址:
https://arxiv.org/pdf/1906.08237.pdf
XLNet性能确实强大,不过还是要背靠谷歌TPU平台的巨额算力资源。有网友做了一下简单统计,按照论文中的实验设计,XL-Large用512 TPU chips训练了4天,也就是说,训练时的总计算量是BERT的5倍。语料规模是BERT-large的10倍。

要知道BERT作为谷歌的亲儿子,其训练量和对计算资源的需求已经让很多人望尘莫及。现在XLNet又来了个5倍,让人直呼用不起。
这么强劲的XLNet,只能看着流口水却用不起,岂不是太遗憾了?
土豪有土豪的用法,穷人有穷人的诀窍。最近有个韩国小哥就成功将XLNet挪到了Pytorch框架上,可以在仅使用小规模训练数据(批规模=1)的情况下,实现一个简单的XLNet实例,并弄清XLNet架构的预训练机制。他将实现方案放在了GitHub上。
要使用这个实现很简单,只需导入如下代码:
$ git clone https://github.com/graykode/xlnet-Pytorch && cd xlnet-Pytorch
# To use Sentence Piece Tokenizer(pretrained-BERT Tokenizer)
$ pip install pytorch_pretrained_bert
$ python main.py --data ./data.txt --tokenizer bert-base-uncased \
--seq_len 512 --reuse_len 256 --perm_size 256 \
--bi_data True --mask_alpha 6 --mask_beta 1 \
--num_predict 85 --mem_len 384 --num_step 100
接下来对实现方法和超参数设置的简单介绍,首先贴出XLNet论文中给出的预训练超参数:
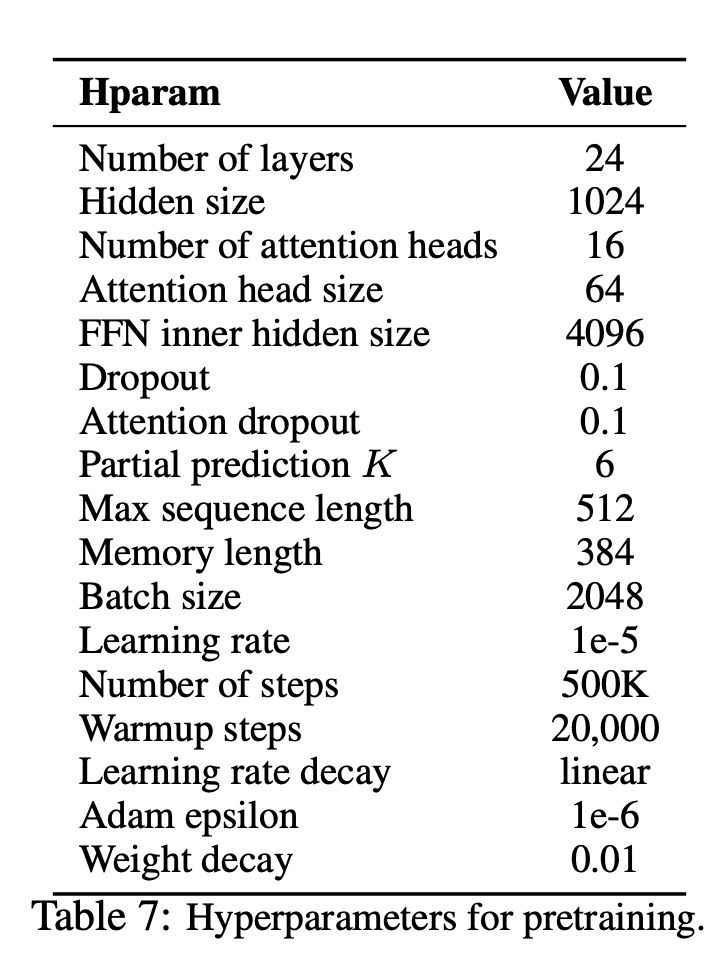
然后,作者给出了PyTorch框架下XLNet实现的超参数调节选项如下:
—data(String) : 使用文本文件训练,多行文本也可以。另外,将一个文件视为一个批张量。默认值: data.txt
—tokenizer(String) :目前仅使用【这里】的Tokenizer作为子词的Tokenizer(即将编入句子部分),这里可以选择bert-base-uncased/bert-large-uncased/bert-base-cased/bert-large-cased四种Tokenizer。
默认值: bert-base-uncased
—seq_len(Integer) : 序列长度。
默认值 : 512
—reuse_len(Interger) : 可作为记忆重复使用的token数量。可能是序列长度的一半。
默认值 : 256
—perm_size(Interger) : 最长排列长度。
默认值: 256
--bi_data(Boolean) : 是否设立双向数据,如设置为“是”,biz(batch size) 参数值应为偶数。
默认值: 否
—mask_alpha(Interger) : 多少个token构成一个group。
默认值: 6
—mask_beta(Integer) :在每个group中需要mask的token数量。
默认值: 1
—num_predict(Interger) :
要预测的token数量。在XLNet论文中, 这表示部分预测。
默认值: 85
—mem_len(Interger) : 在Transformer-XL架构中缓存的步骤数量。
默认值: 384
—number_step(Interger) :步骤(即Epoch)数量.。
默认值: 100
XLNet是一种基于新型广义置换语言建模目标的新型无监督语言表示学习方法。此外,XLNet采用Transformer-XL作为骨架模型,在长时间环境下的语言任务中表现出非常出色的性能,在多项NLP任务性能上超越了BERT,成为NLP领域的新标杆。
1、自回归模型与自动编码模型
自回归(AR)模型
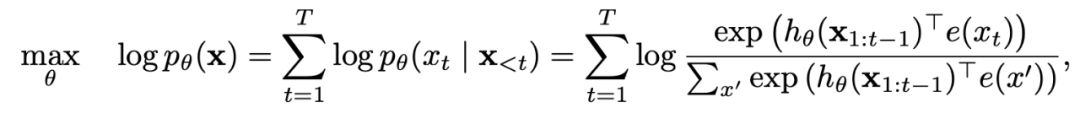
自动编码(AE)模型
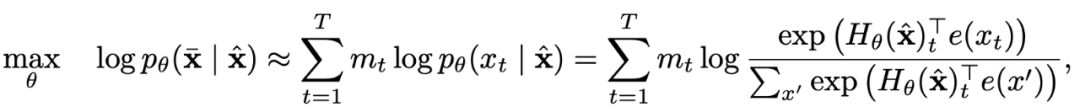
2、部分预测的排列语言建模
排列语言建模
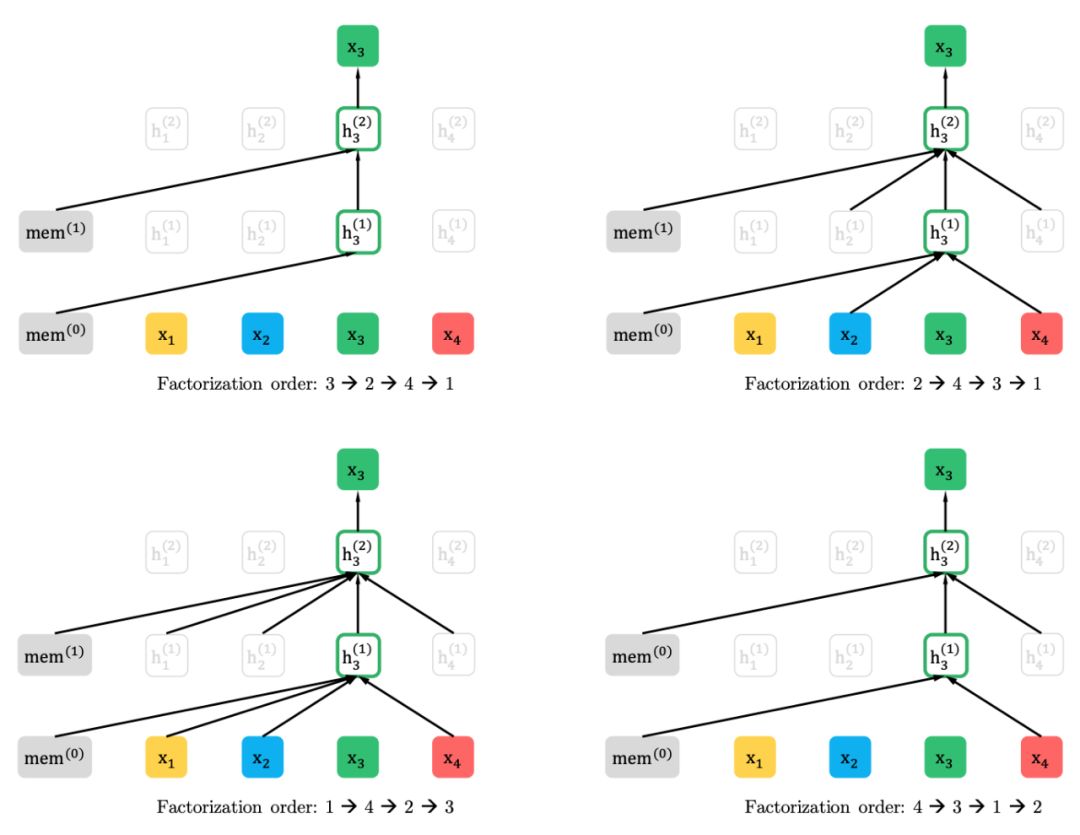
部分预测
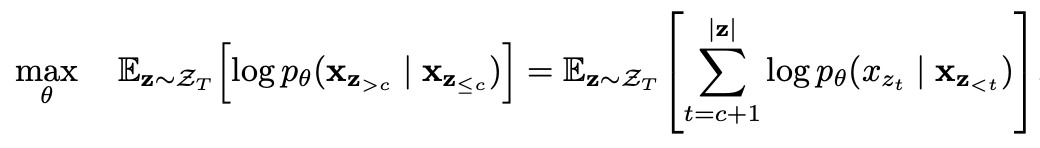
3、具有目标感知表示的双向自注意力模型
双向自注意力模型
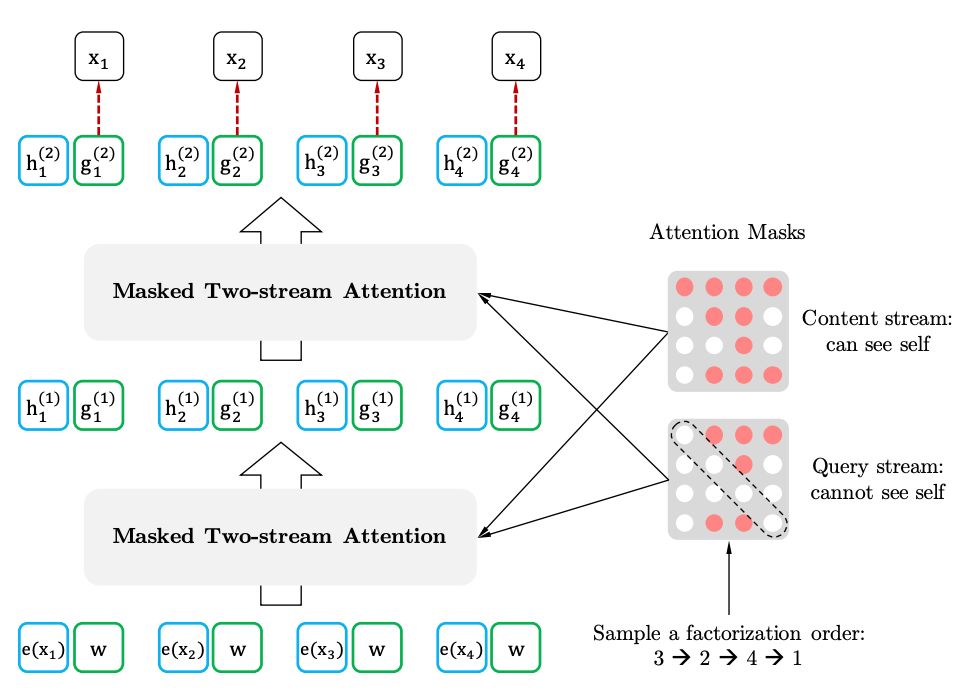
目标感知表示
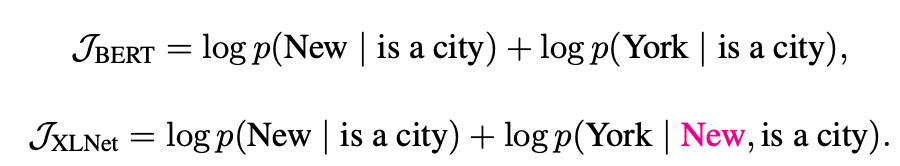
参考链接:
GitHub:
https://github.com/graykode/xlnet-Pytorch
XLNet论文:
https://arxiv.org/pdf/1906.08237.pdf







