Perseus-BERT——业内性能极致优化的BERT训练方案

作者: 笋江 驭策 蜚廉 昀龙
一、背景——横空出世的BERT全面超越人类
2018年在自然语言处理(NLP)领域最具爆炸性的一朵“蘑菇云”莫过于Google Research提出的BERT(Bidirectional Encoder Representations from Transformers)模型。作为一种新型的语言表示模型,BERT以“摧枯拉朽”之势横扫包括语言问答、理解、预测等各项NLP锦标的桂冠,见图1和图2。
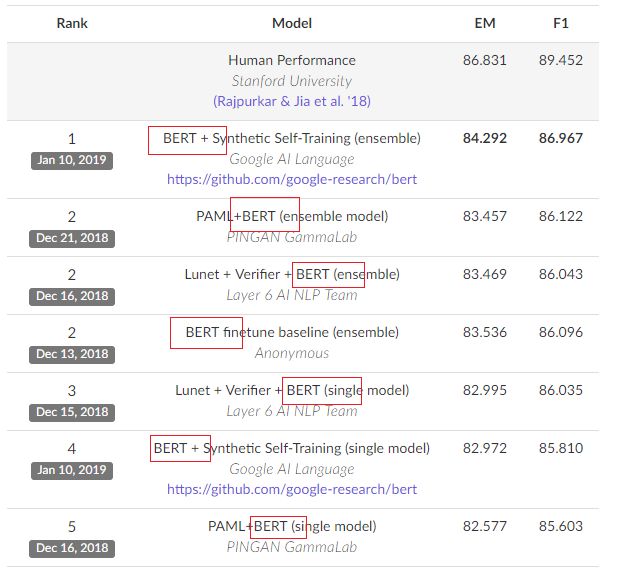
【图1】SQuAD是基于Wikipedia文章的标准问答数据库的NLP锦标。目前SQuAD2.0排名前十名均为基于BERT的模型(图中列出前五名),前20名有16席均是出自BERT
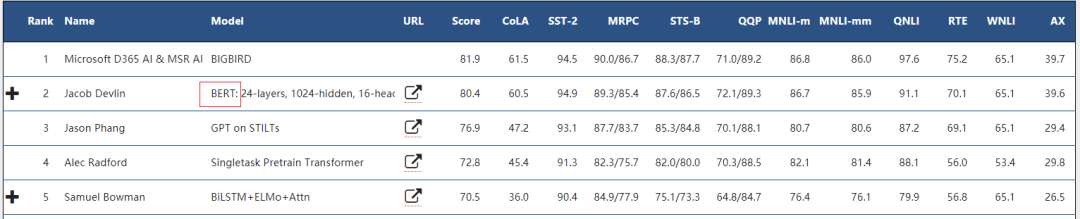
【图2】GLUE是一项通用语言理解评估的benchmark,包含11项NLP任务。BERT自诞生日起长期压倒性霸占榜首(目前BERT排名第二,第一为Microsoft提交的BIGBIRD模型,由于没有URL链接无从知晓模型细节,网传BIGBIRD的名称上有借鉴BERT BIG模型之嫌)
业内将BERT在自然语言处理的地位比作ResNet之于计算机视觉领域的里程碑地位。在BERT横空出世之后,所有的自然语言处理任务都可以基于BERT模型为基础展开。
一言以蔽之,现如今,作为NLP的研究者,如果不了解BERT,那就是落后的科技工作者;作为以自然语言处理为重要依托的科技公司,如果不落地BERT,那就是落后生产力的代表。
二、痛点——算力成为BERT落地的拦路虎
BERT强大的原因在哪里?让我们拂去云霭,窥探下硝烟下的奥秘。
BERT模型分为预训练模型(Pretrain)和精调模型(Finetune)。Pretrain模型为通用的语言模型。
Finetune只需要在Pretrain的基础上增加一层适配层就可以服务于从问答到语言推理等各类任务,无需为具体任务修改整体模型架构,如图3所示。这种设计方便BERT预处理模型适配于各类具体NLP模型(类似于CV领域基于ImageNet训练的各种Backbone模型)。
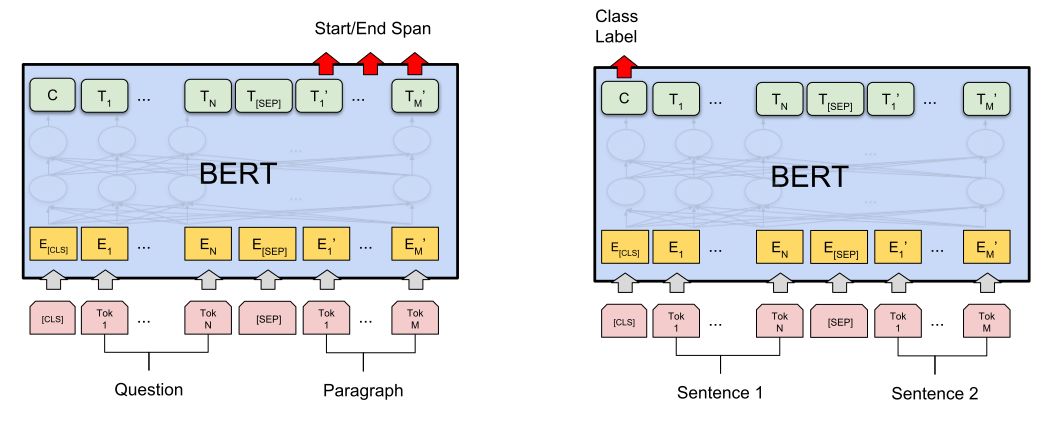
【图3】左图基于BERT pretrain的模型用于语句问答任务(SQuAD)的finetune模型,右图为用于句对分类(Sentence Pair Classification Tasks)的finetune模型。他们均是在BERT Pretrain模型的基础上增加了一层具体任务的适配层
因此,BERT的强大主要归功于精确度和鲁棒性俱佳的Pretrain语言模型。大部分的计算量也出自Pretrain模型。其主要运用了以下两项技术,都是极其耗费计算资源的模块。
双向Transformer架构
图4可见,与其他pre-training的模型架构不同,BERT从左到右和从右到左地同时对语料进行transformer处理。这种双向技术能充分提取语料的时域相关性,但同时也大大增加了计算资源的负担。【关于Transformer是Google 17年在NLP上的大作,其用全Attention机制取代NLP常用的RNN及其变体LSTM等的常用架构,大大改善了NLP的预测准确度。本文不展开,该兴趣的同学可以自行搜索一下】。
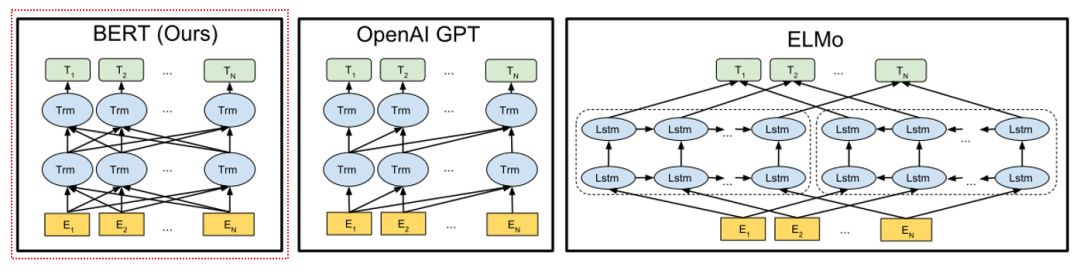
【图4】Pretrain架构对比。其中OpenAI GPT采用从左到右的Transformer架构,ELMo采用部分从左到右和部分从右到左的LSTM的级联方式。BERT采用同时从左到右和从右到左的双向Transformer架构。
词/句双任务随机预测
BERT预训练模型在迭代计算中会同时进行单词预测和语句预测两项非监督预测任务。
其一,单词预测任务对语料进行随机MASK操作(Masked LM)。在所有语料中随机选取15%的单词作为Mask数据。被选中Mask的语料单词在迭代计算过程中80%时间会被掩码覆盖用于预测、10%时间保持不变、10%时间随机替换为其他单词,如图5所示。
其二,语句预测任务(Next Sentence Prediction)。对选中的前后句A和B,在整个迭代预测过程中,50%的时间B作为A的真实后续语句(Label=IsNext),另外50%的时间则从语料库里随机选取其他语句作为A的后续语句(Label=NotNext),如图5所示

【图5】词/句双任务随机预测输入语料实例。蓝框和红框为同一个语料输入在不同时刻的随机状态。对单词预测任务,蓝框中的“went”为真实数据,到了红框则被[MASK],红框中的“the” 则相反;对于语句预测任务,蓝框中的句组为真实的前后句,而红框中的句组则为随机的组合。
这种随机选取的单词/语句预测方式在功能上实现了非监督数据的输入的功能,有效防止模型的过拟合。但是按比例随机选取需要大大增加对语料库的迭代次数才能消化所有的语料数据,这给计算资源带来了极大的压力。
综上,BERT预处理模型功能需要建立在极强的计算力基础之上。BERT论文显示,训练BERT BASE 预训练模型(L=12, H=768, A=12, Total Parameters=110M, 1000,000次迭代)需要1台Cloud TPU工作16天;而作为目前深度学习主流的Nvidia GPU加速卡面对如此海量的计算量更是力不从心。即使是目前主流最强劲的Nvidia V100加速卡,训练一个BERT-Base Pretrain模型需要一两个月的时间。而训练Large模型,需要花至少四五个月的时间。
http://timdettmers.com/2018/10/17/tpus-vs-gpus-for-transformers-bert/
花几个月训练一个模型,对于绝大部分在GPU上训练BERT的用户来说真是伤不起。
三、救星——擎天云加速框架为BERT披荆斩棘
阿里云弹性人工智能团队依托阿里云强大的基础设施资源打磨业内极具竞争力的人工智能创新方案。基于BERT的训练痛点,团队打造了擎天优化版的Perseus-BERT, 极大地提升了BERT pretrain模型的训练速度。在云上一台V100 8卡实例上,只需4天不到即可训练一份BERT模型。
Perseus-BERT是如何打造云上最佳的BERT训练实践?以下干货为您揭秘Perseus-BERT的独门绝技。
1. Perseus 统一分布式通信框架 —— 赋予BERT分布式训练的轻功
Perseus(擎天)统一分布式通信框架是团队针对人工智能云端训练的痛点,针对阿里云基础设施极致优化的分布式训练框架。其可轻便地嵌入主流人工智能框架的单机训练代码,在保证训练精度的同时高效地提升训练的多机扩展性。擎天分布式框架的干货介绍详见团队另一篇文章《Perseus(擎天):统一深度学习分布式通信框架》。
针对tensorflow代码的BERT,Perseus提供horovod的python api方便嵌入BERT预训练代码。基本流程如下:
让每块GPU对应一个Perseus rank进程;
对global step和warmup step做基于rank数的校准;
对训练数据根据rank-id做划分;
给Optimizer增加DistributeOptimizer的wrapper。
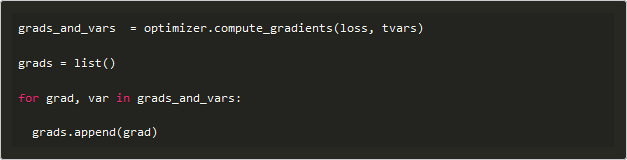
值得注意的是,BERT源码用的自定义的Optimizer,在计算梯度时采用了以下api

Perseus的DistributeOptimizer继承标准的Optimizer实现,并在`compute_gradients` api 上实现分布式的梯度更新计算。因此对grads获取做了如下微调
2. 混合精度训练和XLA编译优化——提升BERT单机性能的内功
混合精度
在深度学习中,混合精度训练指的是float32和float16混合的训练方式,一般的混合精度模式如图6所示
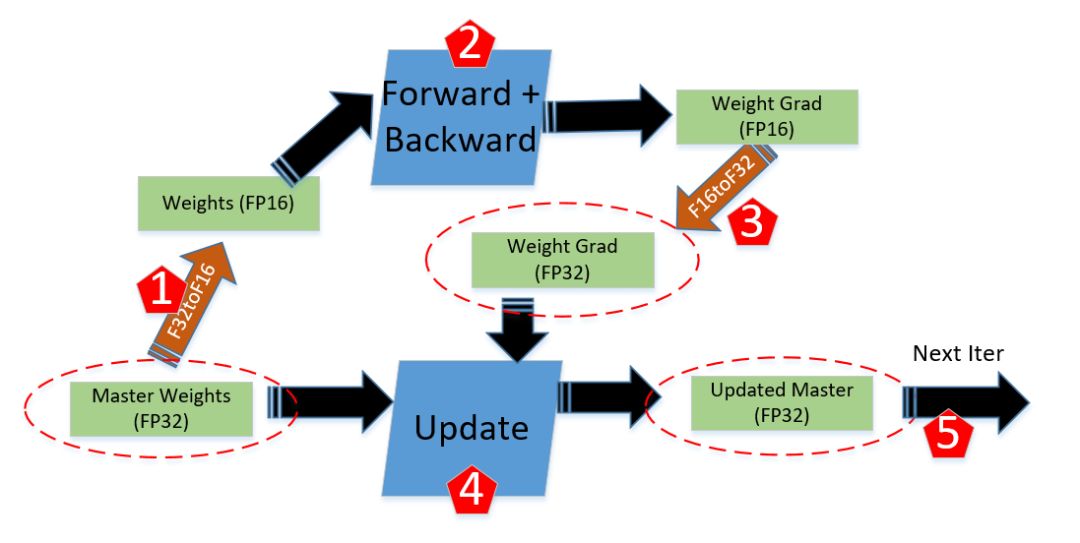
【图6】混合精度训练示例。在Forward+Backward计算过程中用float16做计算,在梯度更新时转换为float32做梯度更新。
混合梯度对Bert训练带来如下好处,
增大训练时的batch size和sequence_size以保证模型训练的精度。
目前阿里云上提供的主流的Nvidia显卡的显存最大为16GB,对一个BERT-Base模型在float32模式只能最高设置为sequence_size=256,batch_size=26。BERT的随机预测模型设计对sequence_size和batch_size的大小有一定要求。为保证匹配BERT的原生训练精度,需要保证sequece_size=512的情况下batch_size不小于16。Float16的混合精度可以保证如上需求。
混合精度能充分利用硬件的加速资源。
NVidia从Volta架构开始增加了Tensor Core资源,这是专门做4x4矩阵乘法的fp16/fp32混合精度的ASIC加速器,一块V100能提供125T的Tensor Core计算能力,只有在混合精度下计算才能利用上这一块强大的算力。
受限于float16的表示精度,混合精度训练的代码需要额外的编写,NVidia提供了在Tensorflow下做混合精度训练的教程 。其主要思路是通过tf.variable_scope的custom_getter 参数保证存储的参数为float32并用float16做计算。
在BERT预训练模型中,为了保证训练的精度,Perseus-BERT没有简单的利用custom_getter参数,而是显式指定训地参数中哪些可以利用float16不会影响精度,哪些必须用float32已保证精度。我们的经验如下:
Embedding部分要保证float32精度;
Attetion部分可以利用float16加速;
Gradients相关的更新和验证需要保证float32精度;
非线性激活等模块需要保证float32精度。
XLA编译器优化
XLA是Tensorflow新近提出的模型编译器,其可以将Graph编译成IR表示,Fuse冗余Ops,并对Ops做了性能优化、适配硬件资源。然而官方的Tensorflow release并不支持xla的分布式训练,为了保证分布式训练可以正常进行和精度,我们自己编译了带有额外patch的tensorflow来支持分布式训练,Perseus-BERT 通过启用XLA编译优化加速训练过程并增加了Batch size大小。
3. 数据集预处理的加速
Perseus BERT 同时对文本预处理做的word embedding和语句划分做了并行化的优化。这里就不展开说明。
四、性能——计算时间单位从月降低到天
图7展示了Perseus BERT在P100实例上的性能,与开源主流的horovod相比,Peseus-BERT双机16卡的分布式性能是前者的5倍之多。
目前某大客户已在阿里云P100集群上大规模上线了Perseus BERT,用10台4卡P100只需要2.5天即可训练完成业务模型,如果用开源的horovod(Tensorflow分布式性能优化版)大概需要1个月的时间。
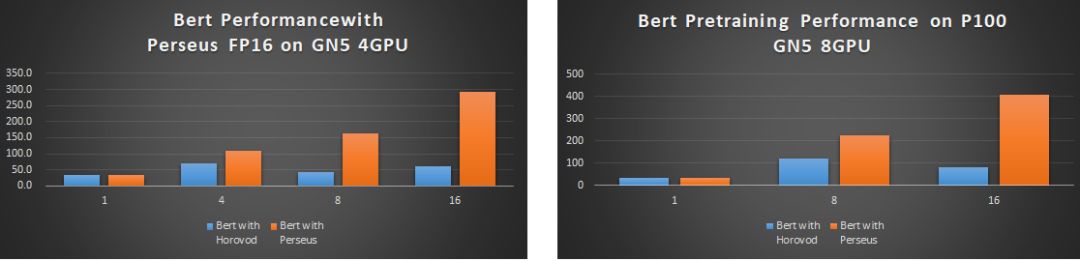
【图7】Bert在阿里云上P100实例的对比(实验环境Bert on P100; Batch size: 22 ;Max seq length: 256 ;Data type:float32; Tensorflow 1.12; Perseus: 0.9.1;Horovod: 0.15.2)
为了和Google TPU做对比,我们量化了TPU的性能,性能依据如图8。一个Cloud TPU可计算的BERT-Base性能 256 *(1000000/4/4/24/60/60) = 185 exmaples/s。 而一台阿里云上的V100 单机八卡实例在相同的sequence_size=512下, 通过Perseus-BERT优化的Base模型训练可以做到 680 examples/s,接近一台Cloud TPU的4倍性能。对一台Cloud TPU花费16天才能训练完的BERT模型,一台阿里云的V100 8卡实例只需要4天不到便可训练完毕。

【图8】BERT Pretain在Google Cloud TPU上的性能依据
五、总结——基于阿里云基础设施的AI极致性能优化
弹性人工智能团队一直致力基于阿里云基础设施的AI极致性能优化的创新方案。Perseus-BERT就是一个非常典型的案例,我们在框架层面上基于阿里云的基础设施做深度优化,充分释放阿里云上基础资源的计算能力,让阿里云的客户充分享受云上的AI计算优势,让天下没有难算的AI。
更多精彩



赠书啦,2月值得一读的10本技术书(Python、算法、设计等书籍)!

如果觉得本文还不错,点击好看一下!




