华为诺亚方舟实验室的研究者提出了一个大规模的中文的跨模态数据库 ——「悟空」,并在此基础上对不同的多模态预训练模型进行基准测试,有助于中文的视觉语言预训练算法开发和发展。
在大数据上预训练大规模模型,对下游任务进行微调,已经成为人工智能系统的新兴范式。BERT 和 GPT 等模型在 NLP 社区中越来越受欢迎,因为它们对广泛的下游任务甚至零样本学习任务具有很高的可迁移性,从而产生了 SOTA 性能。最近的工作,如 CLIP、ALIGN 和 FILIP 进一步将这一范式扩展到视觉语言联合预训练 (VLP) 领域,并在各种下游任务上显示出优于 SOTA 方法的结果。这一有希望的方向引起了行业和研究人员的极大关注,将其视为通向下一代 AI 模型的途径。
促成 VLP 模型成功的原因有两个。一方面,更高级的模型架构(如 ViT/BERT)和训练目标(如对比学习)通常能够提升模型泛化能力和学得表示的稳健性。另一方面,由于硬件和分布式训练框架的进步,越来越多的数据可以输入到大规模模型中,来提高模型的泛化性、可迁移性和零样本能力。在视觉或者语言任务中,先在大规模数据(例如图像分类中的 JFT-300M、T5 中的 C4 数据集)上预训练,之后再通过迁移学习或者 prompt 学习已被证明对提高下游任务性能非常有用。此外,最近的工作也已经显示了 VLP 模型在超过 1 亿个来自网络的有噪声图像 - 文本对上训练的潜力。
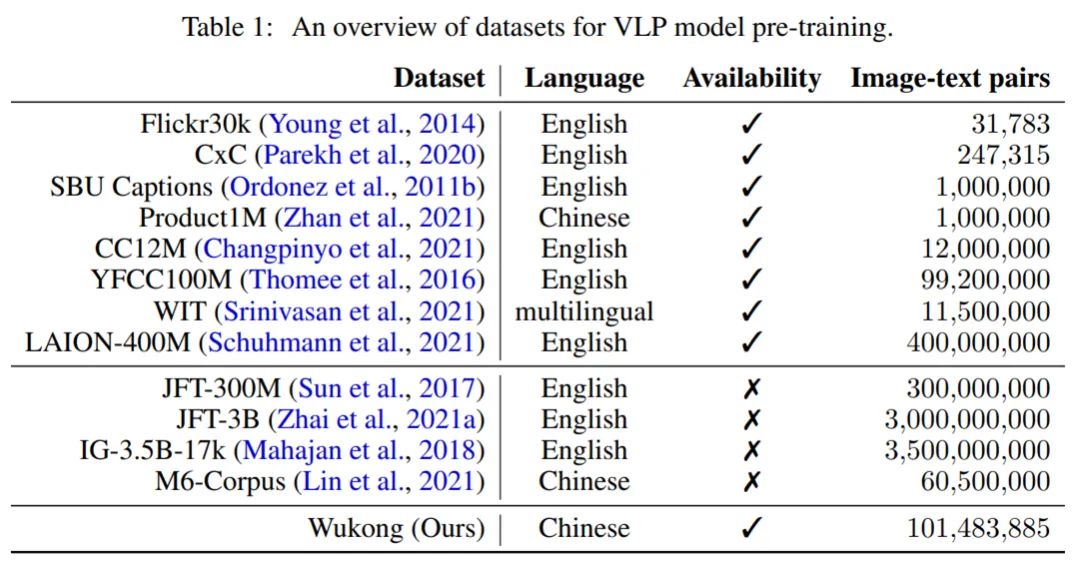
因此,在大规模数据上预训练的 VLP 模型的成功促使人们不断地爬取和收集更大的图文数据集。下表 1 显示了 VLP 领域中许多流行的数据集的概述。诸如 Flickr30k、SBU Captions 和 CC12M 等公开可用的视觉语言(英语)数据集的样本规模相对较小(大约 1000 万),而规模更大的是像 LAION-400M 的数据集。但是,直接使用英文数据集来训练模型会导致中文翻译任务的性能大幅下降。比如,大量特定的中文成语和俚语是英文翻译无法覆盖的,而机器翻译往往在这些方面会带来错误,进而影响任务执行。
![]()
目前,社区缺乏大规模公开可用的中文数据集,不仅导致社区发展受阻,而且每项工作都使用一个私密的大型数据集来实现,达到一个其它工作无法公平比较的惊人性能。
为了弥补这一差距,华为诺亚方舟实验室的研究者发布了一个名为「悟空」的大型中文跨模态数据集,其中包含来自网络的 1 亿个图文对。为了保证多样性和泛化性,悟空数据集是根据一个包含 20 万个高频中文单词列表收集的。本文还采用基于图像和基于文本的过滤策略来进一步完善悟空数据集,使其成为了迄今为止最大的中文视觉语言跨模态数据集。研究者分析了该数据集,并表明它涵盖了广泛的视觉和文本概念。
![]()
研究者还进一步发布了一组使用不同架构(ResNet/ViT/SwinT)和不同方法(CLIP、FILIP 和 LiT)大型预训练模型。
本文的主要贡献如下:
发布了具有 1 亿个图文对的大规模视觉和中文语言预训练数据集,涵盖了更全面的视觉概念;
发布了一组使用各种流行架构和方法预训练好的大规模视觉 - 语言模型,并提供针对已发布模型的全面基准测试;
发布的预训练模型在数个中文基准测试任务,例如由 17 个数据集组成的零样本图像分类任务和由 5 个数据集组成的图像文本检索任务,表现出了最优性能。
研究者构建了一个名为悟空的新数据集,该数据集包含从网络收集的 1 亿个图文对。为了涵盖足够多样的视觉概念,悟空数据集是由包含 20 万个词条的查询列表里收集的。这个基础查询列表取自 Yan Song 等人的论文《Directional Skip-Gram: Explicitly Distinguishing Left and Right Context for Word Embeddings》,然后根据华为的海量新闻文本语料库中出现的中文单词和短语的频率进行过滤后所得。
查询列表建好后,研究者在百度图片搜索每个查询,以获取图片 URL 列表和相应的标题信息。为了保持不同查询结果间的平衡,他们每个查询最多搜索 1000 个样本。然后使用先前获得的图像 URL 下载图像,最终共收集了 1.66 亿个图文对。然后按照惯例,研究者通过下文的一系列过滤策略来构建最终的悟空数据集。下图 2 显示了悟空数据集中的一些样本。
![]()
研究者首先根据图像的大小和长宽比对数据进行过滤。只保留长或宽超过 200 像素且长宽比不超过 3 的图像。这种方式过滤掉了太小、太高或太宽的图像,因为这些图像在预训练期间经过上采样和方形裁剪等图像增强手段后,可能变成低分辨率。
其次,为了使选择的样本具有对应图像的高质量中文描述,研究者根据图像所附文本的语言、长度和频率对数据进行进一步过滤。具体来说,他们首先检查了语言和长度,保留了包含至少一个但少于 32 个汉字的句子。同时还会丢弃无意义的图像描述,例如「000.jpg」。之后,与太多图片配对的文字通常与图片内容无关,例如「查看源网页」(View source page)、「展开全文」(Expand text)、「摄影部落」(Photography community)。实际中,研究者将此阈值设置为 10,即丢弃掉在收集的整个语料库中出现超过 10 次的图文对。
为了保护文本中出现的个人隐私,研究者将人名替换为特殊标记「< 人名 >」,此外,他们还构建了一个中文敏感词列表,包含敏感词的图文对也被丢弃。
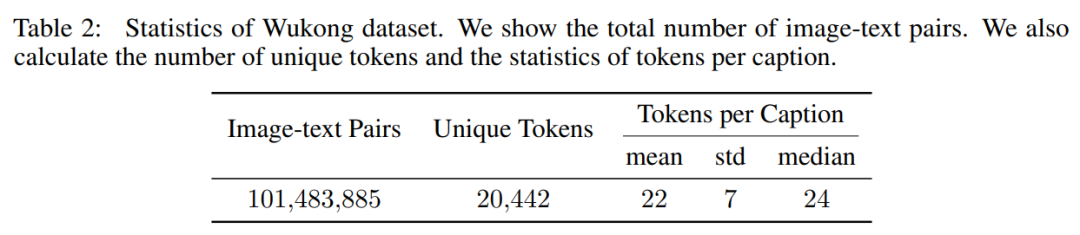
应用上述过滤策略后,研究者最终得到一个约 1 亿对的数据集。下表 2 显示了数据集的统计量:数据集文本中有 20,442 个唯一 token,每个描述中的平均 token 数为 22。
![]()
在下图 3 中,研究者可视化了数据集中单词(由一个或多个 token 组成)的分布。然后,他们使用中文文本分词工具 Jieba 来截取单词并构建数据集的词云。
![]()
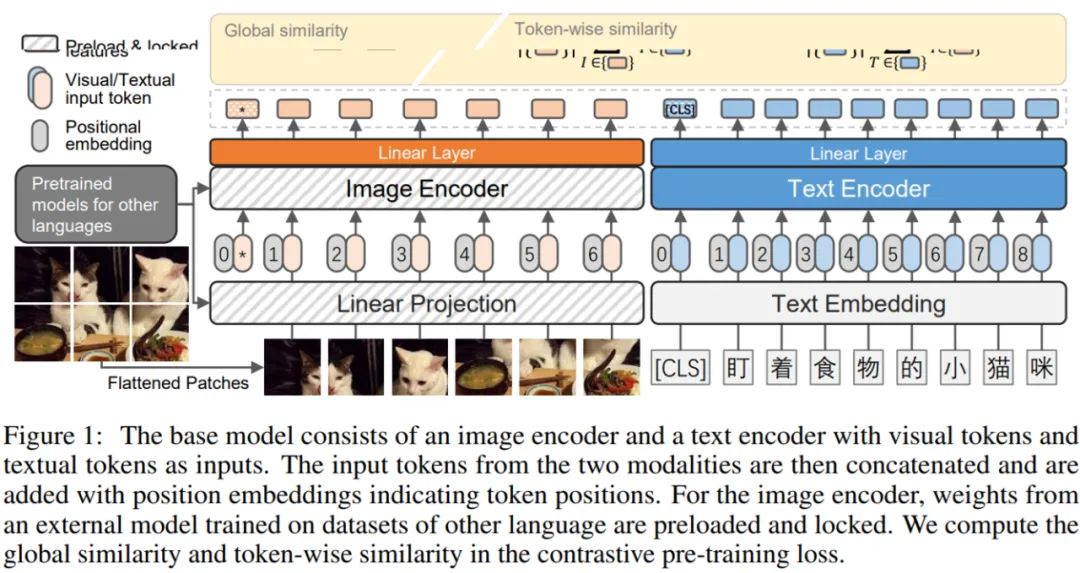
与最近经过充分验证的方法类似,研究者采用了对比预训练架构,如下图 1 所示。他们使用一个带有基于 Transformer 的文本和图像编码器的双流模型。这两个编码器将文本和视觉输入 token 转换为相同维度的嵌入。在这个学习到的联合嵌入空间中,研究者使用对比损失来鼓励成对的图像和文本具有相似的嵌入,而不成对的具有不同的嵌入。
![]()
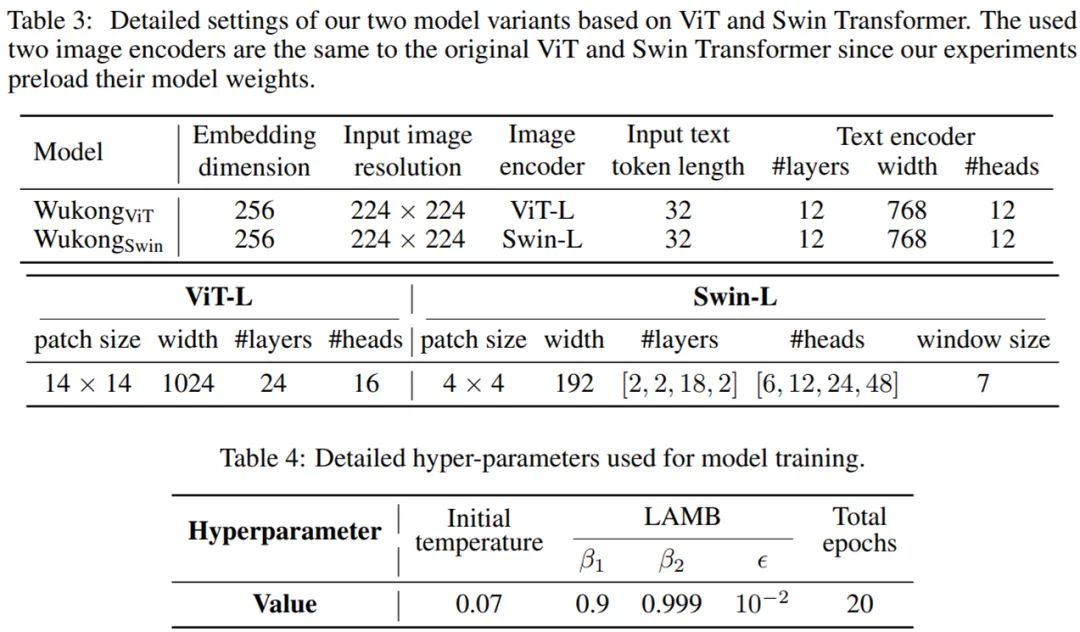
由于视觉和文本模态的编码器是解耦的,因此可以为这两种模态探索不同的编码器架构。研究者试验了三种视觉编码器变体(即 ResNet、Vision Transformer 和 Swin Transformer)以及一个单一的类 BERT 文本编码器来训练中文 VLP 模型。
跨模态对比学习是一种从成对的图像 - 文本数据中训练模型的特别有效的方法,它可以通过区分成对和不成对的样本同时学习两种模态的表示。研究者遵循 FILIP(Yao 等人,2022)中的公式标记,使用
![]() 去定义图像样本集合,同时
去定义图像样本集合,同时
![]() 代表文本数据。
给定一个图像样本
代表文本数据。
给定一个图像样本
![]() 和一个文本样本
和一个文本样本
![]() ,
该模型的目标是让联合多模态空间中的配对的图像和文本表示接近,不配对的则远离。
,
该模型的目标是让联合多模态空间中的配对的图像和文本表示接近,不配对的则远离。
在这项工作中,研究者探索了两种衡量图像和文本之间相似度的方法。图像和文本的学得表示分别标记为
![]() 和
和
![]() 。
这里,n_1 和 n_2 是每个图片和文本中的(未填充的)词 token 的数量。
。
这里,n_1 和 n_2 是每个图片和文本中的(未填充的)词 token 的数量。
研究者受到了最近提出的一种微调范式 LiT-tuning(Locked-image Text tuning)的启发,该范式表明权重固定的图像编码器和可学习的文本编码器在 VLP 模型中效果最好。他们在对比学习设置中也采用了同样的方式,即只更新文本编码器的权重,而不更新图像编码器的权重。
具体而言,研究者采用的 LiT-tuning 方法旨在教一个中文的文本编码器从一个现有的图像编码器中读取合适的表示,该图像编码器是在英文数据集上预训练过。他们还为每个编码器添加了一个可选的可学习线性变换层,它将两种模式的表示映射到相同的维度。LiT-tuning 之所以效果很好,是因为它解耦了用于学习图像特征和视觉语言对齐的数据源和技术(Zhai 等人,2021b)。并且,图像描述器事先使用相对干净或(半)手动标记的图像进行了良好的预训练。
研究者将这一想法扩展到多语言数据源,并尝试将在英文数据源上预训练的固定了的图像编码器和可训练的中文文本编码器对齐。此外,LiT-tuning 方法显著加快了训练过程并减少了内存需求,因为它不需要为视觉编码器计算梯度。
![]()
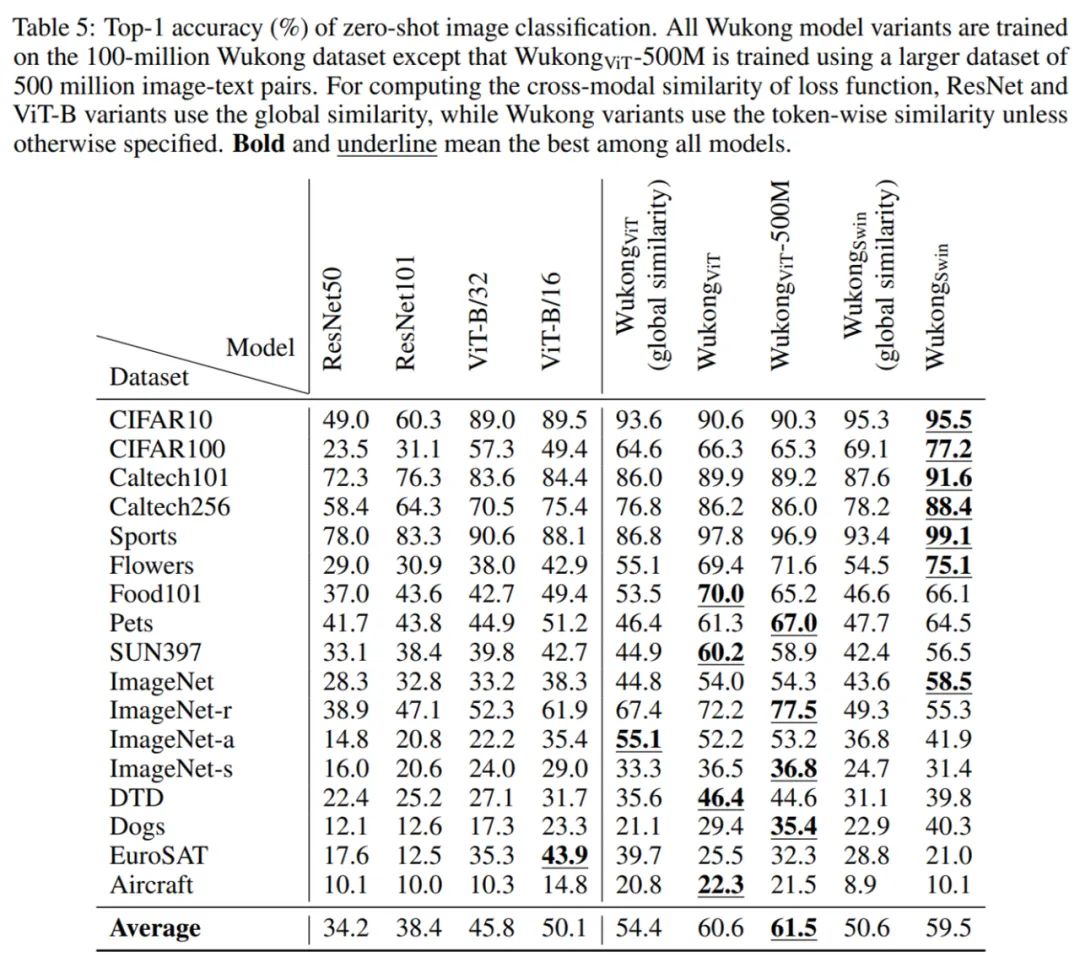
零样本图像分类
。研究者在 17 个零样本图像分类任务上评估预训练模型。零样本图像分类的结果如下表 5 所示。他们比较了使用不同视觉编码器的多个 LiT -tuning 模型,即从 CLIP 或 Swin Transformer 加载现有的视觉编码器并在训练阶段固定它们的权重。结果发现,使用 token 水平的相似度比使用全局相似度会带来更显著的改进。
![]()
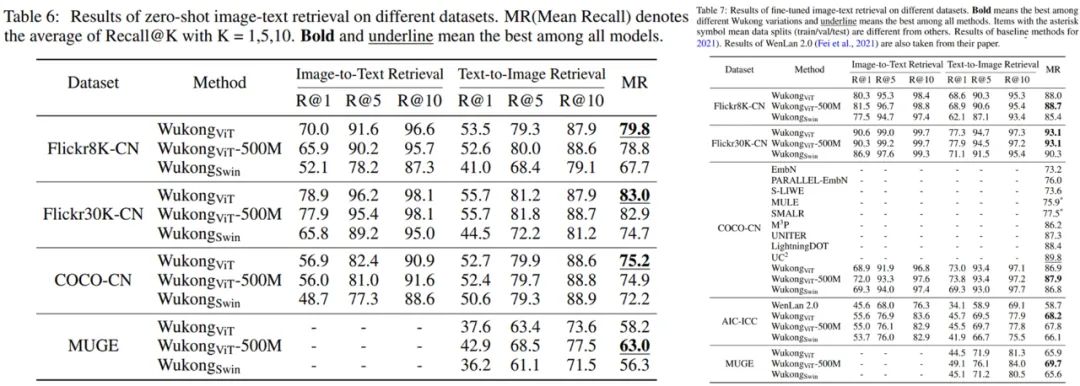
图文检索任务
。研究者在两个子任务,即以图搜文和以文搜图上做了评估。
下表 6 和表 7 分别显示了零样本设定和可以微调的图文检索的结果。
对于零样本设置,相比其它模型,Wukong_ViT 在 4 个数据集中的 3 个上取得了最好的结果,而 Wukong_ViT-500M 在更大的 MUGE 数据集上取得了最好的结果。
对于微调设置,Wukong_ViT-500M 则在除 AIC-ICC 之外的所有数据集上都取得了最好的结果,其中 Wukong_ViT 效果最好。
![]()
词汇 - 图块对齐的可视化
。研究者使用预训练模型 Wukong_ViT 和 Wukong_Swin 进 行可视化。如图 4 所示,其中可视化来自中文的 ImageNet 的六个标签(即豆娘、救生艇、蜂鸟、平板手机、教堂和电风扇)的图像。然后应用与 FILIP(Yao 等人,2022)相同的可视化方法来对齐文本和图块 token。
从下图 4 中,研究者发现两种模型都能够预测目标物体的图像块。对于具有更多图像块的 Wukong_ViT,这种词汇 - 图块对齐比 Wukong_Swin 更加细粒度。
![]()
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com



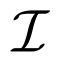 去定义图像样本集合,同时
去定义图像样本集合,同时
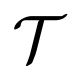 代表文本数据。
给定一个图像样本
代表文本数据。
给定一个图像样本
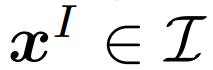 和一个文本样本
和一个文本样本
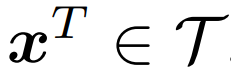 ,
该模型的目标是让联合多模态空间中的配对的图像和文本表示接近,不配对的则远离。
,
该模型的目标是让联合多模态空间中的配对的图像和文本表示接近,不配对的则远离。
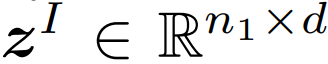 和
和
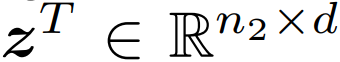 。
这里,n_1 和 n_2 是每个图片和文本中的(未填充的)词 token 的数量。
。
这里,n_1 和 n_2 是每个图片和文本中的(未填充的)词 token 的数量。