覆盖更多语言能力、任务和数据集,智源研究院为中文社区带来了一个全新的语言理解和生成评测基准——智源指数。
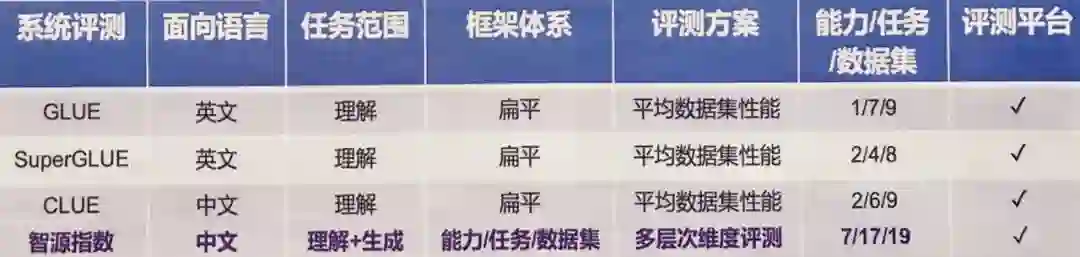
在自然语言处理(NLP)领域,预训练模型刷榜已经成为行业惯例。目前,面向英文任务的评测基准有 GLUE、SuperGLUE,面向中文任务的有 ChineseGLUE(简称 CLUE)。
但随着最近千亿、万亿参数大模型的不断涌现,这些基准所覆盖的语言能力、任务和数据集在验证模型性能时显得力不从心。特别是中文社区,亟需新的语言能力评测基准的出现。
12 月 30 日,智源人工智能研究院举办了自然语言处理重大研究方向前沿技术开放日活动,并发布了
中文语言理解和生成评测新基准——智源指数(CUGE,Chinese Language Understanding and Generation Evaluation)
。
这样一来,中文社区又多了一个评测语言大模型能力的选择。
![]()
清华大学教授、智源研究院自然语言处理(NLP)方向首席科学家孙茂松。
![]()
清华大学副教授、智源青年科学家、智源指数建设骨干成员刘知远。
智源指数包含了
高质量中文自然语言处理(NLP)数据集、排行榜与在线评测平台
,旨在构建全面系统的中文机器语言能力评测体系,形成多层次维度的评测方案,力求更加科学、规范、高质量地推进中文自然语言处理技术的标准评测。
智源指数还发布了相应技术报告《 CUGE: A Chinese Language Understanding and Generation Evaluation Benchmark》。
![]()
报告地址:http://cuge.baai.ac.cn/pdf/CUGE.pdf
目前,智源指数平台正在完善中,在在线评测网站上,研究人员可以浏览智源指数基准框架和数据集信息,下载数据集,并参与智源指数排行榜评测。
网站地址:http://cuge.baai.ac.cn/#/
机器学习语言能力需要科学有效的评测体系,评测基准在验证语言模型能力中发挥基础性和指导性作用。GLUE 、CLUE 等基准成为衡量大模型语言智能进展的重要标准。
但应看到,GLUE、CLUE 等偏重于语言理解能力,对语言生成、多语言、数学推理等其他重要语言能力有所忽视。评测框架体系呈现扁平化,过于专注平均数据集性能,覆盖的语言能力、任务和数据集也偏少。
![]()
因此,智源指数的定位是「中文语言理解和生成评测基准」,
按照「能力 - 任务 - 数据集」的层次结构筛选和组织高质量的代表性数据集,为机器语言能力提供更加全面系统和多层多维的评测标准
。
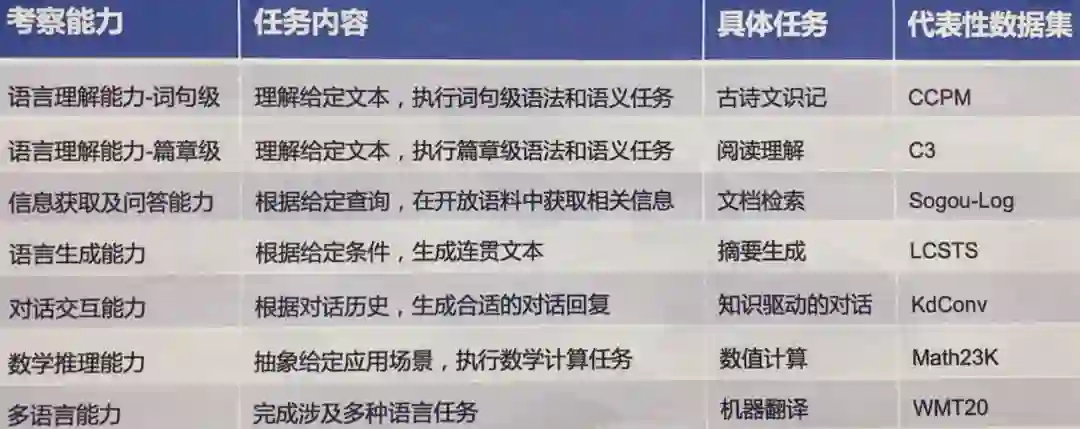
具体地,智源指数覆盖了
7 种重要语言能力
,分别为语言理解词句级、语言理解篇章级、信息获取及问答、语言生成、对话交互、多语言和数学推理。
![]()
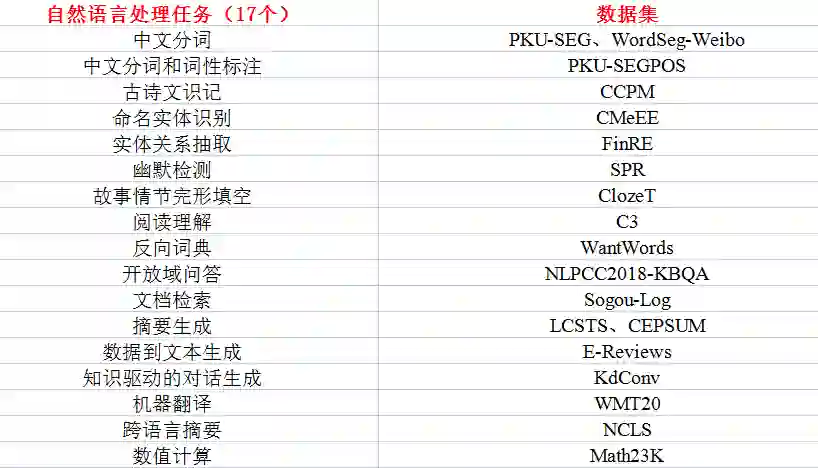
在这 7 种语言能力下,智源指数涵盖了
17 个主流自然语言处理任务
,可以总结如下:
这 17 个主流自然语言处理任务又有各自对应的数据集,共涵盖
19 个代表性数据集
。
![]()
为了方便快捷地评测模型能力,
智源指数还分别为每种语言能力选取了代表性任务和数据集,组成精简榜
。目前,精简榜提供了 mT5-small/large/XXL 和 CPM-2 的评测结果。
![]()
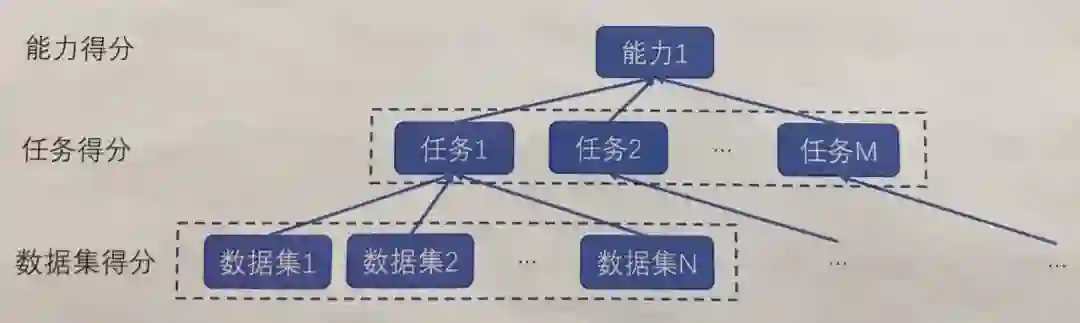
智源指数评测方案体现出了「多层次」和「归一化」两个特点。
一方面,在智源指数框架基础上,自底向上逐层汇总模型的数据集、任务、能力和总体得分;另一方面,以代表性基线模型得分为基准,归一化不同任务评测指标特性。
![]()
智源指数排行榜也很有特色
,比如使用多类型标签刻画数据集特点,支持用户通过标签筛选定制排行榜,利用雷达图直观可视化模型在不同语言能力的得分。智源指数支持单数据集排行榜,便于研究者追踪数据集研究进展动态。下图为语言理解能力 - 词句级下古诗文识记 CCPM 数据集的排行榜。
![]()
不仅如此,智源指数平台支持新数据集发布,指数定期吸纳单数据集排行榜中的优秀数据集。模型评测时要求提交者填写和展示 Honor Code,鼓励用户诚信,不人工干预数据训练和测试过程。未来,平台计划依托智源社区,提供用户面向数据集和评测结果的反馈意见和讨论机制。
在接受机器之心的采访时,刘知远认为,目前中文社区用于语言能力评测的基准太少,面向中文的自然语言处理缺少一个比较科学、有效且全面的评测基准。智源指数的出现有助于从学术界的角度更科学有效地构建一个评测体系,进而更好地指引中文预训练模型包括大模型发展的方向。
智源一直秉持开放的态度,希望全国甚至全世界做中文领域的自然语言数据结构,开发好的,新的数据集,支持他们在智源指数平台上发布,提供数据评测的支持。
刘知远最后表示,智源的目的是结合行业力量,把智源指数做好,让它回归构建这种评测基准的初心,即通过为包括大模型在内的预训练语言模型提供一个公正客观的评价体系和生态,对整个行业和领域的健康高效发展做出贡献。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com