百度与鹏城实验室联合发布全球首个知识增强千亿大模型——鹏城 - 百度 · 文心(ERNIE 3.0 Titan),是目前为止全球最大的中文单体模型。同时,百度产业级知识增强大模型 “文心” 全景图首次亮相。
从 15 亿参数的 GPT-2 到 1750 亿参数的 GPT-3,我们已经看到了模型规模增长和训练数据增加所带来的显著收益,其中最重要的一点就是对标注数据的依赖显著降低,这使得很多数据稀缺的场景也能用上性能强大的 AI 模型,为 AI 的大规模工业化应用扫清了障碍。
正如百度 CTO 王海峰所说,「人工智能将成为新一轮科技革命和产业变革的重要驱动力量。随着数据的井喷,算法的进步,算力的突破,效果好、泛化能力强、通用性强的预训练大模型成为人工智能发展的新方向。」驱动产业变革的前提是人工智能要在各行各业的各种场景下有很强的通用性,而预训练大模型刚好满足了此轮产业变革对通用性的要求。
作为国内人工智能的「头雁」,百度也很早就看到了这种通用性所蕴含的力量,并在过去的几年中研发了一系列大模型。不过,和业内很多大模型不同的是,百度的大模型都有一个特点——引入了「知识增强」。
众所周知,GPT-3 这类模型往往有一个缺点——缺乏常识。比如在被问及「我的脚有几个眼睛」时,它会回答「两个」。这一缺陷被业内称为「GPT-3 的阿喀琉斯之踵」。在具体的应用中,它会导致模型在一些涉及逻辑推理和认知的任务上表现较差。为了弥补这一缺点,不少研究引入了知识图谱,通过知识增强的方法提升语义模型的能力,百度文心就是其中的杰出代表。
文心 ERNIE 1.0
的诞生可以追溯到 2019 年 3 月,彼时,BERT 也才问世不到半年。和 BERT 不同的是,当时的文心 ERNIE 已经用上了知识增强的概念。
![]()
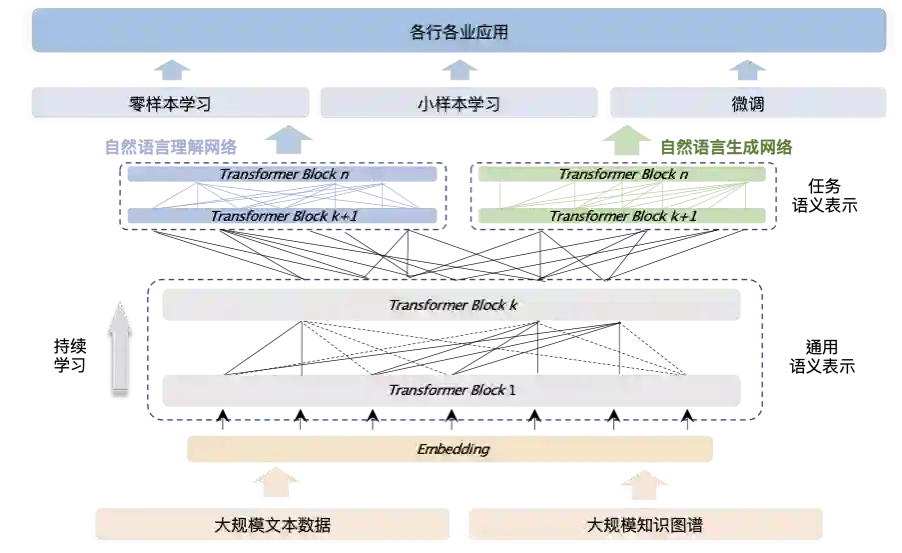
百度文心能够同时从百度积累的大规模知识和海量多元数据中持续学习,如同站在巨人的肩膀上,训练效率和理解准确率都得到大幅提升,并具备了更好的可解释性。除了将知识和数据融合学习,百度文心还通过知识增强跨语言学习与知识增强跨模态学习,从多种语言、多种模态数据中学习到统一的语义表示和理解能力,分化出了跨语言大模型 ERNIE-M 和跨模态大模型 ERNIE-ViL、ERNIE-ViLG 等一系列模型。这些模型组成了一个知识增强大模型矩阵。
今天,这一矩阵的完整图景首次亮相,它就是百度刚刚发布的「产业级知识增强大模型『文心』」。
![]()
百度文心全景既包含基础通用的知识增强跨语言大模型 ERNIE 3.0、知识增强跨模态理解大模型 ERNIE-M、知识增强跨模态生成大模型 ERNIE-ViL 等,也包含面向重点领域和重点任务的大模型,同时还有丰富的大模型开发工具、轻量化工具与 AI 开发平台支撑高效便捷的应用开发。
王海峰介绍说,「经过这几年的发展,百度文心大模型已经应用于很多行业,比如通信、金融、医疗、保险、证券、办公、互联网、物流等等。」
在全景图展示的众多模型中,有个模型不得不提,它就是语言理解与生成模型 ERNIE 3.0。
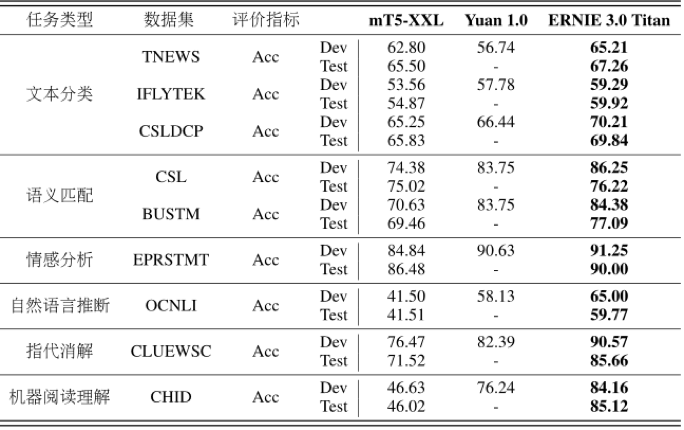
今年 7 月份,作为首个在百亿级预训练模型中引入大规模知识图谱的模型,ERNIE 3.0 一举刷新了 50 多个中文 NLP 任务基准,其英文模型还在 SuperGLUE 上以超越人类水平 0.8 个百分点的成绩登顶全球榜首。这一结果为 ERNIE 向千亿级知识增强预训练模型进发提供了依据。因此,在之后的几个月里,ERNIE 3.0 经历了新一轮的升级。
刚刚,中国工程院院士、鹏城实验室主任高文,百度首席技术官、深度学习技术及应用国家工程实验室主任王海峰共同公布了 ERNIE 3.0 升级的结果。新模型名叫鹏城 - 百度 · 文心(ERNIE 3.0 Titan),是全球首个知识增强千亿大模型,也是目前为止全球最大的中文单体模型。
![]()
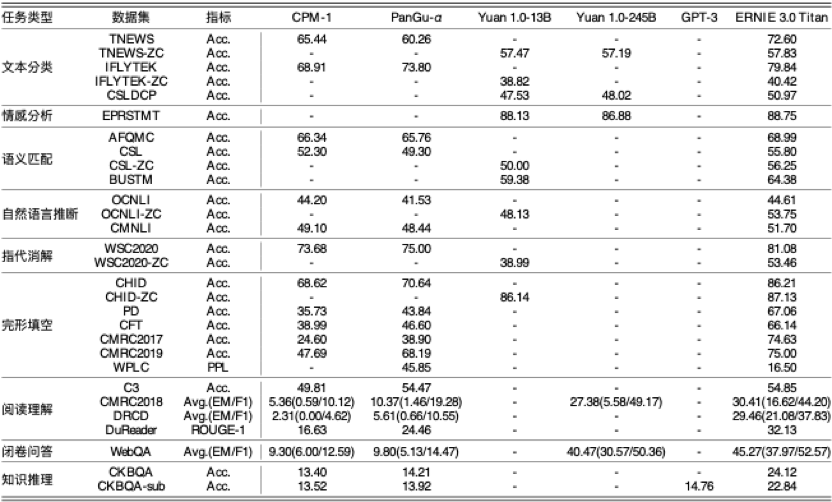
具体来说,鹏城 - 百度 · 文心是一款融合了自然语言理解和自然语言生成的全能模型,其参数量达到了 2600 亿,相对 GPT-3 的参数量提升 50%。而且,作为单体模型,该模型在实际运算中参与计算的参数可以达到稀疏大模型的百倍以上。
鹏城 - 百度 · 文心已在机器阅读理解、文本分类、语义相似度计算等 60 多项任务中取得最好效果。此外,模型还在 30 余项小样本和零样本任务中取得了世界领先的成绩。
![]()
![]()
从 GPT-3 到鹏城 - 百度 · 文心,千亿大模型的训练、推理从来都不是容易的事,需要算力、框架的软硬配合和算法、落地方面的综合优化。在今天的「鹏城 - 百度 · 文心大模型发布仪式」上,百度 CTO 王海峰介绍了鹏城 - 百度 · 文心的诞生过程。
OpenAI 之所以能训练出 GPT-3,算力是首先要满足的条件。微软 2020 年公布的信息显示,他们专门为 OpenAI 打造的超级计算机拥有 285,000 个 CPU 核以及 10,000 个 GPU,供 OpenAI 在上面训练所有的 AI 模型。
鹏城 - 百度 · 文心的训练算力则来自两个部分:初始化基于百度的百舸集群;训练基于鹏城实验室联合国内优势科研力量研发的鹏城云脑 Ⅱ。后者是我国首个国产自主 E 级 AI 算力平台,先后在 IO 500 总榜和 10 节点榜、MLPerf training V1.0、AIPerf 500 等国际国内多个权威竞赛榜单中斩获头名,为鹏城 - 百度 · 文心的强大技术能力奠定了基础。
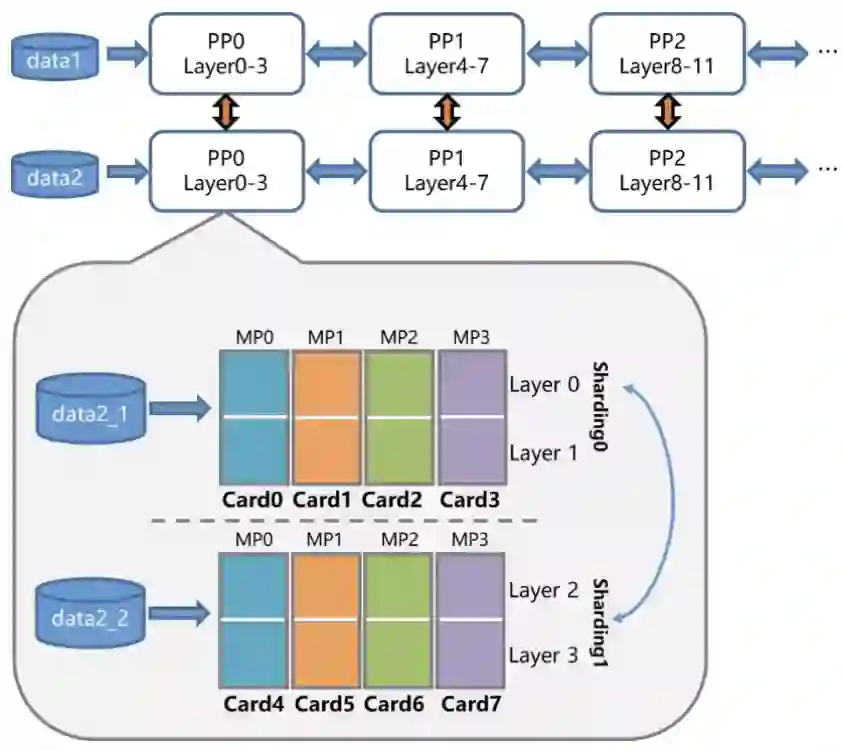
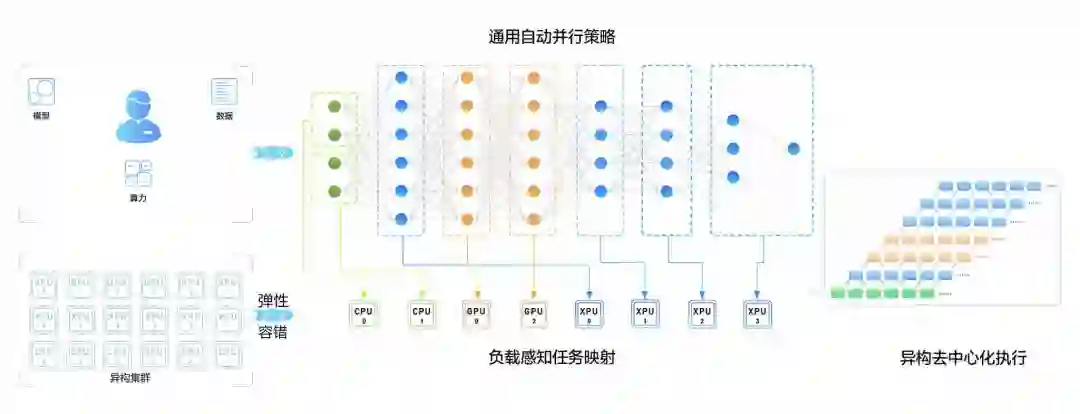
大模型的训练需要大算力,但并不是简单地堆砌算力。相反,这是一个系统性的工作,需要解决模型参数量单机无法加载、多机通信负载重、并行效率低等难题。具体到鹏城 - 百度 · 文心,问题就更复杂了。一方面,鹏城 - 百度 · 文心的模型结构设计引入了诸多小形状的张量计算,导致层间计算量差异较大,流水线负载不均衡;另一方面,「鹏城云脑 II」的自有软件栈需要深度学习框架高效深度适配,才能充分发挥其集群的领先算力优势。
为了克服这些挑战,飞桨的准备工作很早就开始了。今年 4 月份,飞桨就提出了 4D 混合并行策略来支持千亿参数规模语言模型的高效分布式训练。
![]()
如今,为了适配鹏城云脑 II,飞桨又设计并研发了具备更强扩展能力的端到端自适应大规模分布式训练架构(论文链接:https://arxiv.org/abs/2112.02752)。该架构可以针对不同的模型和硬件,抽象成统一的分布式计算视图和资源视图,并通过硬件感知细粒度切分和映射功能,搜索出最优的模型切分和硬件组合策略,将模型参数、梯度、优化器状态按照最优策略分配到不同的计算卡上,达到节省存储、负载均衡、提升训练性能的目的。这一架构将鹏城 - 百度 · 文心的训练性能提升到了传统分布式训练方法的 2.1 倍,并行效率高达90%。
此外,为进一步提高模型训练的稳定性,飞桨还设计了容错功能,可以在不中断训练的情况下自动替换故障机器,加强模型训练的鲁棒性。
在推理方面,飞桨基于服务化部署框架 Paddle Serving,通过多机多卡的张量模型并行、流水线并行等一系列优化技术,获得最佳配比和最优吞吐。通过统一内存寻址(Unified Memory)、算子融合、模型 IO 优化、量化加速等方式,鹏城 - 百度 · 文心的推理速度得到进一步提升。
![]()
两年前,一个名为「狗屁不通文章生成器」的应用让语言生成类模型走入大众视野。它可以在几秒中之内生成上万字的文章,但很多句子明显违背常识,而且你无法控制他所生成的文章的体裁、主题、情感等信息。虽然这只是一个简单的模型,但反映出的却是很多生成模型的通病:可控性和可信性差。
![]()
人工智能领域知名学者 Gary Marcus 在阐述 GPT-3 局限性时举的一个例子。普通字体是人类给出的提示(prompt),加粗字体是 GPT-3 的续写内容。文段大意为:你是辩护律师,今天必须出庭。早上穿衣服时,你发现你的西装裤很脏。但是,你的泳衣很干净、很时髦。事实上,这是昂贵的法国时装,是伊莎贝尔送给你的生日礼物。所以你决定穿泳衣出庭。你到达法院,一名法警将你护送到法庭。
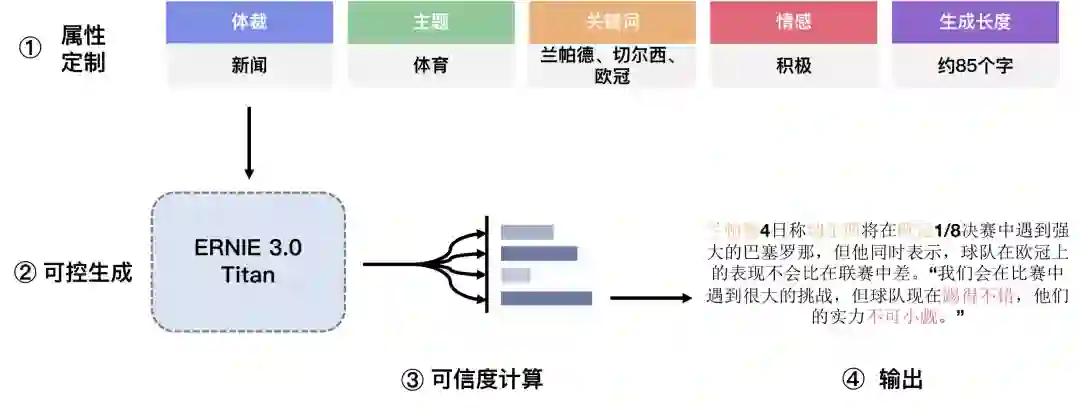
为了进一步提升模型的语言理解能力以及写小说、歌词、诗歌、对联等方面的文学创作能力,研究者提出了可控学习和可信学习算法。
在可控学习方面,他们将模型预测出的文本属性和原始文本进行拼接,构造从指定属性生成对应文本的预训练数据。然后,他们将这些数据喂给模型,实现不同类型的零样本生成能力。利用该模型,用户可以将指定的体裁、情感、长度、主题、关键词等属性自由组合,无需标注任何样本,便可生成不同类型的文本。
![]()
在可信学习方面,针对模型生成结果与真实世界的事实一致性问题,鹏城 - 百度 · 文心通过自监督的对抗训练,让模型学习区分数据是真实的还是模型伪造的,使得模型对生成结果真实性具备判断能力,从而让模型可以从多个候选中选择最可靠的生成结果,显著提升了生成结果的可信度。
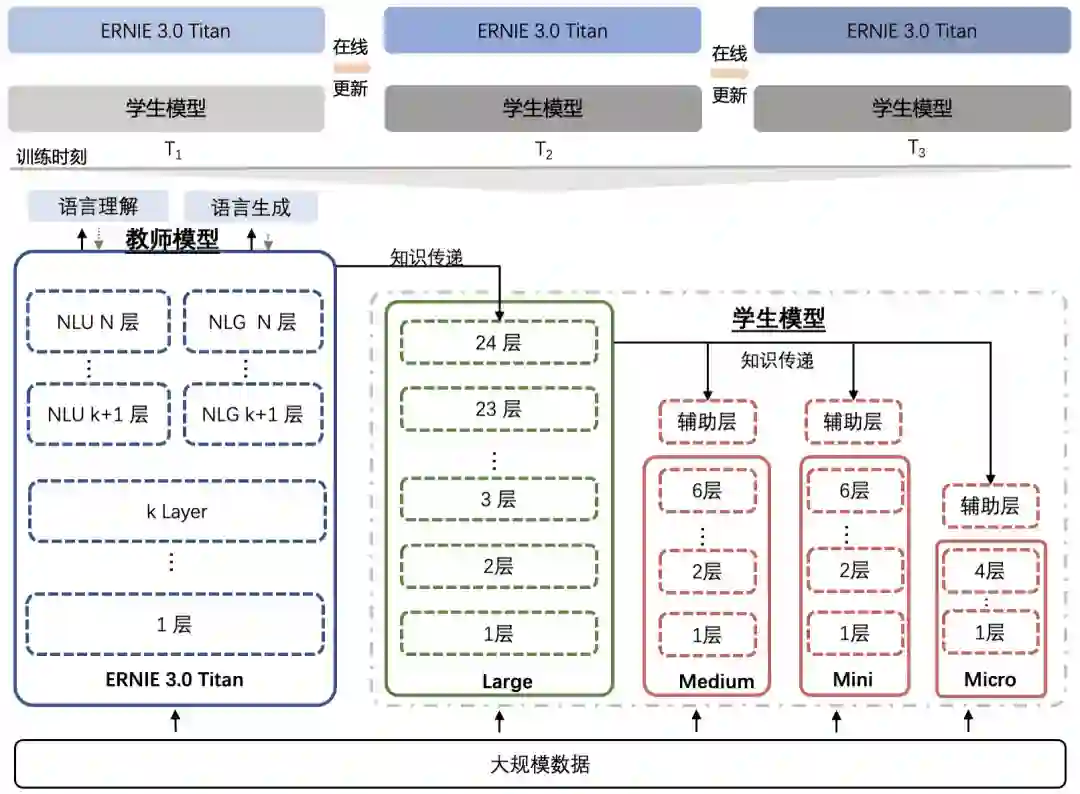
大模型不止训练昂贵,推理也很昂贵,而且碳排放问题突出。为了实现绿色落地,降低落地成本,研究团队提出了大模型在线蒸馏技术。它可以在鹏城 - 百度 · 文心学习的过程中周期性地将知识信号传递给若干个学生模型同时训练,达到蒸馏阶段一次性产出多种尺寸的学生模型的目的。与传统蒸馏技术相比,该技术极大地节省了因模型额外蒸馏计算以及多个学生的重复知识传递带来的算力消耗问题。
![]()
这种新颖的蒸馏方式利用了鹏城 - 百度 · 文心的规模优势,在蒸馏完成后保证了学生模型的效果和尺寸丰富性,方便不同性能需求的应用场景使用。
此外,研究团队还发现,鹏城 - 百度 · 文心与学生模型尺寸差距千倍以上,模型蒸馏难度极大甚至失效。为此,研究团队引入了助教模型进行蒸馏的技术,利用助教作为知识传递的桥梁以缩短学生模型和鹏城 - 百度 · 文心表达空间相距过大的问题,从而促进蒸馏效率的提升。
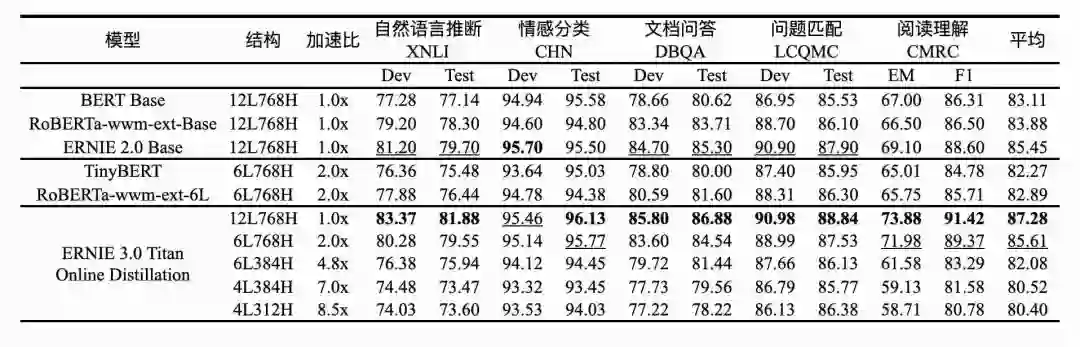
![]()
鹏城 - 百度 · 文心在线蒸馏方案的效果非常显著,压缩版模型仅保留 0.02% 参数规模就能与原有模型效果相当。相比直接训练参数规模是自身 2 倍的 BERT Base 模型,鹏城 - 百度 · 文心在 5 项任务准确率上绝对提升了 2.5%,而相对于同等规模的 RoBERTa Base,准确率则绝对提升了 3.4%,验证了鹏城 - 百度 · 文心在线蒸馏方案的有效性。
得益于这些技术方面的改进,百度的文心系列模型已经在金融、保险等多个行业得到应用。以某公司的保险合同解析场景为例,这项任务要求从一份合同中提取出近 40 个维度的信息,但百度文心大模型能把任务时间缩减至 1 分钟。从合作落地至今,目前这套保险合同条款智能解析模型已覆盖百余份合同模板,完成了上亿份合同条款的智能分类;且将近九成的合同在一天之内就能实现上线,完美实现了降本增效。
百度文心也正通过百度飞桨平台陆续对外开放。从 AI 核心技术到 AI 基础平台,从技术创新到实践落地再到开放生态,多年来,百度正不断降低 AI 技术开发和应用的门槛。王海峰表示,「我们希望这样一个知识增强大模型,能为产业发展注入新动能。」
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com