SIGIR2022 | UCCR: 以用户为中心的对话推荐系统
作者:李硕凯
单位:中科院计算所
研究方向:对话推荐
本文介绍被CCF A类会议SIGIR2022接收的以用户为中心的对话推荐系统的论文。该论文从推荐系统的角度重新审视了现有的对话推荐工作,发现现有方法关注于当前会话的自然语言理解,而忽略了推荐任务中最核心的目标:用户。现有方法本质上当前会话的建模,而忽略了用户建模。而本文发现用户历史会话和相似用户信息也可以很好地辅助用户兴趣建模,特别是在用户当前会话信息较少(冷启动)的场景下效果更佳。

论文的信息为:
题目:User-Centric Conversational Recommendation with Multi-Aspect User Modeling
作者:李硕凯*、谢若冰*、朱勇椿、敖翔、庄福振、何清
会议:ACM SIGIR 2022
预印版:https://arxiv.org/pdf/2204.09263
代码:https://github.com/lisk123/UCCR
1. 引言
对话推荐系统(Conversational Recommender System (CRS))旨在通过对话为用户提供高质量的商品推荐。生成式对话推荐一般包含两个模块:对话模块使用自然语言和用户交流,推荐模块基于对话内容学习用户兴趣偏好,提供高质量商品推荐。不同于传统推荐任务,对话推荐需要兼顾自然语言理解和用户兴趣建模。对话推荐在实际生活中也有着广泛应用,如语音助手(Siri、Cortana)、电商平台客服等。
目前已有一些生成式对话推荐相关的工作,而它们都侧重于更好地建模当前对话。这些工作可以分为如下几类:
-
引入额外知识图谱信息。如KBRD[1]引入实体知识图谱DBpedia,建模用户(当前对话)提到的实体中的结构化知识。KGSF[2]在实体知识图谱DBpedia基础上,引入了单词知识图谱ConceptNet,同时学习用户(当前对话)的结构化知识与语义知识。 -
控制对话策略。MGCG[3]将对话划分为多个阶段,设计策略引导对话走向与不同阶段之间的转移。TG-ReDial[4]利用不同话题(topic)引导对话走向。 -
引入用户评论信息。RevCore[5]引入用户对于电影的评论信息(review)建模用户兴趣。C2-CRS[6]利用用户评论信息设计coarse-to-fine的对比学习任务。 -
学习对话生成模板。NTRD[7]自动学习对话生成模板,生成更高质量的自然语言。
不难看出,以上方法均是利用自然语言理解技术,更好地建模当前对话信息。而作为推荐系统的一种,对话推荐的核心问题也应当是理解用户,建模用户行为。尽管当前对话信息在CRS中至关重要,我们发现用户的多方面(multi-aspect)信息,如用户历史对话、相似用户信息等,可以很好地辅助用户兴趣建模,更全面地理解用户。如下图所示,之前的CRS方法仅基于当前对话捕捉用户兴趣,只能捕捉到用户的基础兴趣偏好:奇幻电影,而无法建模用户隐式兴趣偏好:爱情电影。而这时历史对话信息、相似用户信息则提供了很好地补充。
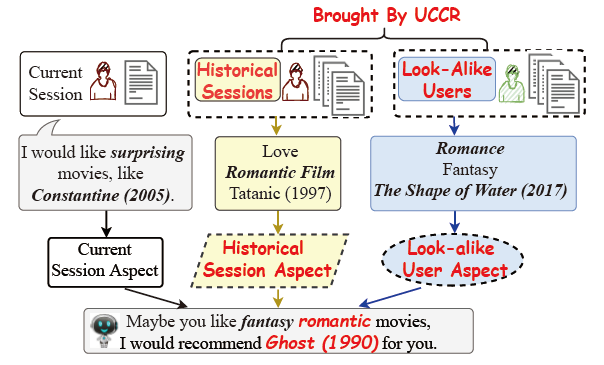
因此,我们从推荐系统的角度重新审视了对话推荐任务,提出了以用户为中心的对话推荐系统UCCR。具体地,UCCR包含以下几部分:
-
历史对话学习器:我们从历史对话中提取用户multi-view兴趣偏好,包含实体偏好(用户提到的实体)、语义偏好(用户提到的单词)、消费偏好(用户历史喜欢的商品)。这其中的关键问题是:如何提取适量的历史信息,使其不会破坏用户当前兴趣,而是更好地建模用户?因此,我们考虑历史信息与当前信息的相关性,只提取对当前兴趣建模有益的历史信息。 -
多视图兴趣偏好映射器:基于对比学习,学习不同view的兴趣偏好间的内在联系。其核心思想是:同一用户的不同view的兴趣偏好应当相关,而不同用户之间应当无关。 -
时序相似用户选择器:其核心思想是:历史兴趣相似的用户,其当前兴趣有更大概率会相似。由于CRS中用户兴趣不断变化(evolution),我们对每个用户学习多个动态变化的兴趣表示,而非固定的表示。 -
Multi-aspect multi-view用户兴趣偏好融合:在融合multi-aspect信息(即,历史对话信息、相似用户信息)时,需要考虑的核心问题也是平衡当前对话信息与multi-aspect信息之间的关系。
本文在中文、英文公开的对话推荐数据集上进行实验验证UCCR的有效性,实验表明UCCR在推荐和对话任务上相较于SOTA方法均有所提升。同时,UCCR可以很好地应对冷启动场景(即用户当前会话信息缺失时),历史会话和相似用户信息成为了很好地补充。
2. 符号体系
在介绍UCCR之前,我们先介绍本文的符号体系:



-
当前会话。在当前会话session中,可以提取出用户提到的当前实体 和当前单词 。 之前的CRS方法只用了 和 建模用户兴趣 。 -
历史会话。对于用户历史的 篇对话,分别收集每篇对话中出现的所有单词、实体、商品,构成集合 、 、 。 -
相似用户。我们利用历史兴趣偏好来确定相似用户。
可以看出,不同于前人的CRS方法,我们考虑历史会话信息和相似用户信息,更系统、全面地理解CRS中的用户。
3.方法
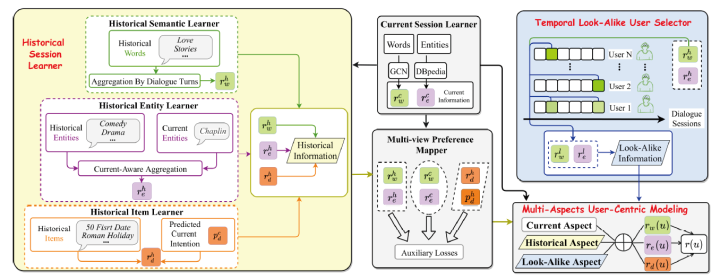
整体框架如上图所示。我们接下来详细介绍每个模块的设计思路与实现细节。
-
Current Session Learner:该模块将用户提到的current entities 和current words 进行编码,这部分完全follow前人工作[1, 2]。
-
Current Entity Learner:我们从DBpedia中学习结构化知识,帮助实体的表示学习。具体地,基于DBpedia,我们利用R-GCN得到每个实体的表示:
之后我们将所有实体的表示拼在一起,组成矩阵 ,再利用self-attention对这些实体进行加权平均,得到最终的当前实体表示 :
-
Current Word Learner:类似当前实体的编码,对于当前单词,我们利用ConceptNet作为额外语义知识,并用GCN对单词编码,最终得到当前单词表示: 。
-
Historical Sessions Learner:
-
Historical Entity Learner:对于用户历史提到的 篇对话中的所有实体 ,我们首先为每篇历史对话的所有实体学习一个embedding,再将这 个embedding加权聚合起来。
对于第 篇的历史对话出现的实体 ,我们利用R-GCN(具体细节同Current Session Learner部分)得到其表示 ,然后根据 与当前实体表示 的相似度进行加权平均:
其核心逻辑是:我们应更多地选择和当前实体偏好相似的历史实体,以防止不相关的信息干扰当前兴趣。
-
Historical Word Learner:与实体知识不同,语义知识是一种更为泛化的知识,我们强调对话推荐中的近因效应:越靠近当前对话的单词越重要。由于语义知识相比结构化的实体知识更加泛化,我们发现只需建模近因效应就能提取到适当的语义知识,在减少计算复杂度的同时保证了效果。
对于第 篇的历史对话出现的单词 ,我们利用每个单词出现的对话轮数对齐加权平均:
其中 是每个单词经过GCN得到的表示,
-
Historical Item Learner:用户历史喜欢的商品也可以辅助用户建模。对于历史商品,我们采用和历史实体一样的建模方式。但不同于历史实体,我们不知道当前商品的表示(事实上,当前商品正好是我们的预测目标)。因此我们利用当前实体表示和当前单词表示的组合来代替当前商品表示,最终得到历史商品表示 :
-
Multi-View Preference Mapper:由于前面得到的信息是multi-view的(如单词、实体就是两种不同view),这里我们基于对比学习,学习不同view的内在信息,进而得到更准确地表示。其核心思想是:同一个用户的不同view信息应当相关,而不同用户应当无关。其目标函数如下:
其中 和 有三种选择,组成了三个不同的任务:(1). ; (2). ; (3). 。其中 计算方法同 。
-
Temporal Look-Alike User Selector:这部分的核心思想是:历史行为(即提到的单词、实体)相似的用户,其当前兴趣偏好有更大概率相似。因此我们可以用相似用户信息辅助target用户的兴趣建模。由于CRS中用户兴趣随着对话推进不断变化,我们将用户每一次交互历史都和target用户历史进行比较,学习其中最有用的信息。具体地,以用户历史单词为例,其相似用户信息表示为:
其中 为截断函数,避免引入多余噪声, 为 的所有历史交互记录, 为余弦相似度。
在实际训练中,对于每个epoch,我们会重新计算用户历史单词表示和实体表示,用以学习相似用户。同时为了避免训练负担,我们在 这里进行梯度截断。
-
Multi-Aspect User-Centric Modeling:最后,我们将multi-aspect user information融合到一起。最终用户表示为:
-
Entity-View:最终的用户实体实体表示为用户当前实体表示、历史实体表示、相似用户实体表示的融合:
其中 控制了引入历史信息的量,其由当前实体和历史实体共同决定:
而 直接设为1。
-
Word-View:类似地,最终的用户单词表示为:
-
Item-View:由于用户消费偏好中,当前商品不可知,因此item表示中没有当前会话的item表示和相似用户的item表示,只有历史item表示:
-
Recommendation & Dialogue Generation:最终用户表示 用来帮助推荐任务与对话生成。
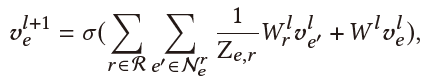
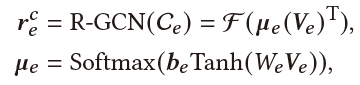
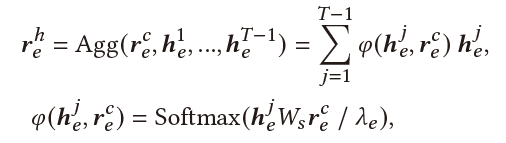
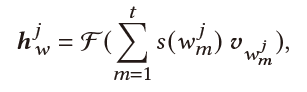
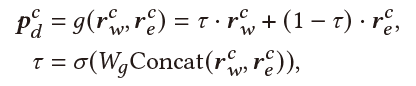
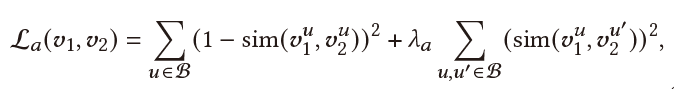
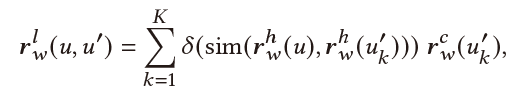
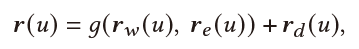
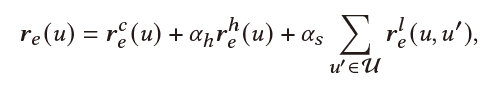
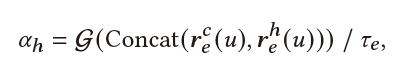
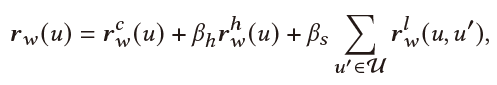
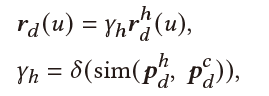
推荐:

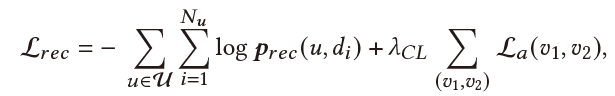
对话生成:

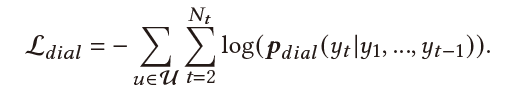
4.实验
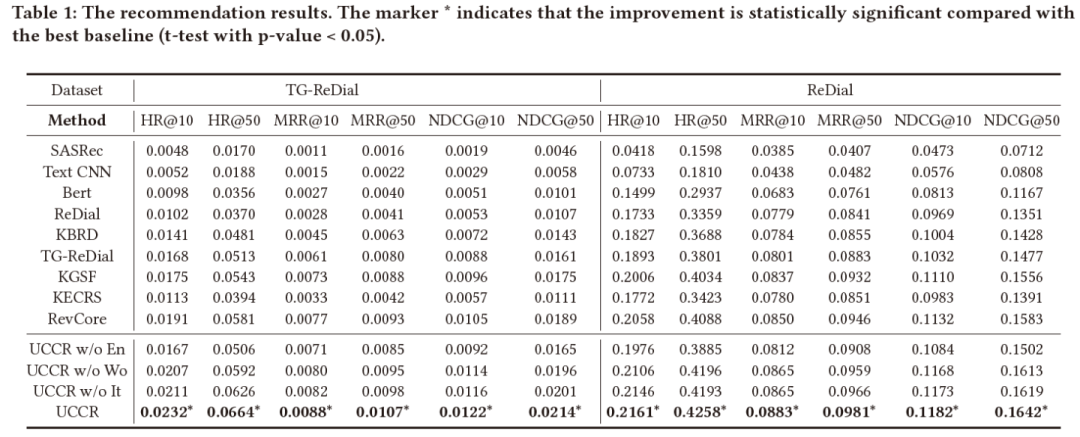
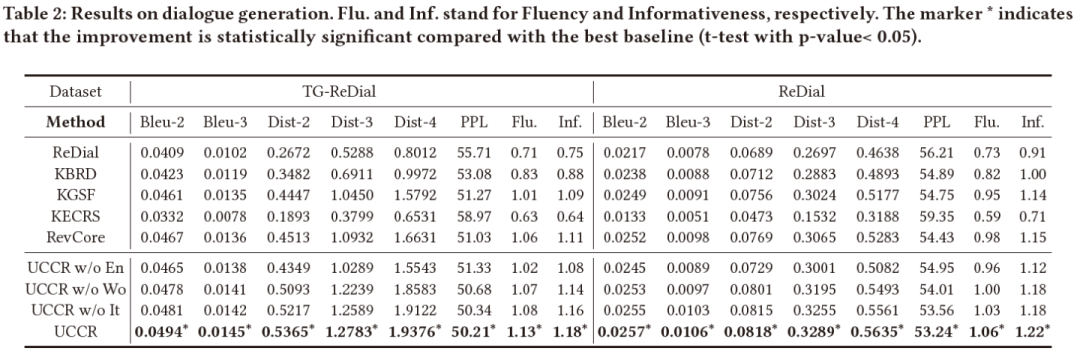
我们在两个公开对话推荐数据集上做了实验,其中ReDial是英文数据集,TG-ReDial是中文数据集。而为了用上历史对话信息,且避免数据穿越的问题,我们利用对话时间(chronological order)对于数据集进行重排,因此得到的效果与其他方法汇报的结果略有差异(之前的方法均是随机划分数据集,而我们为了避免数据穿越,要以对话的时间顺序对其进行划分)。其推荐和对话的实验效果如下,可以看到我们的方法在不同数据集上,多个评测指标上都取得了最优效果:
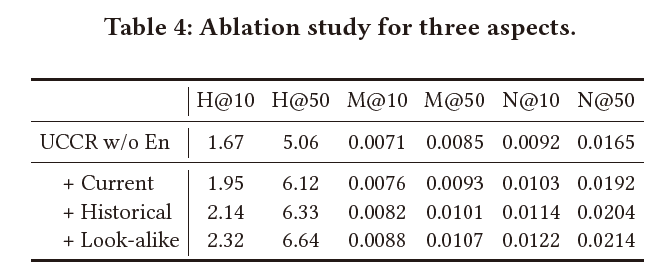
同时我们对于multi-aspect information进行了消融实验,证明每一部分的有效性:
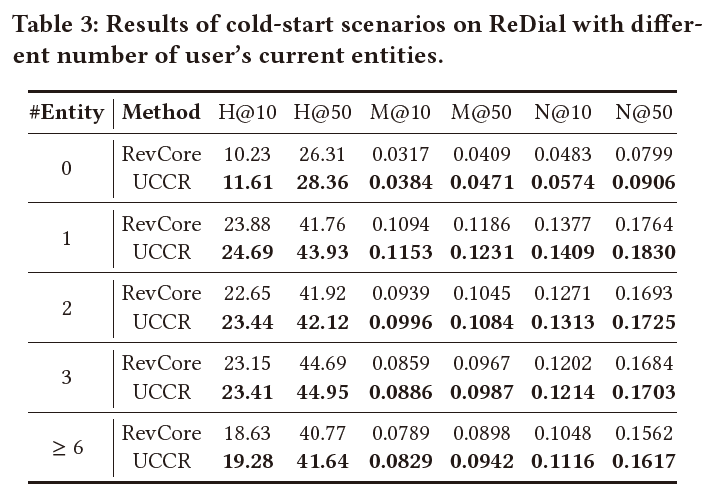
此外我们还测试了在两种冷启动场景下,我们模型的效果。
当用户当前信息较少时(用户当前实体数量小于等于3),我们方法效果如下图:
当用户历史信息较少时,我们的方法依然有效。具体地,我们将没有历史对话的用户称为new users,有历史对话的用户称为old users,其在ReDial数据集上表现如下图:
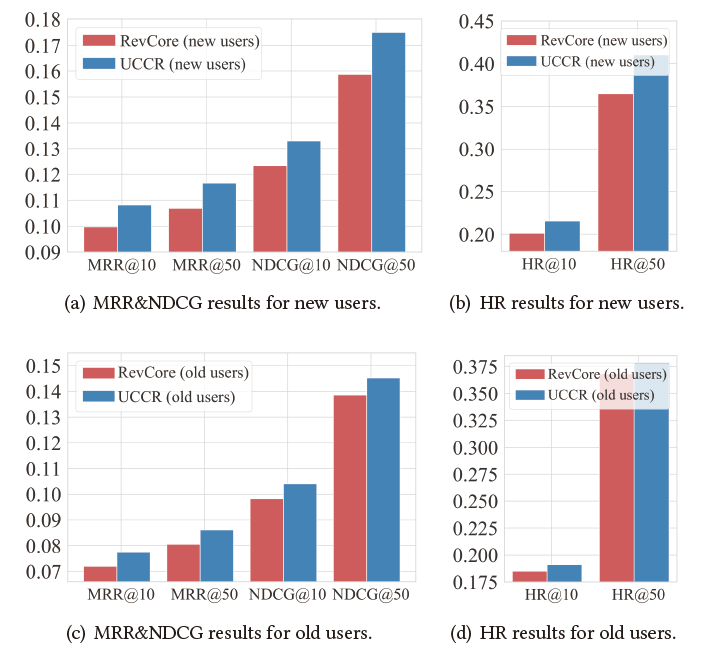
5.总结
本文从推荐系统的角度,重新审视了对话推荐任务。不同于前人的方法集中于自然语言理解,主要建模用户的当前对话,本文从多角度建模multi-aspect用户信息,更全面地理解用户。尽管在CRS中当前对话很重要,本文也发现用户历史对话信息、相似用户信息也可以提供很好地辅助作用。实验证明我们的模型在不同对话推荐数据集上均取得了最优效果。
References
[2]. Zhou K et al. Improving conversational recommender systems via knowledge graph based semantic fusion. SIGKDD. 2020.
[3]. Liu Z et al. Towards Conversational Recommendation over Multi-Type Dialogs. ACL. 2020.
[4]. Zhou K et al. Towards Topic-Guided Conversational Recommender System. COLING. 2020.
[5]. Lu Y et al. RevCore: Review-Augmented Conversational Recommendation. ACL Findings. 2021.
[6]. Zhou Y et al. C2-CRS: Coarse-to-Fine Contrastive Learning for Conversational Recommender System. arXiv preprint arXiv:2201.02732, 2022.
[7]. Liang Z et al. Learning Neural Templates for Recommender Dialogue System. EMNLP. 2021.
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
