SIGIR2022 | 基于Prompt的用户自选公平性推荐算法
作者:吴贻清
单位:中科院计算所
推荐系统的公平性在近些年来越来越受到人们的重视。在真实世界中,用户往往会有着一些属性信息(例如年龄,性别,职业等),这些属性是推荐算法理解用户偏好的重要信息源。但是,有时用户可能并不希望推荐系统的结果受到这些用户属性的影响,产生一些有偏见的推荐结果。然而,有时过度追求推荐结果的公平性,可能会有损推荐效率。我们认为推荐系统是否需要基于这些用户属性进行推荐,以及哪些用户属性信息需要被考虑,应当取决于用户自己的选择与需求。在这篇工作中,我们探索了推荐系统中一种可能的公平性产品形态——用户自选公平性(selective fairness)。
在我们的用户自选公平性推荐框架下,用户可以灵活地选择哪些用户属性应当被推荐系统所考虑,使得推荐结果在这些属性上保持公平。我们提出了一个参数有效的基于prompt的公平性推荐系统(PFRec)。PFRec基于pre-training&prompt-tuning的框架,使用个性化的用户属性组合特化的prompt和adapters(personalized attribute-specific prompts and adapters),能够针对不同公平性属性组合建立不同的参数有效的偏差消除器(bias eliminators),并通过对抗学习保证推荐结果在选择的用户属性上保持公平。实验表明了PFRec在选择性公平任务上的优势。

链接:https://arxiv.org/abs/2205.04682
代码:https://github.com/wyqing20/PFRec
背景介绍
随着互联网的发展,网络上的信息爆炸性地增长,推荐系统在人们信息检索和决策制定中的地位也越来越重要。数据驱动的个性化推荐算法能够给用户提供有吸引力的物品和信息,但是它们往往会带来一些不公平的现象。在近些年来,推荐系统的公平性也越来越受到人们的关注。推荐系统的公平性往往要从多方面考虑,例如推荐平台,被推荐用户,或者两者兼顾。一个通常的是让模型学习到的用户兴趣表示或者让模型的推荐结果关于目标属性无偏差(bias-free)。
建立一个公平的推荐系统往往需要在效率和公平中进行妥协,因为用户属性是用户行为之外的精准个性化推荐的重要特征来源。完全消除所有用户属性(这里用户属性不仅仅指用一个attributes,而是该属性所代表的信息,例如我们可能通过用户行为获取到用户的性别),可能会严重削弱推荐系统的准确性(特别在冷启动环境下)。此外,在复杂的真实世界中,用户往往有着许多的用户属性,但是什么时候以及哪些属性需要被推荐系统纳入公平性考量,这取决于每个人不同的需求。例如,在一个音乐推荐系统中,年龄可能是一个比较有效的特征——推荐系统可以根据年龄给用户推荐某个时代喜欢的音乐。然而,有时候某个年龄段的用户可能希望跳出自己年龄的信息茧房,去探索其它年代的音乐记忆。如果我们可以给用户提供一个包含用户多种属性的公平性选择开关,用户就可以自动勾选希望推荐系统考虑/不考虑的个人属性,这可以提高用户的使用体验和满意度。
在这篇论文中,我们致力于在序列推荐中实现用户自选的推荐系统公平性(selective fairness),使用户可以灵活选择不同组合的用户属性公平性需求。用户自选公平有着两项挑战 :(1)用户属性组合数n随着用户属性数m的增加呈指数型增加( )。然而已有的绝大多数公平性模型对于每一种用户属性组合需要训练一个单独的模型。训练和部署 个模型是非常低效甚至是不可能的。(2)数据稀疏性是推荐中一个普遍存在的基本问题,而用户在特定属性组合的公平性要求下行为更是稀疏。用户可选公平模型应充分利用未去偏的用户历史行为信息,在满足公平性时保证推荐准确性。
为了解决上述问题,我们提出了基于prompt的用户自选公平模型(PFRec)。PFRec引入了在NLP中被广泛验证的多种参数有效的微调技术。在NLP中,prompt通常是一段文本或者是一段向量。它们能够帮助模型通过很小的代价从预训练模型中提取有效的信息,并用于下游任务。在PFRec中,我们首先基于所有的用户历史数据训练一个序列化推荐模型作为预训练模型(如BERT4Rec, SASRec等),这个模型并没有任何公平性考量。然后,我们设计了一种个性化的用户属性组合特化的prompt和adapters(personalized attribute-specific prompts and adapters),针对每一种用户属性组合训练不同的基于prompt的偏差消除器(bias eliminators)(m种用户属性产生 种偏差消除器),从而实现用户可选的推荐公平。基于prompt的理念,在prompt-tuning阶段只有偏差消除器的参数被更新,而预训练模型则被固定。最后,我们通过一个对抗生成网络(GAN)来调节偏差消除器。在GAN中,判别器需要判别通过偏差消除器产出的用户表示是否在用户所选择的属性上存在偏差,从而实现特定属性上的公平性。
我们的PFRec有着两个优势:(1)参数有效的偏差消除器平衡了有效性和效率,这使得用户可选的推荐公平模型在实际推荐系统的部署中更加可行。(2)pre-training + prompt-tuning框架充分利用了pre-training模型从所有用户历史行为学习到的建模能力,在考虑可选公平性的同时保持了良好的推荐能力。我们在实验中进行了充分的实验,在单属性公平性和多属性公平性等任务上验证了PFRec的准确性和公平性性能。本文的贡献如下:
我们系统性总结了实现用户自选推荐公平性的挑战,并设计了一个全新的基于prompt的公平性推荐模型。PFRec是第一个使用prompt进行公平序列化建模的推荐模型。
我们提出一个个性化的用户属性组合特化的prompt和adapters,高效且灵活地适配推荐系统中不同属性组合的公平性需求。
我们在多个数据集上验证了PFRec的准确性和公平性性能。
模型方法
我们的整体框架如图1所示:
我们首先用所有的用户历史行为数据训练一个通用的序列推荐模型(这个模型并没有考虑公平性),并将这个模型作为我们的预训练模型。
接下来,我们针对选择属性的公平性来对预训练模型进行微调。这里我们使用对抗学习的框架来进行训练。
-
生成器(偏差消除器) :我们的生成器有两个目标:(1)根据用户的需求尽可能地生成公平的用户向量;(2)尽可能地让推荐的结果更加准确。这里我们的生成器有两部分:(1)personalized attribute-specific prompt:包括task-specific prompt和user-specific prompt,前者是根据用户的任务,即公平化需求生成的(不同用户可能有不同的需要公平化的属性组合),后者是通过用户的个性化属性生成的。(2)adapter:是另一个在NLP中被广泛验证的少参数微调经典方法。 -
判别器: 判别器的作用是用来判断经过偏差消除器产生的用户表示,是否在用户选择的属性组合上是公平的。通过minimax game,使得生成器能够产生特定属性公平的推荐结果。
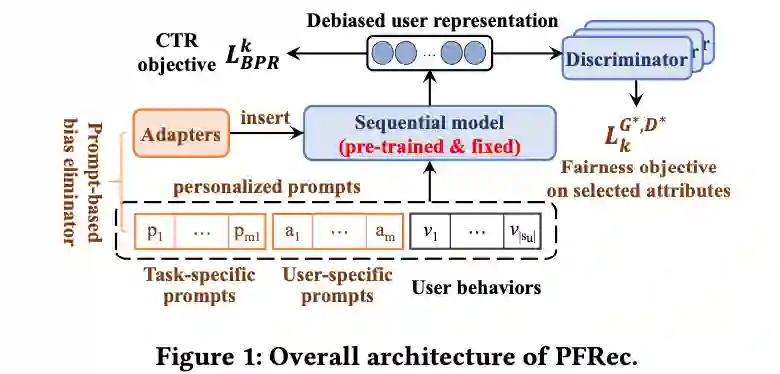
偏差消除器
本文中,我们使用SASRec作为序列模型。
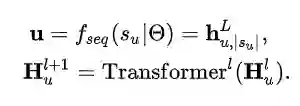
如上文中提到的,由于不同的用户对于公平性可能有着不同的需求,我们不可能为所有 种属性组合构建 个fine-tuning模型。于是,我们使用具有较少参数的prompt,构建 个prompt来提示模型当前需要进行哪种属性组合的公平性处理。我们的prompt分为两部分:(1)task-specific prompts:我们为用户的每种公平性需求都设置一个prompt,这个prompt由 个可训练的随机初始化的embedding构成。(2)user_specific prompt:为了更好地针对不同用户进行公平性推荐,我们构造了user-specific prompts。对于一个有着 个属性的用户,我们直接使用其所有属性向量拼接后的向量作为其user-specific prompt。我们将这两部分prompt拼在一起作为我们personalized prompt。最后,我们把此prompt拼接到用户历史行为序列前作为prefix prompt,来生成新的序列。
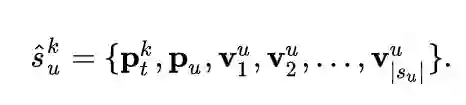
我们还一并使用了Adapters作为personalized attribute-specific prompt的辅助。最后,prompt-enhanced用户行为序列被送入到预训练模型中,输出在用户选择属性上保持公平的用户向量:
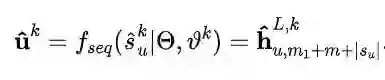
对抗学习
我们使用对抗学习训练偏差消除器,希望其能生成特定公平的推荐结果。我们认为如果一个偏差消除器生成的用户向量 无法被判别器准确猜测出用户向量对应的属性,则此用户向量被认为在这种用户属性上具有公平性。因此,生成器(偏差消除器)的目的是尽可能生成判别器无法准确判断用户属性的用户向量(即公平的向量),而判别器的目的则是尽可能地通过所生成的用户向量判断出其真实的用户属性。对抗学习可以表示如下:
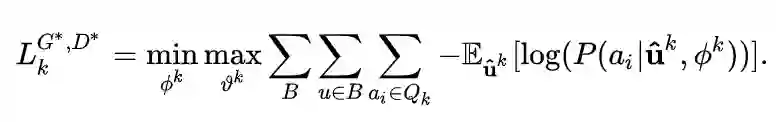
此外,我们的推荐算法的根本目的还是推荐合适的物品,因此推荐准确性也需要被考虑进来。综上,PFRec的最终loss为:
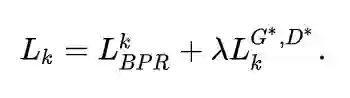
实验结果
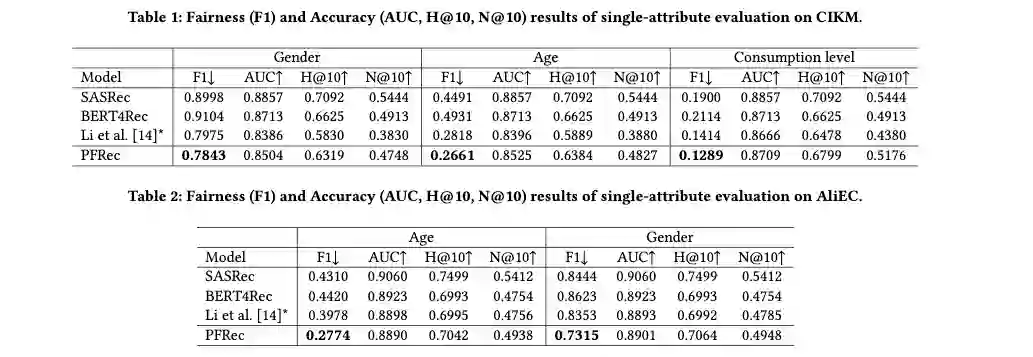
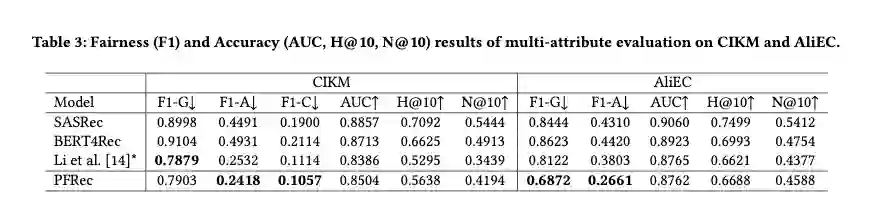
我们在两个公开数据集上做了实验,其中CIKM包含了性别、年龄、消费水平三个属性。AliEC包含了年龄和性别两个属性。我们在单属性公平性和多属性公平性等任务上验证了PFRec的准确性和公平性性能。
总结
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。


