视频 | AlphaGo Zero 五大亮点,全靠临场发挥也能赢

喜欢机器学习和人工智能,却发现埋头苦练枯燥乏味还杀时间?雷锋字幕组译制油管频道 Arxiv Insights 每周精选,从技术视角出发,带你轻松深度学习。
翻译 / 刘斌
校对 / 余杭
整理 / 张翼飞
AlphaGo和AlphaGo Zero傻傻分不清楚?今天视频带大家回顾AlphaGo Zero的五大亮点。
1.相比以前的阿法狗版本,AlphaGo Zero完全自主训练。这意味着不需要利用人类专业选手的下棋数据,它直接通过围棋对弈进行学习。
2.以前的方法选用了大量人工定义的围棋特征,新的方法没有选用这些特征,而是直接从棋盘状态中进行学习。
3.这篇论文从标准的卷集神经网络转向了残差网络,笔者认为是Resnet.网络。
4.这个网络从原有的两个不同的策略网络和评价网络改为组合成一个网络,这个网络实现了原有两个网络的功能。
5.新版本放弃了蒙特卡罗方法,改为采用简单的两阶段搜索方法,并将这种方法应用于这个网络上,进行局面预测和进行有效的下子。
不用围棋特征,直接在下棋中学习
首先,我们介绍一下围棋中的棋盘位置。棋盘由19*19的方格组成,这样就有19*19个位置,每个位置上可以放置白子,也可以放黑子,还可以什么都不放。DeepMind团队创建了一个单独的特征映射,这个映射对于黑子和白子都是单独创建的,这就意味着对于棋盘上所有的白子会得到19*19的二进制矩阵。
如果位置上有白子 矩阵对应的元素是1;如果棋盘位置上没有白子 对应矩阵元素就是0。黑子的映射矩阵,也是同样的结果。如果棋盘位置上有黑子,对应矩阵元素是1。如果没有黑子,对应矩阵元素是0。
这样这两个矩阵就表示了当前的棋盘位置,同样AlphaGo Zero这篇论文引入了其他特征面来表示,过去的7步的棋盘状态以便可以将棋盘的过去状态引入。

不再用标准卷积结构,采用残差网络
新版本的AlphaGo Zero放弃了标准卷积结构,转而采用残差网络。这样就意味着在每一层,有一条直达路径可以直接从输入到输出,中间没有经过卷积操作。这样做的主要原因是——残差连接工作效果允许梯度信号 ,实际上这种连接直接通过网络层。如果在早期网络训练过程中卷积网络很难进行有效的工作,这时候仍然进行有效的学习数据通过这些网络层,以便可以调节其他层。
因此,将棋盘表示作为输入,通过残差网络得到特征向量并从这些向量中需要得到两件事情: 第一件事是评价函数,评价函数很简单,是一个0和1之间的整数。这个数字表示当前局面赢的概率,这个网络的第二部分是策略向量,这个向量实际上是一个概率分布,这个分布给出所有可能下子行为的概率。在现有的局面下显然人们需要的是训练系统使得可以做出较好的下子行为,也就是整个棋盘表示需要选择更高概率去下出好棋,以及更低的概率下出坏棋。以上就是整个系统的训练过程。
放弃蒙特卡罗方法,转向简单的两阶段搜索方法
训练分为两阶段进行:第一阶段利用职业选手的数据集进行监督学习,第二阶段训练好的网络开始进行自我学习。而新版本的AlphaGo Zero系统不用数据集不利用任何职业选手的棋谱,完全通过自我对弈。
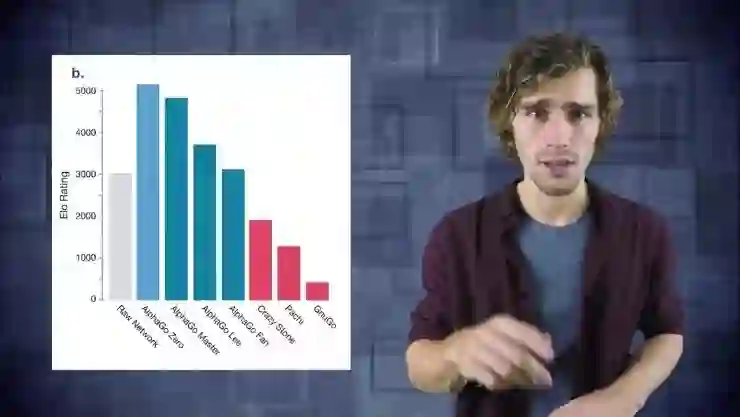
论文中给出了非常有趣的图,这个图展示了不同版本AlphaGo的性能。我们可以看到,亮蓝色是赢得李世石的版本。最左边的柱状图最低,因为这张图表示了没有采用蒙特卡洛方法可以取得差的结果。
如果采用这个训练好的网络,如果只采用这个网络一次,将棋盘状态输入网络,从对策向量中,你得到最好的下子方案,而不用做其他的事情。
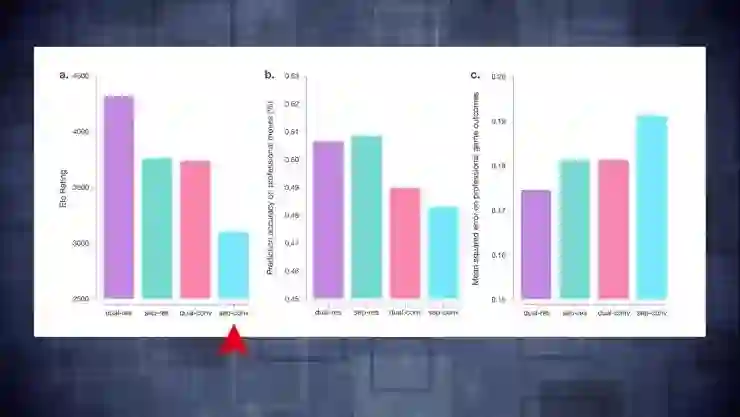
从卷积网络切换到残差网络后,我们可以看到,左图柱状体是残差网络,右边是原始的网络,红色柱体是利用卷积神经网络组合评价函数和策略向量的结果。切换成残差网络后得到了很大提升,把原始论文中的卷积神经网络切换成残差网络之后也会得到同样的提升。同时组合评价函数和对策向量,我们可以看到紫色的柱状体,这也是最终系统的性能结果。


————— 新人福利 —————
关注AI 科技评论,回复 1 获取
【数百 G 神经网络 / AI / 大数据资源,教程,论文】
————— AI 科技评论招人了 —————
AI 科技评论期待你的加入,和我们一起见证未来!
现诚招学术编辑、学术兼职、学术外翻
详情请点击招聘启事
————— 给爱学习的你的福利 —————
CCF ADL 系列又一诚意课程
两位全球计算机领域Top 10大神加盟
——韩家炜 & Philip S Yu
共13位专家,覆盖计算机学科研究热点
点击阅读原文马上听课
▼▼▼

————————————————————




