【AlphaGo Zero 核心技术-深度强化学习教程代码实战03】编写通用的格子世界环境类
点击上方“专知”关注获取更多AI知识!
【导读】Google DeepMind在Nature上发表最新论文,介绍了迄今最强最新的版本AlphaGo Zero,不使用人类先验知识,使用纯强化学习,将价值网络和策略网络整合为一个架构,3天训练后就以100比0击败了上一版本的AlphaGo。Alpha Zero的背后核心技术是深度强化学习,为此,专知有幸邀请到叶强博士根据DeepMind AlphaGo的研究人员David Silver《深度强化学习》视频公开课进行创作的中文学习笔记,在专知发布推荐给大家!(关注专知公众号,获取强化学习pdf资料,详情文章末尾查看!)
叶博士创作的David Silver的《强化学习》学习笔记包括以下:
笔记序言:【教程】AlphaGo Zero 核心技术 - David Silver深度强化学习课程中文学习笔记
《强化学习》第五讲 不基于模型的控制
《强化学习》第六讲 价值函数的近似表示
《强化学习》第七讲 策略梯度
《强化学习》第八讲 整合学习与规划
《强化学习》第九讲 探索与利用
以及包括也叶博士独家创作的强化学习实践系列!
强化学习实践三 编写通用的格子世界环境类
强化学习实践四 Agent类和SARSA算法实现
强化学习实践五 SARSA(λ)算法实现
强化学习实践六 给Agent添加记忆功能
强化学习实践七 DQN的实现
今天实践三 编写通用的格子世界环境类。
gym里内置了许多好玩经典的环境用于训练一个更加智能的个体,不过这些环境类绝大多数不能用来实践前五讲的视频内容,主要是由于这些环境类的观测空间的某个维度是连续变量而不是离散变量,这是前五讲内容还未涉及到的知识。为了配合解释David Silver视频公开课提到的一些示例,我参考了gym的思想设计了一个通用的格子世界环境类,该环境类的观测空间是一维离散变量,可以很好地模拟其公开课中提到的:简单格子、有风格子、随机行走、悬崖行走、随机策略(骷髅和钱袋子)等问题。在此基础上理解、实践强化学习的基础算法就相对简单而且直观了。
先贴上格子世界环境类的源文件:gridworld.py,只把该文件下载到您自己的文件夹内,导入其中的类或方法就可以了。已经内置的一些环境类UI界面类似下面这些:
一些内置的格子世界环境
简单或有风10*7格子世界
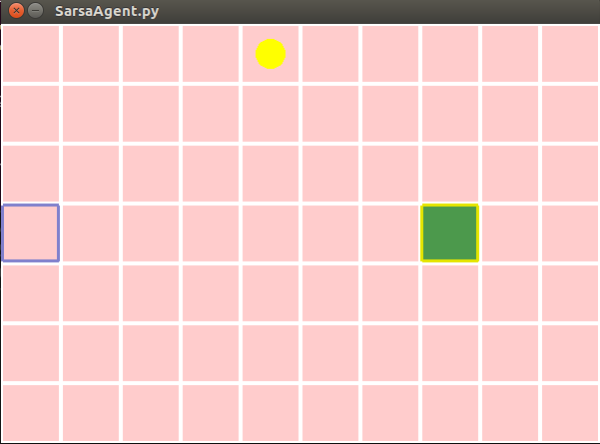
悬崖行走示例
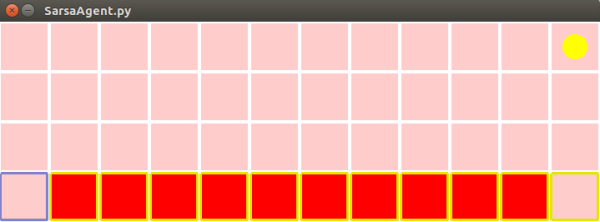
随机行走示例

模仿Gridworld with Dynamic Programming 的一个格子世界

用户可以自定义格子的大小、水平和垂直格子数目、内部障碍分布、以及每一个格子的即时奖励值。在通用的格子世界环境类的UI界面中,我使用不同的颜色设置表示不同的意义,其中:
带有蓝色边框的格子 表示起始状态;
带有金黄色边框的格子 表示终止状态,终止状态可以不止一个;
黑色的格子表示障碍格子,个体一般不能进入;
其他不同颜色的格子表示格子的即时奖励值不同,奖励值为0的格子颜色为灰色,奖励值为负值颜色显示偏向与红色,值越小,红色越深;奖励值大于0的格子偏向于显示绿色,值越大,绿色越饱满;
个体使用黄色圆形来表示。
如何使用通用的格子世界类来定制自己想要的格子环境:
通用的格子世界环境类接受如下参数:
def __init__(self, n_width:int=10,
n_height:int = 7,
u_size = 40,
default_reward:float = 0,
default_type = 0)分别是水平方向上格子数量,竖直方向上格子数量,每一个单位格子的绘制边长(单位为像素值),默认每一个格子的即时奖励值以及默认格子的类型。定义格子类型值为0时为个体可进入格子,类型为1表示为障碍,个体不能进入。有兴趣您可以修改代码支持更多的类型。
下面以一个悬崖行走格子世界环境为例,讲解如何使用通用的格子世界环境类来得到自己想要的格子世界环境对象。悬崖行走的例子出现在David Silver强化学习公开课的 第五讲 ,环境如下:
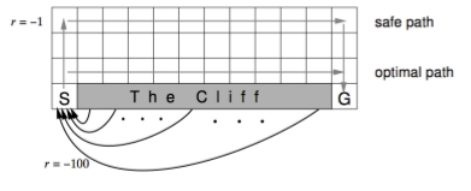
首先,明确格子世界环境的布局:长宽格子数、内部的障碍、即时奖励、起始状态、终止状态等信息。对于悬崖行走示例来说,世界长12,宽4,起始位置在左下角,坐标为 (0,0),终止状态在右下角,坐标为 (11,0)。
使用对应的参数建立一个格子世界环境类对象:
# 导入GridWorldEnv前确保当前代码文件与gridworld.py文件同在一个包内from gridworld import GridWorldEnvenv = GridWorldEnv(n_width=12, # 水平方向格子数量
n_height = 4, # 垂直方向格子数量
u_size = 60, # 可以根据喜好调整大小
default_reward = -1, # 默认格子的即时奖励值
default_type = 0) # 默认的格子都是可以进入的from gym import spaces # 导入spacesenv.action_space = spaces.Discrete(4) # 设置行为空间支持的行为数量# 格子世界环境类默认使用0表示左,1:右,2:上,3:下,4,5,6,7为斜向行走# 具体可参考_step内的定义# 格子世界的观测空间不需要额外设置,会自动根据传入的格子数量计算得到设置起始和终止状态,起始状态用元组描述,终止状态用列表描述:
env.start = (0,0)env.ends = [(11,0)]对一些特殊格子的类型和即时奖励值进行修改,这里要把组成悬崖的格子的即时奖励设为-100,这个例子中没有不可进入的格子,所以不需要对格子类型进行修改。示例中悬崖格子是终止状态,因此有:
for i in range(10):
env.rewards.append((i+1,0,-100))
env.ends.append((i+1,0))特殊类型的格子设置类似于即时奖励设置,比如我们将坐标为(5,1)和(5,2)的两个格子设为不可进入,可以添加如下代码:
env.types = [(5,1,1),(5,2,1)]最后为了使这些设置在实际生效,调用刷新设置方法:
env.refresh_setting()至此,我们自定义的格子世界环境就设置好了,调用其render()方法查看一下吧:
env.render()input("press any key to continue...")效果如下:

两块障碍已经顺利生成了,可是发现个体的位置不在起始位置,为此我们需要重置下个体的位置,只需要调用env的reset()方法就可以了:
env.reset()再看效果符合预期:

生成这个环境完整的代码如下,您也可以通过点击 这里 下载它。
from gridworld import GridWorldEnvfrom gym import spacesenv = GridWorldEnv(n_width=12, # 水平方向格子数量
n_height = 4, # 垂直方向格子数量
u_size = 60, # 可以根据喜好调整大小
default_reward = -1, # 默认格子的即时奖励值
default_type = 0) # 默认的格子都是可以进入的env.action_space = spaces.Discrete(4) # 设置行为空间数量# 格子世界环境类默认使用0表示左,1:右,2:上,3:下,4,5,6,7为斜向行走# 具体可参考_step内的定义# 格子世界的观测空间不需要额外设置,会自动根据传输的格子数量计算得到env.start = (0,0)env.ends = [(11,0)]for i in range(10):
env.rewards.append((i+1,0,-100))
env.ends.append((i+1,0))env.types = [(5,1,1),(5,2,1)]env.refresh_setting()env.reset()env.render()input("press any key to continue...")有了格子世界通用环境类,我们就可以比较方便定制自己的格子世界环境。为了方便使用,我也写好了几个内置的格子世界环境,大家只要调用相应的方法就可以得到它:
env = LargeGridWorld() # 10*10的大格子env = SimpleGridWorld() # 10*7简单无风格子env = WindyGridWorld() # 10*7有风格子env = RandomWalk() # 随机行走env = CliffWalk() # 悬崖行走env = SkullAndTreasure() # 骷髅和钱袋子示例如果您希望让您的个体支持斜向行走,请将相应的行为空间参数设为8,同时请留意环境类的_step方法关于斜向行走状态的改变是否如您所愿的那样设置,您可以在此基础上定制自己的行为规则。
要使用格子世界环境类提供的功能,您必须已经实现安装了gym库以及其依赖库。关于如何安装gym库、如何向gym注册自定义的环境类可以参考相关教程。通过gym库提供的相关功能,你还可以把个体经历Episode的过程录制成视频。
下次实践编写与个体相关的代码来巩固我们对强化学习相关基础算法的理解。敬请期待。
敬请关注专知公众号(扫一扫最下方二维码或者最上方专知蓝字关注),以及专知网站www.zhuanzhi.ai, 第一时间得到强化学习实践三 编写通用的格子世界环境类!
作者简介:
叶强,眼科专家,上海交通大学医学博士, 工学学士,现从事医学+AI相关的研究工作。
特注:
请登录www.zhuanzhi.ai或者点击阅读原文,
顶端搜索“强化学习” 主题,直接获取查看获得全网收录资源进行查看, 涵盖论文等资源下载链接,并获取更多与强化学习的知识资料!如下图所示。
此外,请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),后台回复“强化学习” 就可以获取深度强化学习知识资料全集(论文/代码/教程/视频/文章等)的pdf文档!
欢迎转发到你的微信群和朋友圈,分享专业AI知识!
请感兴趣的同学,扫一扫下面群二维码,加入到专知-深度强化学习交流群!

请扫描小助手,加入专知人工智能群,交流分享~

获取更多关于机器学习以及人工智能知识资料,请访问www.zhuanzhi.ai, 或者点击阅读原文,即可得到!
-END-
欢迎使用专知
专知,一个新的认知方式!目前聚焦在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“阅读原文”,使用专知!




