CNN对抗补丁之谜

更多干货内容请关注微信公众号“AI 前线”,(ID:ai-front)
首先说一下基本概念。
对抗攻击基本上指提供一个欺骗性的输入给 ML 模型,误导它产生错误的结果。这个结果可能是不正确的,或者是攻击者想要获得的某个目标分类。
这篇 Ycombinator 博文很好地解释了神经网路对抗攻击。文章太长,简单来说就是:
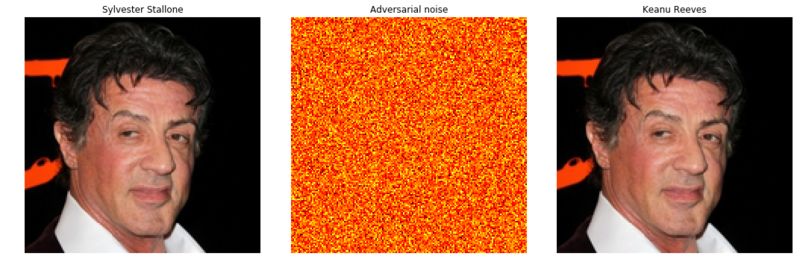
输入:图像 I、目标分类 C 和神经网络 N
输出:误导 N 预测 C 的修改后的图像 I'
过程:首先随机取一个噪声滤波器 X。结合 I 和 X,输入到 N。使用快速梯度逐步方法(梯度下降的一种形式)来修改 X,以达到两个目标:
对于 I+X,N 的预测结果为 C
X 尽可能小
这种简单方法的效果令人惊讶,而且噪声(X)可能很难检测到:
但是,这种方法要求为每张想要误导神经网络的图像执行渐变下降。从本质上说,你无法使用这种方法在运行过程中攻击模型。这就需要使用对抗补丁了。
输入:目标分类 C 和神经网络 N(注意,这里没有输入图像)
输出:补丁 P,将它以任何方式应用到任何图片,N 的预测都为 C
过程:
首先随机选取一个任意形状的补丁 P(作者使用了圆形的补丁)
定义一个应用补丁的算子,如下所示:
本质上讲,这个算子将补丁以指定的缩放比例和方向叠加到一个图像上指定的位置。
在训练过程中,随机取一张图像,在其上应用 P(每次使用不同的位置、方向和缩放比例),并反向传播相对于 C 的误差。这个过程重复很多次。
由于唯一可训练的方面是 P,并且每次将它与不同的图像(以不同的方式)结合在一起,所以学习算法要修改 P 以使 N 在各种情况下预测都为 C。

这个方法相当有效(请观看 https://youtu.be/i1sp4X57TL4)。
它为何与众不同呢?
它给对抗攻击一个全新的维度。例如,假设你要欺骗一个用来监控抢劫的人脸检测相机。你可以随身携带一个对抗补丁,从根本上让相机误以为看到一棵正在移动的树!
当然,要达到这个目的,你还需要访问预测神经网络。这篇论文决不是完全否定卷积神经网络对于图像分类系统的意义。但是,这项工作无疑是探索自动化系统的薄弱环节和安全隐患的正确方向。
查看英文原文:
https://codeburst.io/adversarial-patches-for-cnns-explained-d2838e58293



