【学界】带了个对抗图像块,YOLOv2竟然无法识别我是人……
来源:机器之心
对抗攻击是计算机视觉领域的一大研究热点,如何使模型对对抗攻击具备鲁棒性是很多学者的研究方向。但之前的研究主要主要涉及具备固定视觉图案的对象,如交通标志。交通标志的外观大致相同,而人的长相千差万别。来自比利时鲁汶大学的研究者针对人物识别检测器进行研究,他们创建了一个 40cm×40cm 的小型「对抗图像块」,它竟然使人在 YOLOv2 检测器下「隐身」。
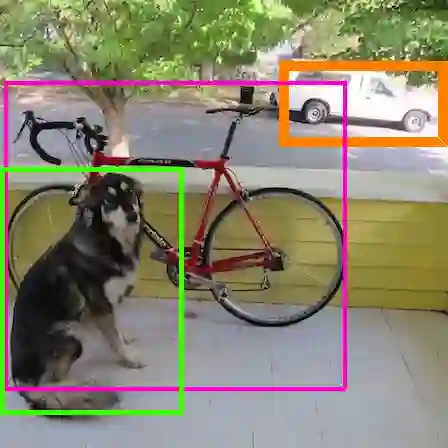
如下图所示,左侧没有携带对抗图像块的人可被准确识别出来,而右侧携带对抗图像块的人并未被检测出来。

研究者还发布了一个 demo 视频,展示了这个对抗图像块的「魔力」:
研究主题
卷积神经网络(CNN)的兴起使得计算机视觉领域取得巨大成功。CNN 在图像上学习时所用的数据驱动端到端流程在大量计算机视觉任务中取得了最优结果。由于这些架构的深度,神经网络能够学习网络底部的基础滤波器,也能学习网络顶层非常抽象的高级特征。
因此,典型 CNN 包含数百万参数。尽管这一方法能够生成非常准确的模型,但其可解释性大大下降。要想准确理解一个网络为何把人分类为人是非常困难的。网络通过观察其他人的大量照片,从而学习到人的长相应该是什么样子。模型评估过程中,我们可以对比输入图像和人物标注图像,从而判断模型在人物检测(person detection)任务上的性能。
但是,用这种方式评估模型只能使我们了解到模型在特定测试集上的性能,而该测试集通常不包含以错误方式控制模型的样本,也不包括用来欺骗模型的样本。这对于不太可能存在攻击的应用是合适的,比如老人跌倒检测,但对安防系统来说,这带来了现实问题。安防系统中人物检测模型如果比较脆弱,则可能会被用于躲避监控摄像头,破坏安保。
之前的目标检测器对抗攻击研究主要涉及具备固定视觉图案的对象,如交通标志(参见:学界 | 几张贴纸就让神经网络看不懂道路标志,伯克利为真实环境生成对抗样本;令人崩溃的自动驾驶:看完这个视频后,我不敢「开」特斯拉了),但缺乏针对类内变化对抗攻击的研究,如人物检测。
本文主要研究人物检测的对抗攻击,它针对常用的 YOLOv2 目标检测器。YOLOv2 是全卷积的模型,其输出网格的分辨率是原始输入分辨率的 1/32。输出网格中每个单元包含五个预测(即「锚点」),其边界框包含不同的宽高比。每个锚点包含向量
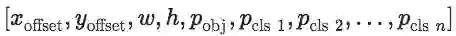
YOLOv2 模型架构如下图所示:
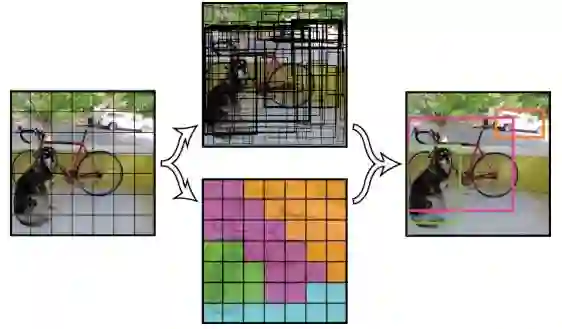
图 2:YOLOv2 架构。该检测器输出 objectness 分数(包含某个对象的概率,见图中上)和类别分数(哪些类在边界框中,见图中下)。图源:https://github.com/pjreddie/darknet/wiki/YOLO:-Real-Time-Object-Detection
一件躲避人物检测器的「隐身衣」
这篇论文介绍了对抗攻击给人物检测系统造成的风险。研究者创建了一个小型(40cm×40cm)「对抗图像块」(adverserial patch),它就像一件隐身衣,目标检测器无法检测出拿着它的人。
论文:Fooling automated surveillance cameras: adversarial patches to attack person detection

论文链接:https://arxiv.org/pdf/1904.08653.pdf
近几年来,人们对机器学习中的对抗攻击越来越感兴趣。通过对卷积神经网络的输入稍作修改,就能让网络的输出与原输出几乎背道而驰。最开始进行这种尝试的是图像分类领域,研究人员通过稍微改变输入图像的像素值来欺骗分类器,使其输出错误的类别。
此外,研究人员还尝试用「图像块」来实现这一目的。他们将「图像块」应用于目标,然后欺骗检测器和分类器。其中有些尝试被证明在现实世界是可行的。但是,所有这些方法针对的都是几乎不包含类内变化的类别(如停车牌)。目标的已知结构被用来生成对抗图像块。
这篇论文展示了一种针对大量类内变化(即人)生成对抗图像块的方法。该研究旨在生成能够使人不被人物检测器发现的对抗图像块。例如可被恶意使用来绕过监控系统的攻击,入侵者可以在身前放一块小纸板,然后偷偷摸摸地靠近而不被摄像头发现。
实验证明,该研究提出的系统能够大大降低人物检测器的准确率。该方法在现实场景中也起作用。据悉,该研究是首次尝试这种针对高级类内变化(如人)的工作。
生成针对人物检测器的对抗图像块
本文的目标是创建这样一个系统:它能够生成可用于欺骗人物检测器的可印刷对抗图像块。之前的一些研究主要针对的是停车牌,而本文针对的是人。与停车牌的统一外观不同,人的长相千差万别。研究者(在图像像素上)执行优化过程,尝试在大型数据集上寻找能够有效降低人物检测准确率的图像块。这部分将深入介绍生成对抗图像块的过程。
该研究的优化目标包括三部分:
L_nps:不可印刷性分数(non-printability score),这个因素代表图像块的颜色在普通打印机上的表现。公式如下:
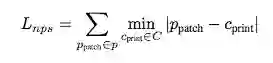
其中 p_patch 是图像块 P 中的像素,而 c_print 是一组可印刷颜色 C 中的一种颜色。该损失函数帮助图像块图像中的颜色与可印刷颜色中的颜色接近。
L_tv:[17] 中描述的图像总体变化。该损失确保优化器更喜欢色彩过渡平滑的图像并且防止噪声图像。我们可以根据图像块 P 计算 L_tv,如下所示:
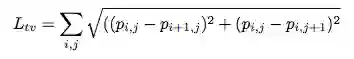
如果相邻像素比较相似,则分数较低;反之,则分数很高。
L_obj:图像中的最大 objectness 分数。对抗图像块的目标是隐藏图像中的人。为此,该研究的训练目标是最小化检测器输出的目标或类别分数。
总损失函数由这三个损失函数组成:
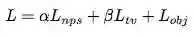
研究者将根据实验确定的因子 α 和 β 缩放的三个损失相加,然后利用 Adam 算法进行优化。
该优化器的目标是最小化总损失 L。在优化过程中,研究者冻结网络中的所有权重,只改变对抗图像块中的值。优化开始时,根据随机值初始化对抗图像块。
图 3 概述了目标损失的计算过程,类别概率也是根据相同的过程计算的。
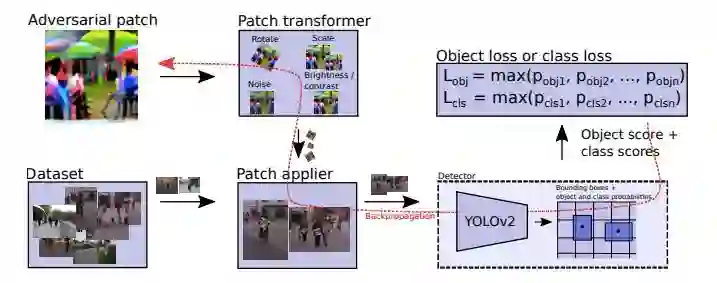
图 3:计算目标损失的过程。
实验
研究者使用和训练时相同的过程,将对抗图像块应用于 Inria 测试集以进行评估。在实验过程中,研究者最小化一些可能隐藏人的不同参数。作为对照,研究者还将其结果与包含随机噪声的图像块进行了比较,二者的评估方式完全一样。
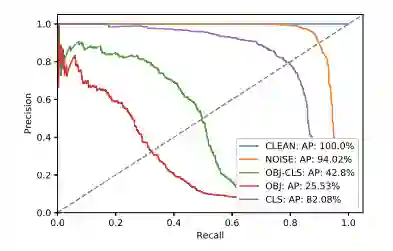
图 5:不同方法(OBJ-CLS、OBJ 和 CLS)与随机图像块(NOISE)和原始图像的 PR 曲线对比。
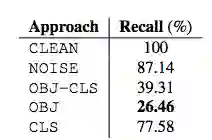
表 1:不同方法的 recall 对比。不同方法躲避警报的效果如何?
图 6 展示了将该研究创建的对抗图像块应用于 Inria 测试集的一些示例。

图 6:在 Inria 测试集上的输出示例。
在图 7 中,研究者测试了可印刷图像块在现实世界中的效果。

图 7:在现实世界中使用该可印刷图像块的情况。
该研究已公布源代码:https://gitlab.com/ EAVISE/adversarial-yolo,感兴趣的读者可以一探究竟。

☞ OpenPV平台发布在线的ParallelEye视觉任务挑战赛
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【学界】Ian Goodfellow等人提出对抗重编程,让神经网络执行其他任务
☞【学界】六种GAN评估指标的综合评估实验,迈向定量评估GAN的重要一步
☞【资源】T2T:利用StackGAN和ProGAN从文本生成人脸
☞【学界】 CVPR 2018最佳论文作者亲笔解读:研究视觉任务关联性的Taskonomy
☞【业界】英特尔OpenVINO™工具包为创新智能视觉提供更多可能
☞【学界】ECCV 2018: 对抗深度学习: 鱼 (模型准确性) 与熊掌 (模型鲁棒性) 能否兼得