DrMAD:深度神经网络中的超参数学习器
点击上方“深度学习大讲堂”可订阅哦!
深度学习大讲堂是由中科视拓运营的高质量原创内容平台,邀请学术界、工业界一线专家撰稿,致力于推送人工智能与深度学习最新技术、产品和活动信息!
摘要
深度神经网络的超参数对其在目标任务上的性能有着重要影响,而目前超参数往往只能人工基于经验来设置,以及采用暴力枚举的方式来尝试以寻求最优的超参数,这使得“调参”几乎成了一门玄学。超参数能否像网络的其它参数一样采用自动的方式来学习呢?对于这一问题,已经开始有一些工作在探索。本文将介绍一种基于梯度的超参数学习方法:DrMAD,其采用类似反向传播的方式来学习超参数,并通过构造“虫洞”突破了之前的方法在可调参数数量上的限制,具有更好的可扩展性,也使得优化过程更为高效。
Jie Fu, Hongyin Luo, Jiashi Feng, Kian Hsiang Low, and Tat-Seng Chua. DrMAD: Distilling Reverse-Mode Automatic Differentiation for optimizing hyperparameters of deep neural networks. IJCAI 2016.
http://www.ijcai.org/Proceedings/16/Papers/211.pdf
论文arXiv链接:https://arxiv.org/abs/1601.00917
源代码Github链接:https://github.com/bigaidream-projects/drmad
深度神经网络模型对应有两套参数,一类我们称之为基础参数(elementary parameter),如卷积层或全连接层的权重(weight)和偏置项(bias),另一类就是超参数(hyperparameter),如网络训练时的学习率,损失函数中L2正则化项的系数。在实际应用中,深度神经网络要取得好的性能,非常依赖于选择出一组好的超参数。然而,在训练深度神经网络的时候,自动学习的通常只是基础参数,超参数大都是人工根据经验设定或者通过网格搜索(grid search)的方式来尝试和选择,缺乏有效的自动学习方法。
最近几年有很多工作尝试自动学习深度神经网络中的超参数,其中比较流行的是基于高斯过程的贝叶斯优化(Bayesian optimization,BO)方法 [4],这类方法用高斯过程针对超参数和其对应的收敛之后的最终损失建立概率模型,并通过获取函数(acquisition function)来挑选下一次训练的最优超参数。BO方法通常只能用于超参数数量在20个以下的情况,虽然有时候很多超参数对模型的最终性能影响不大 [5],但是,举例来说,假设我们给网络每一层,甚至每一个神经元,设置单独的学习率,这很有可能比使用一个全局的学习率效果更好,而这时候如果面对一个深达上千层的ResNet,BO方法就无能为力。那么,在类似这样的情况下,该如何设计一个高效的算法来自动学习训练过程中所有用到的超参数,而不是采用鸵鸟策略呢?想到几乎所有深度神经网络中成万上亿的基础参数都是通过反向传播(back-propagation,BP)算法来学习的,那么我们能不能也用BP来学习超参数呢?
1. Reverse-Mode Automatic Differentiation
BP其实是Reverse-Mode Automatic Differentiation(RMAD)和梯度下降两者的结合,其中RMAD负责计算损失函数对于每一个基础参数的导数,然后根据这些导数来更新基础参数。
为了说明RMAD的过程,我们考虑一个简单的例子。假定我们的神经网络有2个要学习的基础参数x1和x2,网络的损失函数是f(x1, x2),其计算图(computational graph)如图1所示 [1](中间变量v1~v5可以对应于一个神经网络里的激活函数):
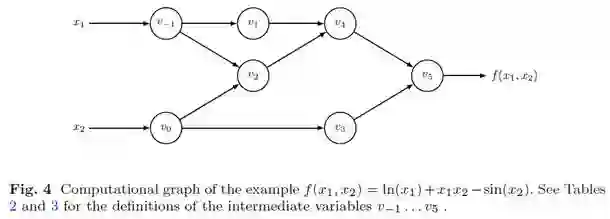
图 1
各个中间变量的具体定义,以及前向和反向计算过程如图2的表格所示 [1]:

图 2
可以看到,为了计算f(·)对x1和x2的导数,我们需要把中间变量v1~v5全部存储在内存里——包括变量之间的关系和中间计算结果,而RMAD则利用这些信息从后往前逐步求出f(·)对各个中间变量的导数,并最终求出对x1和x2的导数,即对我们真正关心的基础参数的导数。
2. 基于RMAD学习超参数
在深度神经网络通常的训练过程中,我们只考虑在一次迭代内形成的计算图,并以此来进行基础参数的更新。如果我们考虑网络训练的10000次迭代,那么这整个训练过程可以看成是一个规模非常大的计算图,而在其中的单次迭代过程中,超参数(如学习率)都会在这个计算图里跟其它的变量发生关系,并对最终10000次迭代之后的损失(loss)有影响。
下面说明基于RMAD来学习超参数的过程。我们考虑最简单的情况:整个网络只有x这一个基础参数需要学习。图3是全部T次迭代对应的计算图,其中input节点表示输入,dx节点表示对x的导数,μ节点表示超参数,Objective节点计算损失和导数,而Modifier节点使用超参数来改变模型的训练状态(例如,假定μ是学习率,那么Modifier节点的操作就是将学习率μ与导数dx相乘,然后更新基础参数x)。

图 3
在第一次迭代中,模型读取输入进行运算,并计算出对x的导数dxt1,超参数μ1参与到对基础参数x的更新过程中,将xt0更新为xt1,并留下computational footprint。第二次迭代,模型读取一个新的输入,并计算出新的导数dxt2,超参数μ2参与到更新xt1的过程中,并留下computational footprint。这个过程一直持续T次迭代——通常是直到神经网络收敛。这个时候我们拿模型在验证集上测试,得到验证集上的损失,之后开始进行反向过程(reverse pass),即计算验证集上的损失对于整个训练过程中所有参与运算的超参数μ的导数,以对其进行更新。反向过程如图4所示,其中红色的线表示导数的流动方向。

图 4
从上面可以看到,要更新超参数μ,类似于图2所给的例子,需要存储整个训练过程中所有的中间变量,然后才能通过RMAD逐步计算对各个超参数的导数。很显然,这种方式对内存有着巨大的需求。如果每一次迭代需要占用1GB的内存,那么10000次迭代就需要10TB以上的内存,所以直接使用RMAD来自动学习超参数在现实中几乎不具有可行性。
3. DrMAD:基于虫洞的RMAD
实际上,直接使用RMAD的问题,在于算法假定反向过程需要完全精确地沿着前向过程定义的方向逆向追溯回去,这也是需要保存前向过程中所有中间变量的原因。从另一个角度来看,由于用导数来学习长期的依赖关系本身就很困难 [6, 8],而在超参数优化的过程中,每一次计算hyper-gradient都需要计算成千上万次对基础参数的梯度,这使得我们面临的情形更加复杂,因此,如果采用从训练结束状态到初始状态的精确反向路径,hyper-gradient的回传和超参数的学习就会更加困难。
从生物实现的角度来看,这样的学习方式其实是很难实现的,因为这就好比是:在一个神经元跟另外一个远距离的神经元建立了正向传播的连接之后,要求被连接的那个神经元建立一条跟正向传播精确一致的反向连接 [2]。换言之,生物的神经网络不太可能使用这种“对称”BP。这样来看,我们是不是可以根据生物神经网络的特性,对现有的BP做一些修改呢?
于是,我们思考:有没有一种方法可以建立一条非对称的反向连接,让最终的损失可以往回传递到最初的状态(第1次迭代)——就好像建立一条从最终收敛状态(第10000 次迭代)到最初状态(第1次迭代)的虫洞?
在ICLR 2015的一篇文章中 [3],作者通过实验发现了一个有趣的现象。记网络的基础参数为θ ,其初始值为θ0,网络收敛之后其取值为θT,两者的线性组合γ = (1-α) θ0 + α θT。我们让α的值在一定范围内变化,得到不同的γ作为网络的参数,并分别计算网络在训练集和验证集上的损失,可以绘制出图5所示的损失曲线。
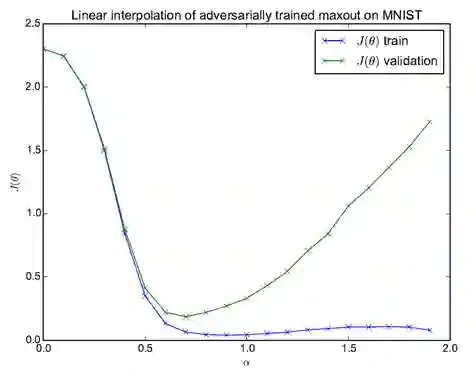
图 5
这里只考虑α从0变化到1的过程,我们可以把这个过程想象成是网络在回放一个“虚拟”的训练过程:从图上可以看到,训练集损失随着基础参数的变化在稳定下降,而且只有一个局部极小值。在这个回放过程中,不需要事先存储中间变量,而是用它们的近似值,这相当于把前向过程中的信息distilling到了反向过程中。受到这一现象的启发,我们设计了一个高效的基于RMAD的超参数学习方法:DrMAD,英文全称为Distilling Reverse-Mode Automatic Differentiation。
类似于上面所描述的现象,我们认为反向过程中每一次迭代对应的基础参数可以用其初始值和收敛之后的值来进行模拟,采用同样的线性模型,换用图4中的符号,则有:Xti ≈ (1-α)·Xt0 +α·XT。对应的过程如图6所示,其中红色的x节点表示模拟出的估计值。

图 6
图7以学习2个超参数的情况为例,给出了对DrMAD方法中前向和反向过程的一个直观描述。图上红色的线表示第1次meta-iteration,即固定两个超参数,网络第一次从初始状态开始训练直至收敛的过程(例如这可能包含2000次迭代),蓝色的线表示第2次meta-iteration。因为随机梯度下降的训练过程一般是比较曲折的,所以一次meta-iteration的前向过程用了一条曲线来表示。对于反向过程,常规的RMAD方法中,反向过程需要精确沿着前向过程的曲线反向回去计算超参数的导数,而在DrMAD方法中,反向过程则是采用了非常“凶残”的线性逼近方法,所以图上画的是一条直线。
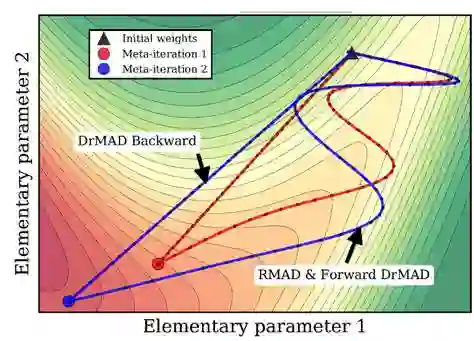
图 7
需要说明的是,虽然我们只能在2维空间通过这种可视化来理解,但在实验中,这种1维投影逼近的方式被证实在高维空间中是有效的。
4. 实验结果
我们采用3层的多层感知机在MNIST上进行实验,其中网络每一层节点数为50。我们给每一个节点设置一个独立的L2 正则化项系数,因此一共有934个超参数需要学习。实验中,我们将所有方法用的momentum均设置为0.1。另一方面,由于DrMAD的反向路径是通过近似得到的,根据基础参数的初始值和最终值模拟而来,因此反向过程的迭代次数并不需要和前向过程的迭代次数保持一致,从而可以通过更少的迭代次数进一步缩短反向路径,所以在MNIST实验中,我们将DrMAD一次meta-iteration中反向过程中的迭代次数设置为前向过程中的迭代次数的1/10:即如果前向过程中网络训练迭代了2000次,那么反向过程中的迭代次数则设为200次。图7展示了采用DrMAD学习超参数的过程,并和RMAD进行对比 [6](使用了压缩算法,前向和反向过程仍然保持对称)。
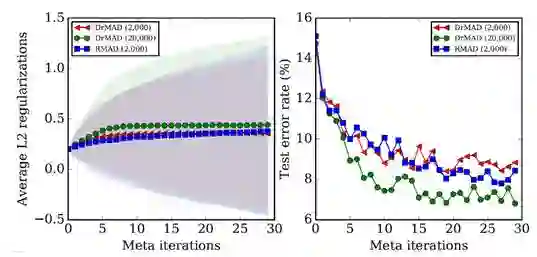
图 8
图8中的“DrMAD (2,000)”表示采用DrMAD学习超参数且一次meta-iteration的前向过程中网络训练运行了2000次迭代,其它类似。左图的曲线表示超参数的均值,不同颜色的阴影表示不同方法得到的超参数的方差。由于RMAD的速度过慢,图8中没有给出“RMAD (20,000)”的结果。
通过对比可以看到,DrMAD能够获得与RMAD非常接近的优化效果:蓝色曲线对应于[6]中使用的对称RMAD方法,而红色取线对应于DrMAD方法。我们也复现了[6]中在Omniglot数据集上做多任务训练的实验:DrMAD的测试损失值为1.13,RMAD的方法也为1.13。这证明了DrMAD在使用类似虫洞的非对称路径的情况下,依然可以驱动超参数的导数相对有效地在计算图上流动。
相比于RMAD [6], DrMAD在空间和时间复杂度上有着明显的优势。由于DrMAD不需要存储任何的中间结果,所以比RMAD节省至少100倍的内存,不仅如此,DrMAD对于内存的需求实际上是固定的,只需要存储基础参数的初始和最终取值。在速度上,由于DrMAD在反向过程中只需要较少的迭代次数,而且没有任何额外的压缩运算,因此远远快于RMAD。当momentum = 0.1时, RMAD需要频繁地进行压缩操作,DrMAD相比要快45倍。
目前的实验仅限于相对简单的模型和数据集,而且迭代次数相对较少的情况,目前还不清楚这种非对称的计算图模型是否可以用于更复杂的问题。另一方面,我们提出的线性逼近方法是最简单的一种,应该有更适合深度模型的非对称计算图近似算法。
5. 超参数的超参数
虽然DrMAD方法是为了更有效地优化超参数,但它本身还有自己的超参数:即超参数的导数对应的学习率,其它的超参数优化方法(如BO)也有相应的超参数需要人工设置,这类超参数的超参数也被称为“super-parameter”。整个神经网络的参数系统就好像一个金字塔:最下面的是基础参数,它们数量最多,这些基础参数被另外较少数量的超参数所控制,而在这些超参数之上,还有数量更加少的super-parameter。对super-parameter进行优化可以采用随机搜索的方法 [7],随机搜索法的效果几乎可以和BO媲美,但是它没有任何额外的超参数需要人工设置,而且非常容易并行化。
在实验中,由于meta-iteration的次数通常不多(一般小于20),因此,对于某个超参数对应的学习率,如果在一个meta-iteration之后,我们观察到其让整体的损失下降,就认为这个超参数的学习率已经足够好,不再继续搜索。
参考文献
[1]. Atilim Gunes Baydin, Barak A. Pearlmutter, Alexey Andreyevich Radul, and Jeffrey Mark Siskind. Automatic differentiation in machine learning: A survey. CoRR, abs/1502.05767, 2015.
[2]. Timothy P. Lillicrap, Daniel Cownden, Douglas B. Tweed, and Colin J. Akerman. Random feedback weights support learning in deep neural networks. Nature Communications, 2016.
[3]. Ian J. Goodfellow, Oriol Vinyals, and Andrew M. Saxe. Qualitatively characterizing neural network optimization problems. ICLR 2015.
[4]. Shahriari, Bobak, Kevin Swersky, Ziyu Wang, Ryan P. Adams, and Nando de Freitas. Taking the human out of the loop: A review of Bayesian optimization. Proceedings of the IEEE, 2016.
[5]. Wang, Ziyu, Frank Hutter, Masrour Zoghi, David Matheson, and Nando de Feitas. Bayesian optimization in a billion dimensions via random embeddings. Journal of Artificial Intelligence Research, 2016.
[6]. Maclaurin, Dougal, David K. Duvenaud, and Ryan P. Adams. Gradient-based hyperparameter optimization through reversible learning. ICML 2015.
[7]. Bergstra James and Yoshua Bengio. Random search for hyper-parameter optimization. Journal of Machine Learning Research (JMLR), 2012.
[8]. Yoshua Bengio, Patrice Simard, and Paolo Frasconi. Learning long-term dependencies with gradient descent is difficult. IEEE Transactions on Neural Networks (TNN), 1994.
[9]. Sutskever, Ilya, James Martens, George E. Dahl, and Geoffrey E. Hinton. On the importance of initialization and momentum in deep learning. ICML, 2013.

该文章属于“深度学习大讲堂”原创,如需要转载,请联系loveholicguoguo。


付杰,新加坡国立大学综合科学与工程研究生院在读博士生。博士第一年研究脑神经科学,后专注于深度网络的超参数学习,研究兴趣还包括强化学习、自然语言处理等。在AAAI和IJCAI上共发表两篇文章。个人主页:http://bigaidream.github.io/
罗鸿胤,麻省理工大学CSAIL课题组博士。本科毕业于清华大学,本科期间以第一作者身份发表论文于EMNLP,并曾赴新加坡国立大学做访问学生,在2013年参加百度机器学习竞赛获得第二名,CCF大数据竞赛获得三等奖(获奖队伍中最年轻的一组)。研究兴趣包括深度学习、自然语言处理、语音识别等。
注:作者介绍不分先后顺序。
往期精彩回顾



欢迎关注我们!
深度学习大讲堂是由中科视拓运营的高质量原创内容平台,邀请学术界、工业界一线专家撰稿,致力于推送人工智能与深度学习最新技术、产品和活动信息!
中科视拓(SeetaTech)将秉持“开源开放共发展”的合作思路,为企业客户提供人脸识别、计算机视觉与机器学习领域“企业研究院式”的技术、人才和知识服务,帮助企业在人工智能时代获得可自主迭代和自我学习的人工智能研发和创新能力。
中科视拓目前正在招聘: 人脸识别算法研究员,深度学习算法工程师,GPU研发工程师, C++研发工程师,Python研发工程师,嵌入式视觉研发工程师,PR经理,商务经理。(PS:深度学习算法工程师岗位、Python研发工程师岗位、嵌入式视觉开发工程师岗位和运营岗位同时接收实习生投递)有兴趣可以发邮件至:hr@seetatech.com,想了解更多可以访问,www.seetatech.com


中科视拓

深度学习大讲堂
点击阅读原文,查看中科视拓公司主页


