通过深度学习将 L1000 图谱转换为类似 RNA 的图谱
编辑 | 萝卜皮

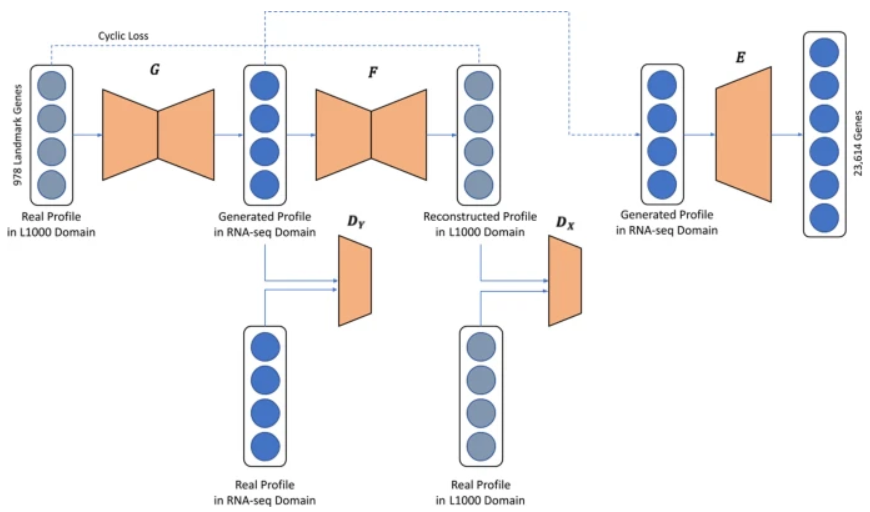
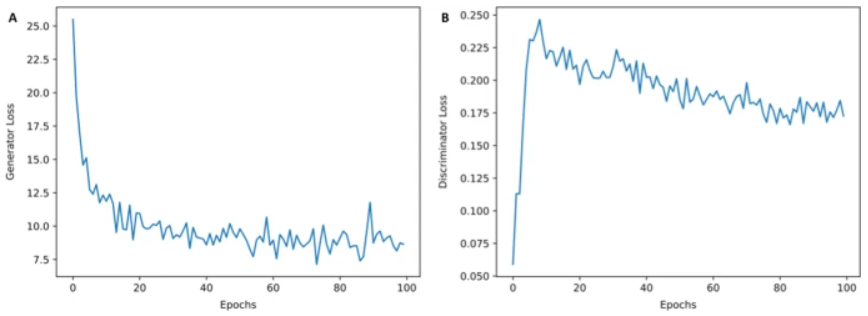
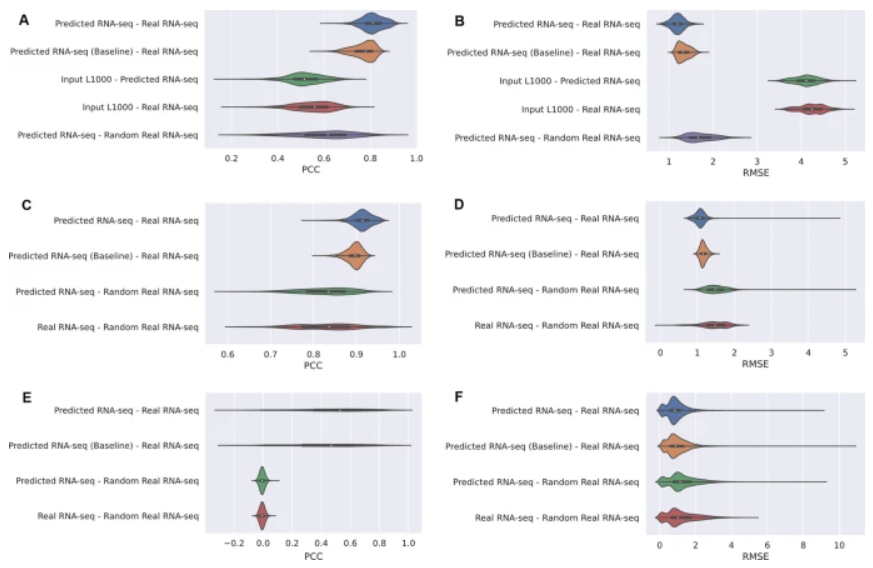
图示:模型架构。(来源:论文)
人工智能 × [ 生物 神经科学 数学 物理 材料 ]
「ScienceAI」关注人工智能与其他前沿技术及基础科学的交叉研究与融合发展。
欢迎关注标星,并点击右下角点赞和在看。
点击阅读原文,加入专业从业者社区,以获得更多交流合作机会及服务。
登录查看更多
相关内容
Arxiv
10+阅读 · 2020年3月31日
Arxiv
19+阅读 · 2019年11月20日

相关VIP内容
相关资讯
相关论文
Arxiv
10+阅读 · 2020年3月31日
Arxiv
19+阅读 · 2019年11月20日