最近3篇蛋白质及其组学知识图谱Nature子刊文章解决生物学核心问题
第一篇文章是2022年1月31日发表在Nature biote上的文章“A knowledge graph to interpret clinical proteomics data“,作者用蛋白质组学知识图谱,提供了从组学数据到辅助临床决策的可靠的、并经过验证的分析框架。作者开源了相关数据和代码,可以直接迁移到自己的项目中。

将精准医疗应用到临床决策过程中,取决于整合的多组学数据的情况。但是由于生物医学数据的质量与多样性,以及跨不同生物医学数据库和出版物中的扩展性,对数据集成提出了很高的要求。
作者构建了临床知识图谱(CKG),这个开源平台目前包含了2000万个节点和2.2亿个关系。
图算法提供了一个灵活的数据模型,当新的数据库可用时,该模型很容易扩展到新的节点和关系。CKG结合了统计和机器学习算法,可加速蛋白质组学工作流程的分析和解释。
通过一组proof-of-concept生物标志物研究,作者展示了CKG增强和丰富了蛋白质组学数据,并为临床决策提供了关键信息。
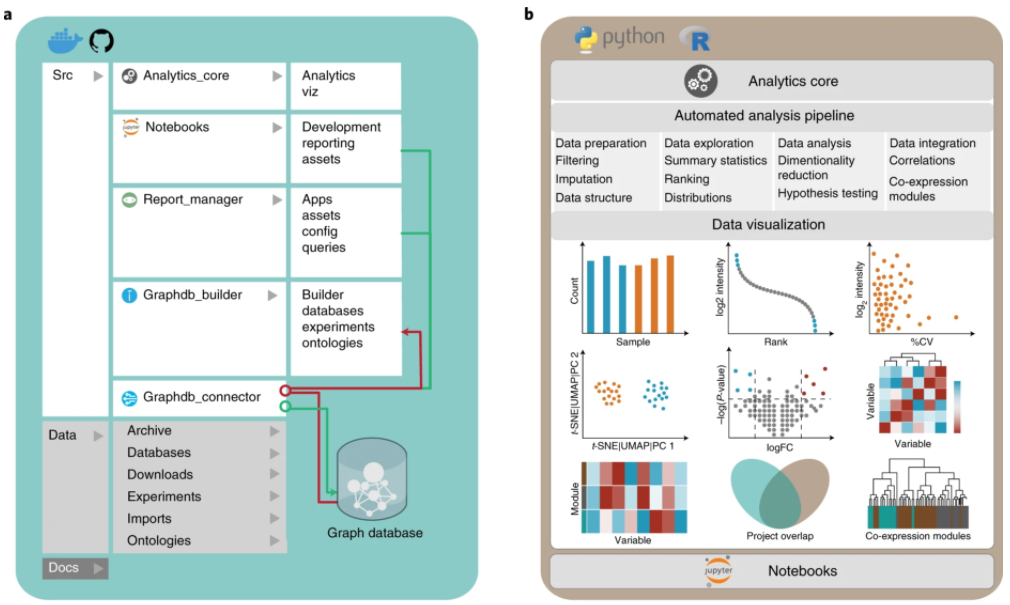
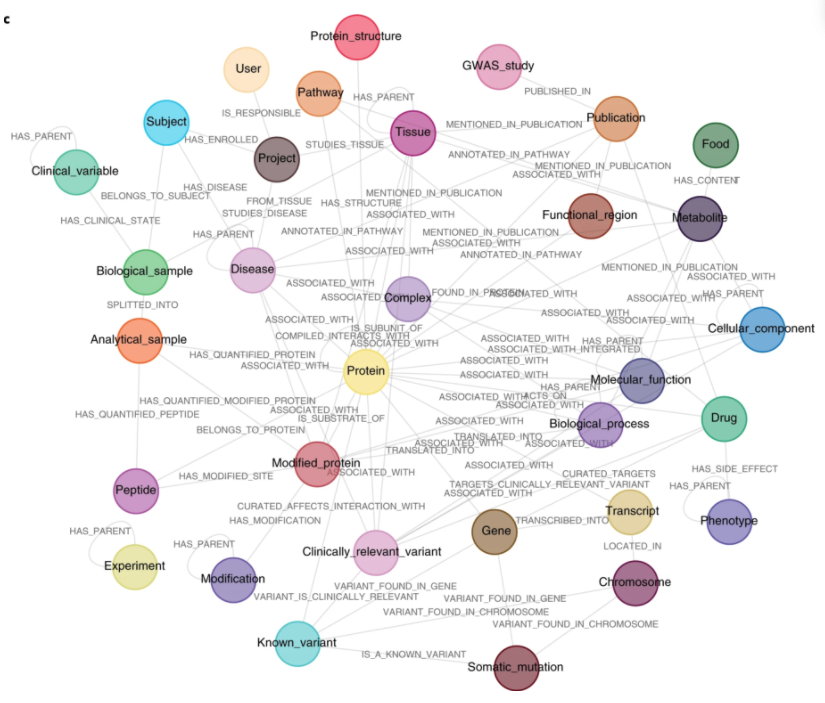
a、CKG架构用python实现,包含几个独立的模块:负责连接数据库(graphdb_builder)、构建图(graphdb_builder)、分析和可视化实验数据(analytic_core)、显示和启动多个应用程序(report manager);b、CKG分析核心实现了多种最新的数据科学算法,用于蛋白质组学的统计分析和可视化:数据准备、探索、分析和可视化。c、CKG图数据库数据模型旨在整合多层次的临床蛋白质组学实验,并用生物医学数据对其进行注释。它定义了不同节点(例如,蛋白质、代谢物和疾病)以及连接它们的关系类型(例如,HAS_PARENT和HAS_QUANTIFIED_PROTEIN).
自动CKG分析用于肝病生物标志物发现
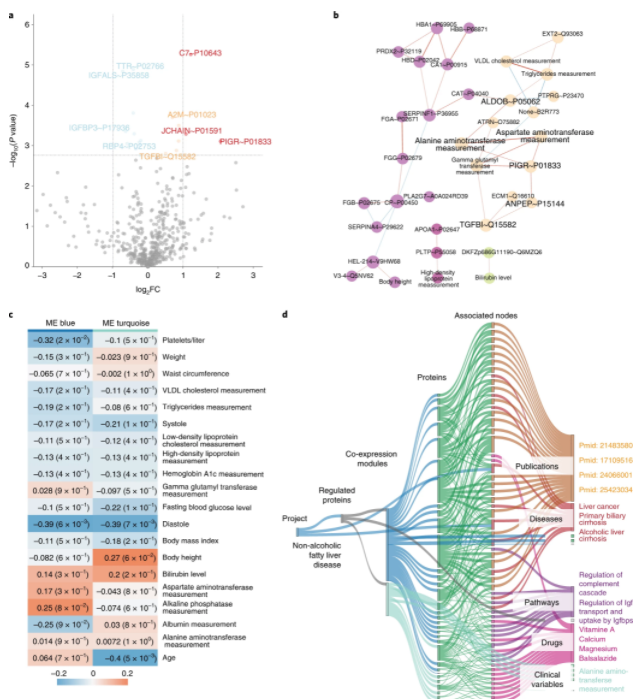
CKG的自动化分析流程复现了(Niu等人的结果[41])之前的结果。
CKG支持多蛋白质组学数据集成,用于癌症生物标志物的发现和验证
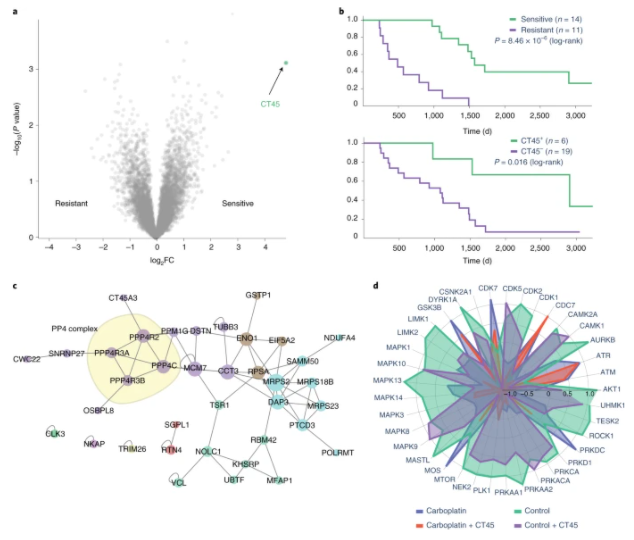
a , CKG 强调 CT45 是唯一在比较化疗耐药和化疗敏感患者的卵巢肿瘤组织时显著调节的蛋白质 ( n = 25; SAMR s0 = 2; BH FDR < 0.05) (数据来自 Coscia 等人3 ) . b,CKG 的分析管道估计了临床组敏感和耐药(双边对数秩检验)的生存函数,相应的高(前 25%)和低(剩余 75%)CT45 表达,并确认明显更长的疾病-高 CT45 表达组的自由生存。C, 相互作用蛋白质组学揭示了 PP4 磷酸酶复合物的亚基作为 CT45 的直接相互作用物,CKG 将其显示为 PPI 网络中的簇,确认已知的相互作用物并突出潜在的新相互作用物(由簇着色的节点)。d,CKG 中的磷酸蛋白质组学分析确定了显著调控的位点,并将它们与上游激酶调节剂联系起来。在这些激酶调节剂中,CDK7、CDC7、ATR 和 ATM 受卡铂作用的影响很大。FC,折叠变化。
代码:https://github.com/MannLabs/CKG
第二篇论文是2022年2月11日发表在Nautre comm上的文章“Machine learning prediction and tau-based screening identifies potential Alzheimer’s disease genes relevant to immunity”。

为基于元路径的机器学习开发了(ProteinGraphML)知识图谱。
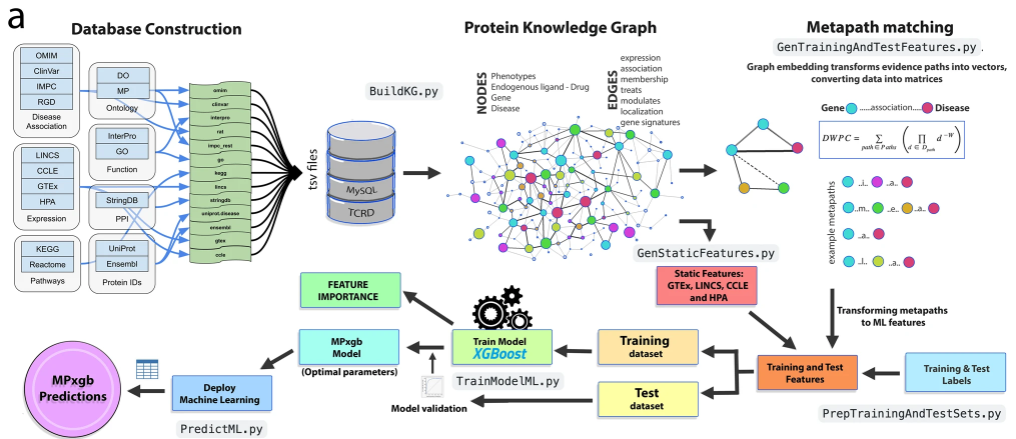
作者基于Target Central Resource Database 蛋白知识图谱和通过元路径匹配将证据路径转换为向量,然后提取了基因和疾病之间的特征,最后使用称为MPxgb(AD)的XGBoost训练和优化了模型。
基于该知识图谱分析确定了潜在的AD(老年痴呆)风险基因:FRRS1, CTRAM, SCGB3A1, FAM92B/CIBAR2, and TMEFF2. FRRS1 and FAM92B被认为是dark genes,但是TREM2-TYROBP, IL-1β-TNFα, and MTOR-APP是风险基因,提示与AD的发病机制相关。
作者通过实验验证了预测的生物标志物的准确性:
(1)在人类死后 AD 大脑中,前 20 个 MPxgb(AD) 预测基因中有 5 个在 mRNA 水平上发生了改变,9 个在蛋白质水平上发生了改变。
(2)siRNA 介导的CRTAM、FOXP4、GRIN2C、LILRA3、PIBF1、SCGB3A1和TXNDC12 敲除减少炎症诱导的 tau 磷酸化。
(3)一些底部 MPxgb(AD) 预测基因显示 AD 相关性,但与免疫/炎症无关;
相关分析表明,预测的前 20 个 MPxgb(AD) 基因中有两个(SCGB3A1 和 CRTAM)与免疫相关。
第三篇文章是2022年1月23日发表在ICLR2022上的文章“OntoProtein:Pro
-tein Pretraining with Gene ontology embedding”。

作者将GO(基因本体)中的结构用于蛋白质预训练模型的通用框架,构建了一个新的大规模知识图谱,该知识图谱中的所有节点由GO及其相关蛋白质组成,基因注释文本或蛋白质序列描述。
OntoProtein基于基因本体嵌入的蛋白质预训练模型,是第一个将外部知识集成到蛋白质预训练中的通用框架。受生物特征机制的启发,作者设计了一种知识感知的负采样策略。
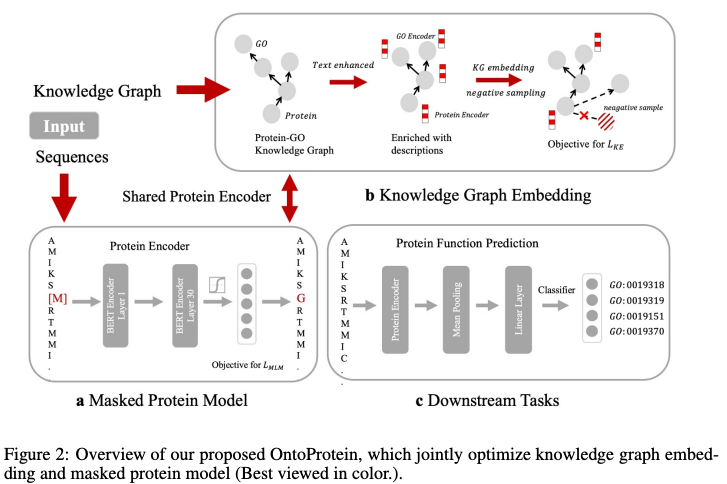
实验结果表明,OntoProtein作为基因本体嵌入的蛋白质预训练语言模型超越了最优的模型,并在蛋白质-蛋白质相互作用和蛋白质功能预测方面比基线模型产生了更好的性能。
该蛋白质预训练模型超过了基线模型TAPE。
参考文献:
[1] A knowledge graph to interpret clinical proteomics data
[2] Machine learning prediction and tau-based screening identifies potential Alzheimer’s disease genes relevant to immunity
[3] OntoProtein:Protein Pretraining with Gene ontology embedding
[4] Plasma proteome profiling discovers novel proteins associated with non‐alcoholic fatty liver disease
欢迎加入微信群聊交流






