CVPR2020 | HANet:通过高度驱动的注意力网络改善城市场景语义分割
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转载自:AI算法修炼营

论文地址:https://arxiv.org/abs/2003.05128
代码地址:https://github.com/shachoi/HANet
该论文利用了城市场景图像的内在特征,并提出了一个通用的附加模块,称为高度驱动的注意力网络(HANet),用于改善城市场景图像的语义分割。
将城市场景图像进行水平分割后(分为上部、中部、下部),像素级类别分布彼此之间存在显著差异。同样,城市场景图像具有其自身独特的特征,但是大多数语义分割网络并未反映出体系结构中的此类独特属性。HANet网络架构结合了利用垂直属性来有效处理城市场景数据集的能力。HANet根据像素的垂直位置来选择相关特征并进行像素类。
经过广泛的定量分析表明,HANet模块能既简单又经济高效地添加到现有模型中。在基于ResNet-101的分割模型中,该方法在Cityscapes基准上实现了新的SOTA性能。此外,文中通过可视化和解释注意力图来表明所提出的模型与在城市场景中观察到的事实是一致的。
由于城市现场图像是由安装在汽车前部的摄像头捕获的,因此城市现场数据集仅由道路行驶图片组成。这导致有可能根据空间位置,特别是在垂直位置,引入共同的结构先验。
下图显示了垂直位置上的城市场景数据集的类别分布。尽管少数类别的像素在整个图像区域中都是主要的(图1(a)),但类别分布对垂直位置有很大的依赖性。也就是说,图像的下部主要由道路组成,而中间部分则包含各种相对较小的对象。在上部,建筑物,植被和天空是主要对象,如图1(b)所示。
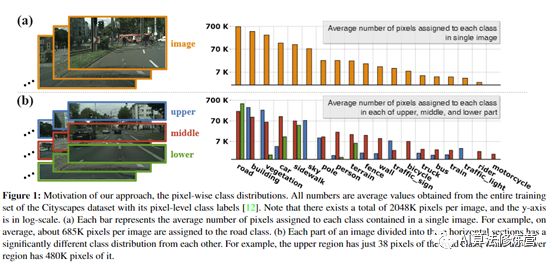
如果能够识别出图像中任意像素所属的部分,将有助于语义分割中的像素级分类。提出了一种新型的高度驱动的注意力网络(HANet),作为城市场景图像语义分割的通用附加模块。给定一个输入特征图,HANet提取代表每个水平划分部分的“高度上下文信息”,然后从高度上下文信息中预测每个水平部分中特征或类别。
论文主要贡献:
提出了一种新颖的轻量级附加模块HANet,可以轻松地将其添加到现有模型中,并通过根据像素的垂直位置通道的注意力驱动来提高性能。通过广泛的实验,我们证明了该方法的有效性和广泛适用性.
通过将HANet添加到DeeplabV3+基线中,在Cityscapes数据集上获得了最新的性能,而计算和内存开销可忽略不计。
可视化并解释各个渠道上的注意力权重,并以实验方式证实了高度位置对于改善城市场景中的片段化性能至关重要。
2. 背景
语义分割的模型中,在捕获高级语义特征的同时保持特征图的分辨率对于实现语义分割的高性能至关重要。主要方法有:
跳级连接(利用编码器层中较早存在的高分辨率特征来恢复解码器层中的对象边界)
空洞卷积(在不增加计算量的情况下,增加感受野的大小)
自注意力机制(捕获远程依赖)
关注类别的边界信息
根据空间位置的不同,城市场景图像通常包含共同的结构先验。就类别分布而言,图像的每一行都有明显不同的统计信息。从这个意义上说,在城市场景分割的像素级分类过程中,可以分别捕获表示每一行的全局上下文信息即高度上下文信息来估计信道的权重。
因此,提出了HANet,其目的是:i)提取高度方向的上下文信息,ii)使用上下文计算高度驱动的注意权重,以表示每行的特征(中间层)或类(最后一层)的重要性。。
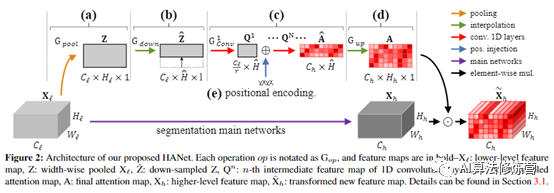
压缩空间维。在宽度合并操作的最大合并和平均合并之间进行选择是一个超参数,并根据经验设置为平均合并。
(c)computing height-driven attention map
高度驱动的通道式注意力图A是由卷积层获得的,这些卷积层将宽度合并和插值后的特征图ˆZ作为输入。在生成注意力图过程中,采用卷积层而不是全连接层(与SENet有区别),以便在估计注意力图时考虑相邻行之间的关系,因为每一行都与其相邻行相关。同时,为了允许这些多个功能和标签,在计算注意力图时使用了S形函数,而不是softmax函数。这些由N个卷积层组成的运算可以写成:
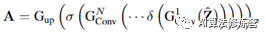
(c)positon encoding
当人类识别出驾驶场景时,他们对特定物体的垂直位置具有先验知识(例如,道路和天空分别出现在下部和上部)。受此观察的启发,将NLP领域的正弦位置编码添加到HANet中。具体位置编码定义为:
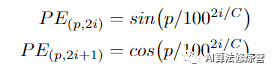
在计算注意力图之后,可以将给定的较高级特征图Xh转换为通过A和Xh的元素乘积获取的新表示。每个通道的单个缩放向量是由每个单独的行或多个连续行每组派生的,因此该向量与水平方向一起进行计算,公式为:
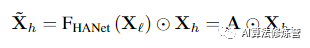
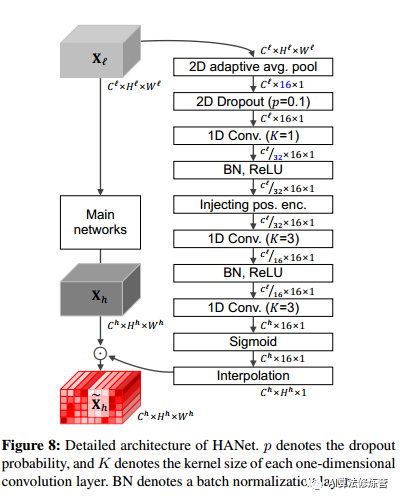
HANet具体的结构图如上图所示。在Pytorch中使用二维自适应平均池化操作2来实现针对粗略注意的宽度方向池化和插值。此后,应用了dropout层和三个一维卷积层。
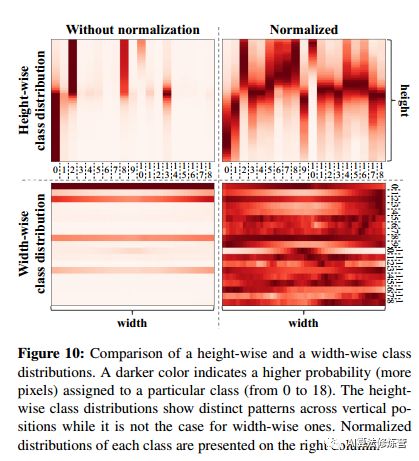
如上图所示,宽度方向上的列与高度方向上的相应的列类别分布相似。因此,相对于图像的水平位置提取不同的信息将相对困难。同样,从经验上讲,使用注意力网络与预测宽度类别分布时,没有观察到有意义的性能提升。这证实了HANet概念的基本原理,该思想提取并合并了高度方向的上下文信息,而不是宽度方向的上下文信息。
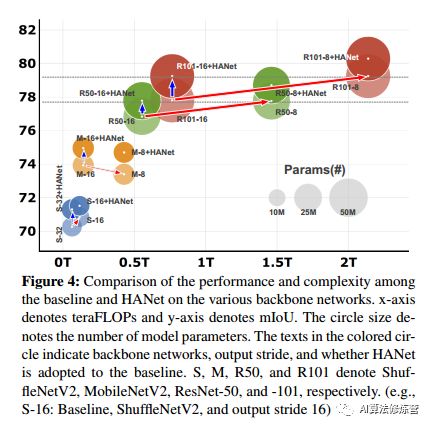
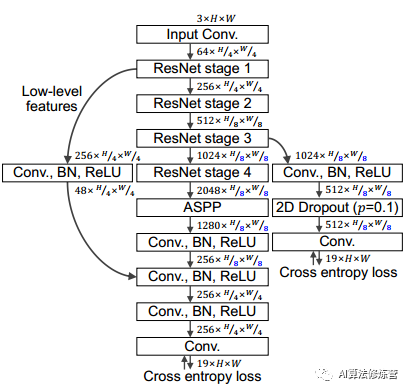
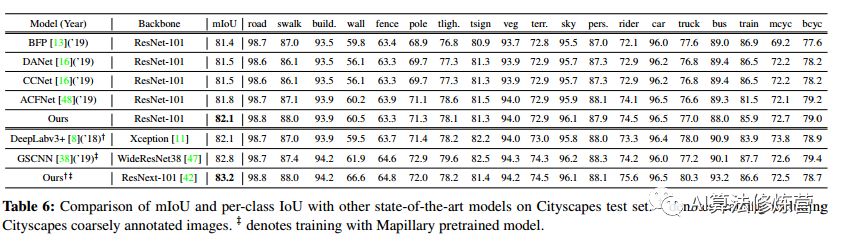
为了与其他最新模型进行比较,使用经过精细注释的训练和验证集,9000次迭代进行训练。在采用ResNext-101 骨干的情况下,额外使用了粗注释的图像,并且该模型在Mapillary 上进行了预训练。crop和批量大小分别更改为864×864和12。将基于ResNet-101和ResNext-101的最佳模型与Cityscapes测试集上的其他最新模型进行了比较,模型实现了最新的性能。
重磅!CVer-图像分割 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-图像分割 微信交流群,目前已汇集1200人!涵盖语义分割、实例分割、全景分割和医学图像分割等。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流等群。
一定要备注:研究方向+地点+学校/公司+昵称(如图像分割+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!


