“LSTM之父”新作:一种新方法,迈向自我修正的神经网络

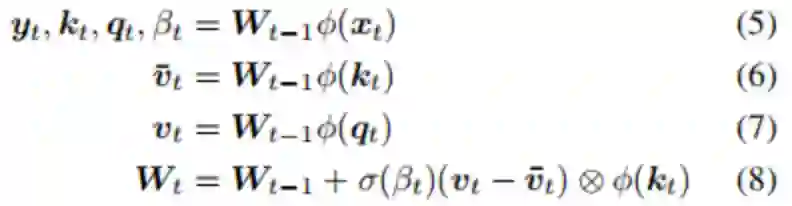

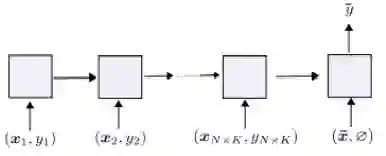
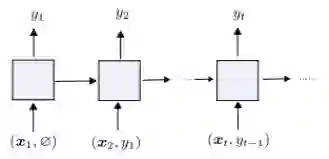
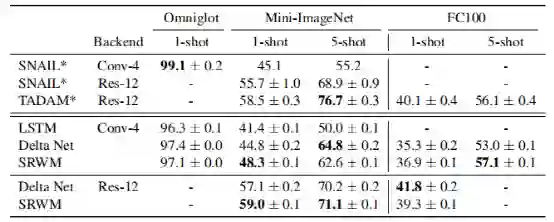
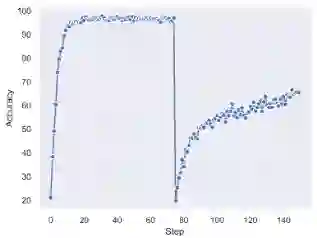
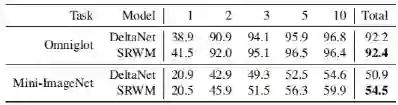
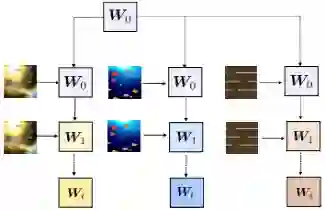
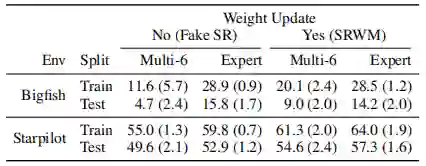
总体而言,所提出的SRWM性能良好。将SRWM与一般的SNAIL模型进行比较,SRWM在Mini-ImageNet2上实现了独立于视觉后端(Conv-4或Res12)的具有竞争力的性能。


登录查看更多
相关内容
专知会员服务
32+阅读 · 2020年2月1日

相关VIP内容
专知会员服务
32+阅读 · 2020年2月1日
相关资讯
相关论文