深度网络自我学习,最终实现更少样本的学习
炎炎夏季,枝头的蝉鸣,烈阳高照,让所有人都不愿意接受太阳的洗礼,都愿意在凉凉的空调房内享受,如果你现在在小憩,那就趁着有着凉爽的室内,和我一起来一次CVPR最前沿文章的探索,也许你可以在其中获得新的创新,这样才对得起室内的停留。个人建议,不管多么炎热,还是抽空运动一番,让自己流些汗,这样才会有更健康的体魄,去更深入的探索。(尤其是我们长期久坐的ITer Man)

接下来我们就开始今日的主题:自我学习,最少的样本去学习。听到这个,大家会想到剪枝、压缩神经网络。今天这个更加有趣,现在我们开始欣赏学术的盛宴!
一、简单摘要
本次这个技术主要是一个概念上简单、灵活和非常小样本的学习框架,其中分类器必须学会识别新的类,每个分类器只给出几个例子。本次这个方法叫做关系网络(RN),是端到端训练的。在meta-learning过程中,它学会学习一种深度距离度量来比较数据集中的少量图像,每个图像都是为了模拟few-shot设置而设计的。一旦经过训练,RN就能够通过计算查询图像与每个新类的少数示例之间的关系分数来对新类的图像进行分类,而无需进一步更新网络。除了在few-shot学习上提供更好的性能外,该框架很容易扩展到zero-shot学习。对五个基准的广泛实验表明,本次简单的方法为这两个任务提供了一个统一和有效的方法。
二、前言
深度学习模型在视觉识别任务[1,2,3]中取得了巨大的成功。然而,这些有监督的学习模型需要大量的标记数据和大量的迭代来训练它们的海量参数。由于注释成本的原因,这严重限制了它们对新类的可伸缩性,根本地限制了它们对新出现的(例如新的消费设备)或罕见(例如稀有动物)类别的适用性,在这些类别中,可能根本不存在许多注释过的图像。相比之下,人类很擅长在很少直接监督的情况下识别物体,或者根本就没有,如few-shot[4]或zero-shot[5]学习。例如,孩子们从一本书中的一幅画中概括出“斑马”的概念是没有问题的,或者听到它的描述就像一匹条纹的马。
[1] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, 2012.
[2] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, 2016.
[3] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. ICLR, 2015.
[4] B. Lake, R. Salakhutdinov, J. Gross, and J. Tenenbaum. One shot learning of simple visual concepts. In CogSci, 2011.
[5] C. H. Lampert, H. Nickisch, and S. Harmeling. Attributebased classification for zero-shot visual object categorization. PAMI, 2014.
由于传统的深度学习方法未能很好地处理每个类别的一个或几个例子,并受到人类few-shot或zero-shot学习能力的启发,最近人们对机器one/few-shot或zero-shot学习的兴趣重燃。既然人类可以具有该能力,那么深度学习按现在的发展,应该可以简单去实现。因此,少样本学习成为了近年来深度学习领域非常重要的一个前沿研究问题。
Few-shot学习旨在识别新的视觉类别从非常少的标记例子。可用性只有一个或极少数例子挑战标准,深度学习中的“微调”实践。数据扩充和正则化技术可以减轻过度拟合。在这样一个有限的数据制度,但他们没有解决。因此,few-shot学习的方法经常将训练分解为辅助元学习,可转移知识在阶段中学习的良好的初始条件,嵌入或优化策略。然后,通过使用学习优化策略[调或在不更新网络权重的前馈传递中计算目标few-shot学习问题。Zero-shot学习也面临着一个相关的挑战。
现有的few-shot学习方法虽然有很好的应用前景,但要么需要复杂的推理机制,要么需要复杂的递归神经网络(RNN)结构,要么需要对目标问题进行微调。本次的方法与其他旨在为一次性学习提供有效度量的方法最为相关。当它们专注于可转移嵌入的学习和预先定义一个固定度量(例如,欧几里德)时,就进一步学习一个可转换的深度度量,用于比较图像之间的关系(few-shot学习),或者图像与类描述之间的关系(zeao-shot学习)。通过表示更深层解的归纳偏差(嵌入和关系模型的多个非线性学习阶段),可以更容易地学习到问题的一般解。
具体来说,本次提出了一个双分支关系网络(two-branch RN),它通过学习比较查询图像和few-shot标记的样本图像来实现few-shot识别。首先,嵌入模块生成查询和训练图像的表示。然后,通过一个关系模块对这些嵌入进行比较,该模块确定它们是否来自匹配类别。定义了一个基于场景的策略,嵌入和关系模块是meta-learning端到端的,以支持few-shot学习。这可以看作是将可学习的非线性比较器(而不是固定的线性比较器)扩展到包括可学习的非线性比较器的策略。本次的方法优于以前的方法,同时更简单(没有RNN)和更快(没有微调)。提出的策略也直接推广到zeao-shot学习。在这种情况下,样本分支嵌入一个单一的类别描述而不是单个样本训练图像,而关系模块学习比较查询图像和类别描述嵌入。
总的来说,本次技术的贡献是提供一个简单的框架,包含了few-shot或zero-shot学习。对四个基准的评估表明,它提供了令人信服的整体性能,同时比备选方案更简单、更快。
三、模型
One-Shot
关系网络(RN)由两个模块组成:嵌入模块f和关系模块g,如下图所示。
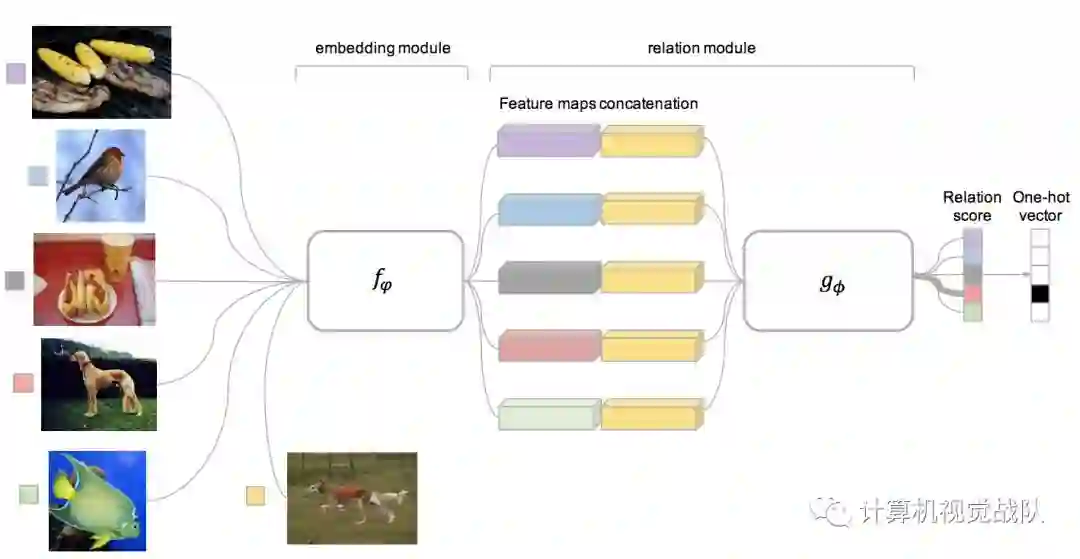
查询集中的样本xj和样本集S中的样本xi通过嵌入模块f提供,该模块生成特征映射f(Xi)和f(Xj)。特征映射f(Xi)和f(Xj)与算子C(f(Xi),f(Xj))相结合。
在本工作中,假设C(·,·)是深度特征映射的连接,尽管其他选择是可能的。将样本和查询的组合特征映射输入到关系模块g中,最终生成一个0~1的标量,表示xi和xj之间的相似性,称为关系评分。因此,在C-way的one-shot设置中,为一个查询输入xj和训练样本集示例xi之间的关系生成C关系评分ri,j。
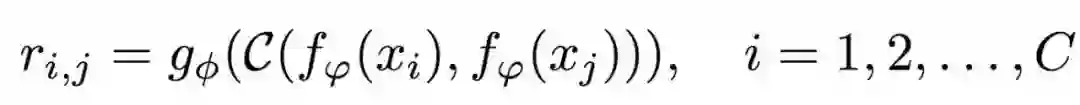
K-shot
对于K<1的K-shot,在每个训练类的所有样本的嵌入模块输出上逐个加和,形成这个类的特征映射。此集合类级别的特征映射与上面所述的查询图像特征映射相结合。因此,在one-shot或fewshot设置中,一个查询的关系得分数量总是C。
目标函数
使用均方误差(MSE)损失对模型进行训练,将关系评分ri,j回归到基本真理:匹配对具有相似性1,错配对具有相似性0:
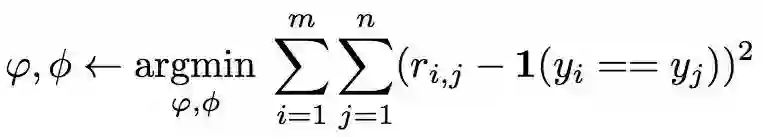
MSE的选择有些不标准。主要的问题可能是标签空间{0,1}的分类问题。然而,在概念上,预测的关系分数,这可以被认为是一个回归问题,尽管对于实际情况(真实值),只能自动生成{0,1}目标。
Zero-shot
Zeao-shot学习类似于one-shot学习,它给出了一个数据来定义要识别的每一个类。然而,它没有为每个C类训练类别提供一张one-shot图像的支持集,而是为每个C类包含一个语义类嵌入向量Vc。修改提出的框架以处理one-shot的情况很简单:由于支持集使用了不同的语义向量形式(例如属性向量而不是图像),除了用于图像查询集的嵌入模块f1之外,还使用了第二个异构嵌入模块f2。在此基础上,应用关系网g。因此,每个查询输入xj的关系评分为:
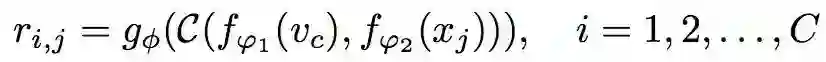
Zeao-shot学习的目标函数与few-shot学习的目标函数相同。
说了这么多,估计也很期待,估计看文字看累了,接下来我们以图为主。
网络框架
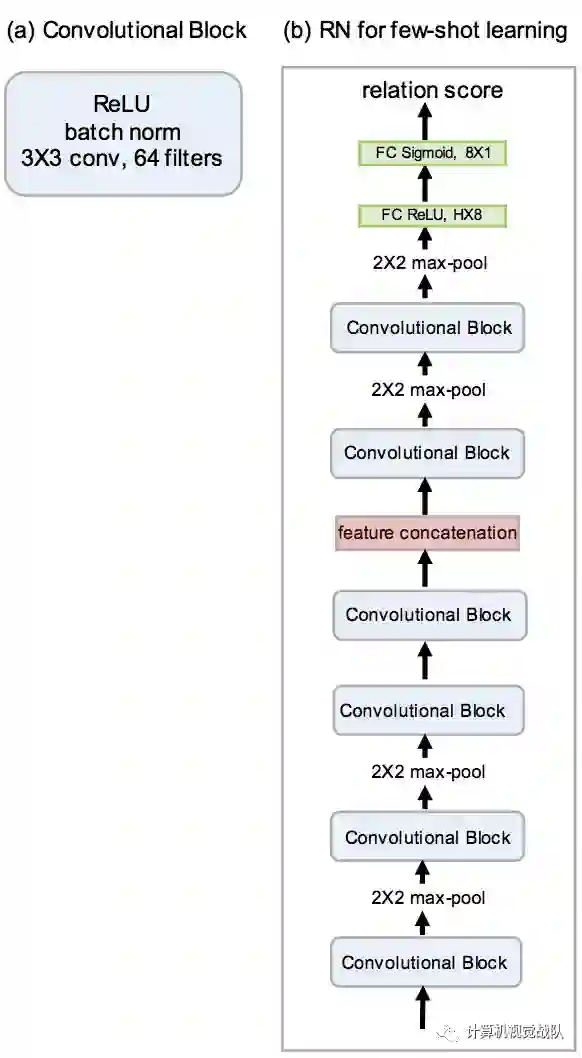
由于大多数少有的学习模型使用四个卷积块用于嵌入模块,为了进行公平的比较,我们遵循相同的体系结构设置,参见上图。更具体地说,每个卷积块分别包含一个64个滤波器,3×3的卷积、一个批归一化和一个ReLU非线性层。前两个区块也包含一个2×2的最大池化层,而后两个块则没有。
这样做是因为需要在关系模块中为进一步的卷积层提供输出特征映射。关系模块由两个卷积块和两个全连接层组成。每个卷积块为3×3卷积,64个滤波器,然后是批归一化、ReLU线性和2×2最大池化。
对于Omniglot和MiniImageNet,上一个最大池化层的输出大小为H=64,H=64∗3∗3=576。两个全连接层分别为8维和1维。除了输出层是Sigmoid之外,所有全连接层都是ReLU,以便为网络体系结构的所有版本在一个合理的范围内生成关系分数。
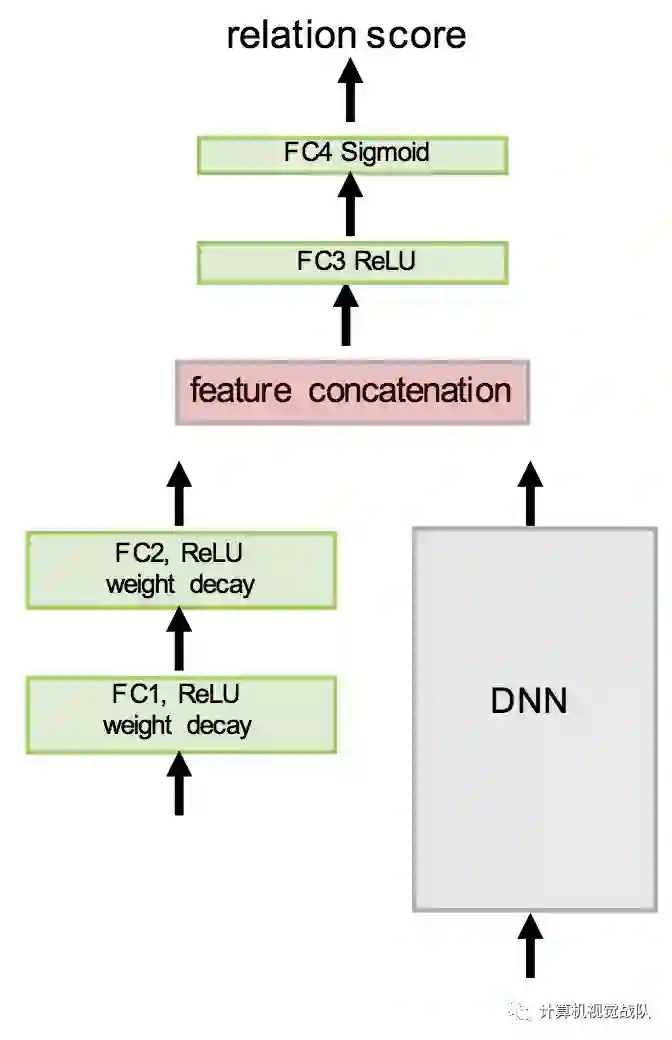
Zeao-shot学习体系结构如下图所示。在该体系结构中,DNN子网是在ImageNet上预先训练的现有网络(例如,Inception或ResNet)。
四、实验
在少样本学习上,使用目前领域内都在使用的 Omniglot 和 MiniImagenet 作为基准数据集,而在零样本学习上,则使用广泛采用的 AwA 和 CUB 数据集进行测试。无论在哪个数据集上,提出的模型都取得了state-of-the-art或者相当好的结果:
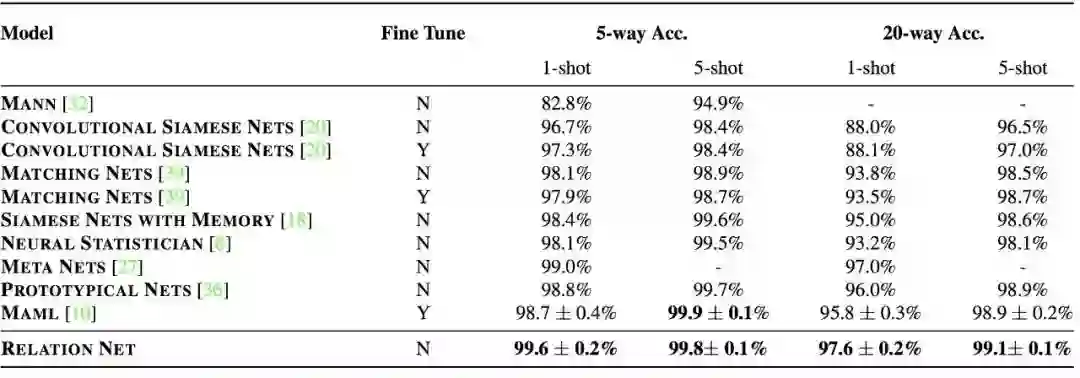
Few-shot分类。结果的准确性平均超过1000次测试,95%的置信区间报告。表现最好的方法会被加粗显示,以及其他置信区间重叠的方法。
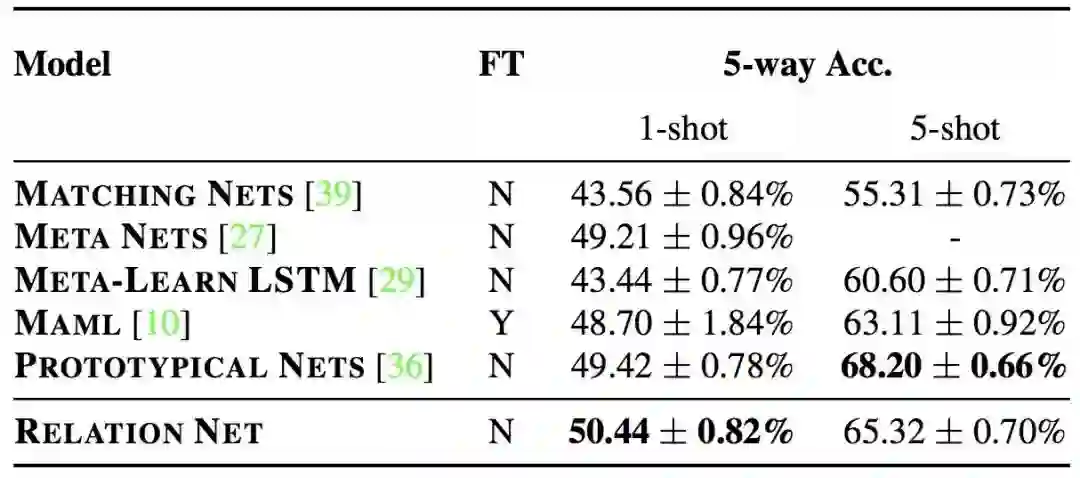
miniImagenet上的Few-shot分类精度很低。所有的准确性结果平均超过600次测试,并报告95%的置信区间。对于每项任务,都会突出显示性能最好的方法,以及置信区间重叠的其他方法。
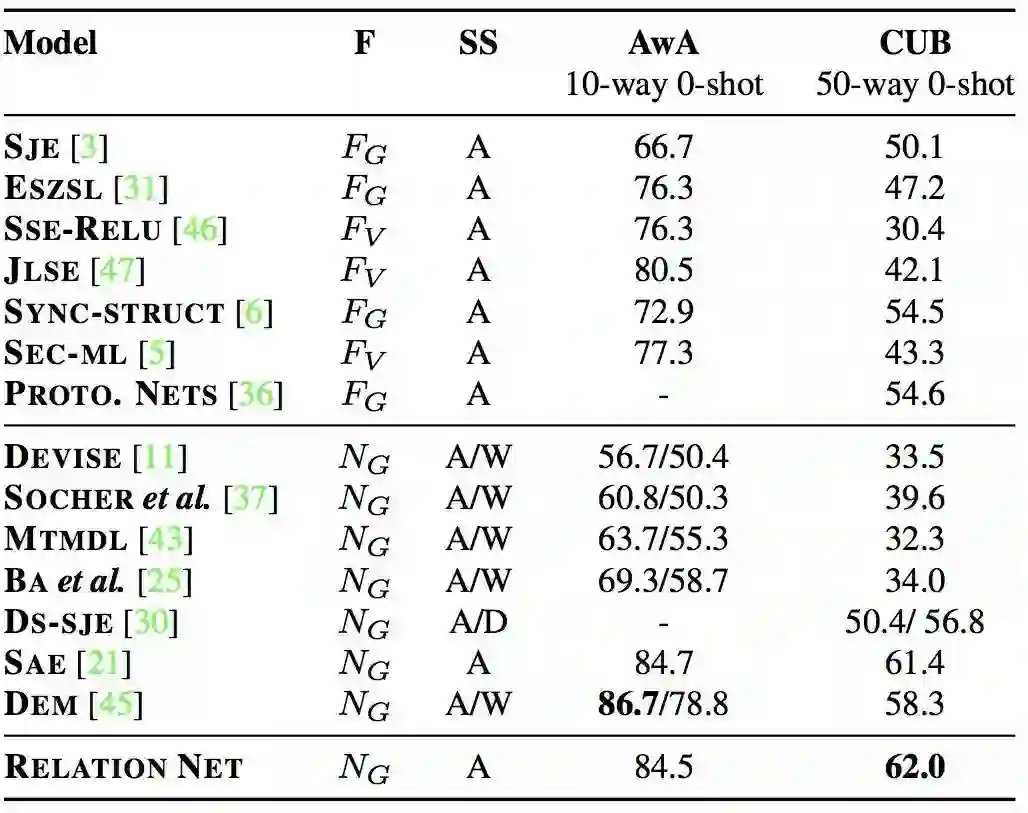
SS: semantic space; A: attribute space; W: semantic word vector space; D: sentence description (only available for CUB). F: how the visual feature space is computed; For non-deep models: FO if overfeat is used; FG for GoogLeNet; and FV for VGG net.
Why does Relation Network Work?
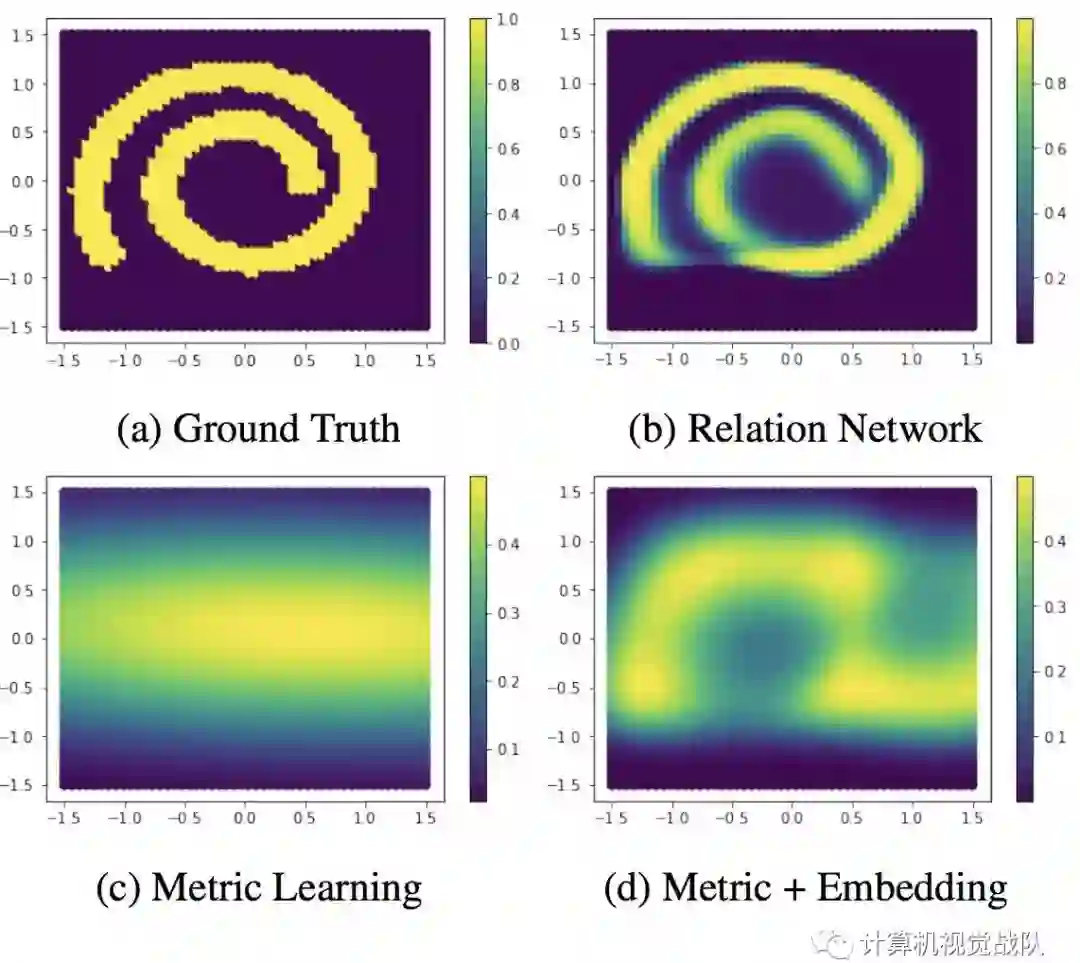
因此,做了额外的实验来验证。这个实验是一个2维数据的比对实验。比如两个数据(1,2)和(-2,-1),这两个数据看起来是不相关的,但是它们在某一些状态下可能属于同一个类别。
那么这种情况,其实传统的人为设计的度量方式就会失效。只能通过神经网络去学习这种度量。所以如下图这样复杂的螺旋曲线关系数据情况,可以通过RN可以学的不错。
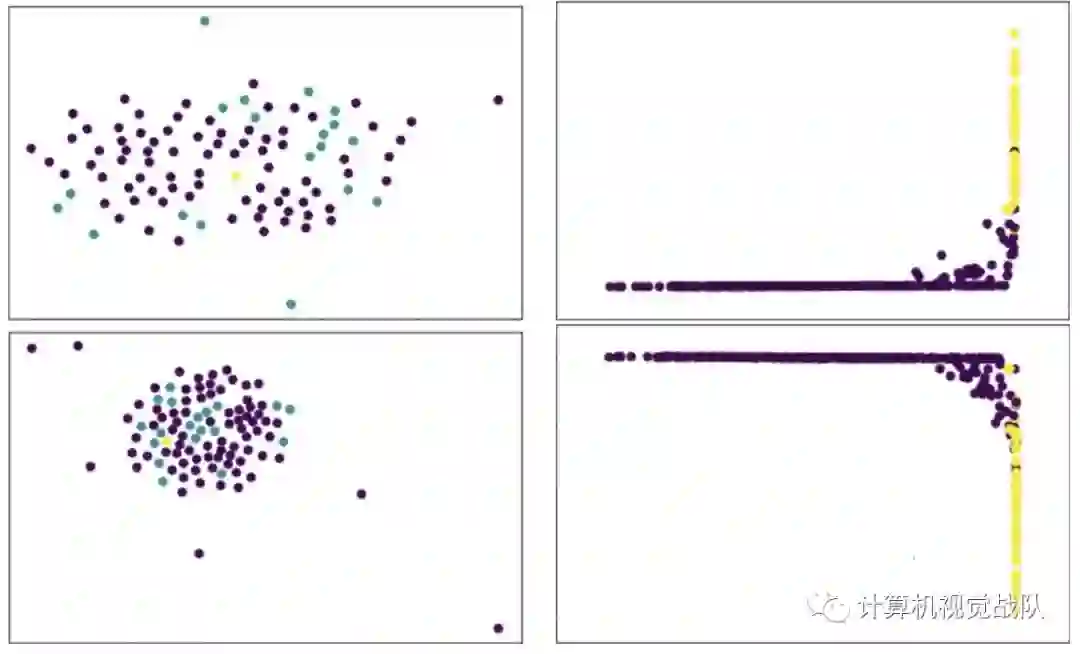
在一个真正的问题中,比较嵌入的难度可能不是这么极端,但它仍然具有挑战性。我们定性地说明了匹配两个示例Omniglot查询图像(嵌入到2D,下图(左)的挑战,方法是显示由匹配(青色)或不匹配(洋红)所显示的真实样本图像到两个示例查询(黄色)的类似图。在标准假设下,青色匹配样本应该是与带有某种度量的黄色查询图像最接近的邻域(欧几里得、余弦、马哈拉诺比)。
但是我们可以看到,匹配关系比这更复杂。在下图(右)中,用每个查询样本对的2D PCA表示来绘制相同的两个示例查询,由关系模块的倒数第二层表示。我们可以看到,RN已经将数据映射到一个空间,其中匹配对是线性可分的。
五、总结
提出的一个简单方法,称为关系网络的Few-shot和Zero-shot学习。关系网络学习用于比较查询和样本项的嵌入和深度非线性距离度量。用间歇训练来训练网络端到端,以有效的Few-shot学习来调整嵌入和距离度量。这种方法比最近几次的元学习方法简单得多,效率更高,并且产生了最先进的结果。它进一步证明了有效的常规和广义Zero-shot设置。

深度学习算法实践
作者:吴岸城 编著

深度学习、优化与识别
作者:焦李成、赵进、杨淑媛、刘芳



