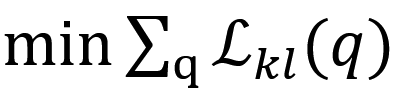近日,哈工大深圳 HLT 研究组刷新了 Allen AI 平台的常识推理问答 ProtoQA 任务榜单,该技术方案两次登顶 Leadboards 第一名。ProtoQA 榜单由 UMass Amherst 提出,目标是测试人工智能系统的常识推理能力 [1]。
常识是人工智能研究的重要内容,机器常识或机器对开放世界的理解和推理能力一直被认为是人工智能和自然语言理解的重要组成部分。常识问答则是机器推理上的一个重要的应用方向,目的是帮助计算机通过已有的知识推理判断未见过的输入信息,从而使计算机更自然地理解人们的表达。
长时间以来,许多研究始终致力于推进这一领域的发展,特别是近年来采用预训练语言模型、知识图谱、提示学习等新技术的方法得到广泛研究。尽管一些模型在选择式的常识问答数据集上(如CommonsenseQA [2])超过人类水平,但是在没有预先给定选项的场景下,如何基于常识和背景知识进行生成式的推理以获得答案仍旧是一个巨大的挑战。
ProtoQA 新挑战:更难的任务、更开放的问题、更贴近真实场景
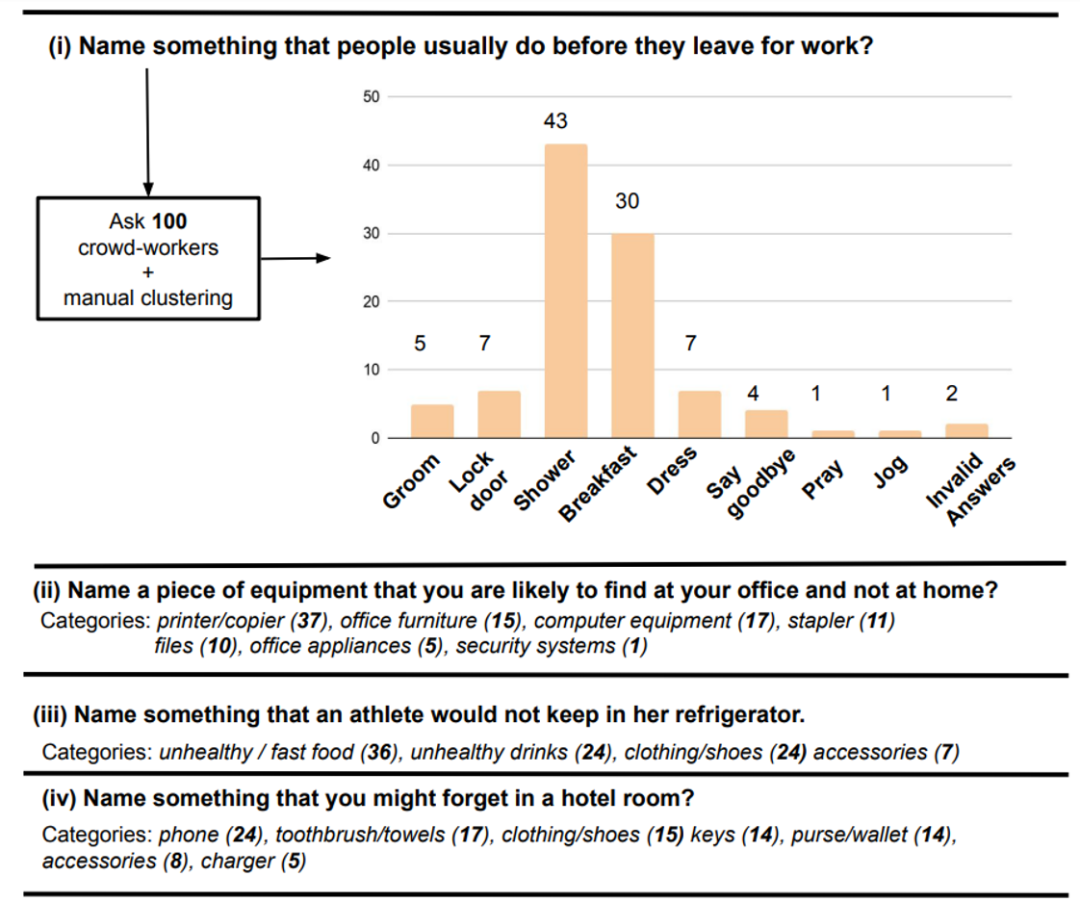
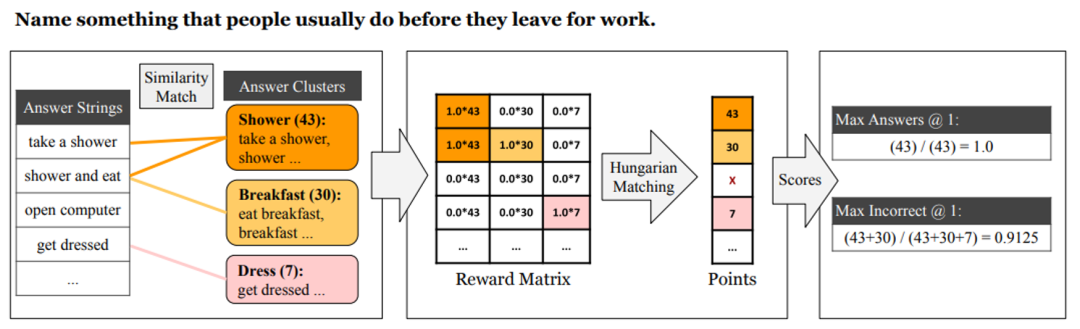
ProtoQA 是开放场景下基于常识推理的生成式问答基准数据集。例如说出人们在离开家上班之前通常会做的事情 (Name something that people usually do before they leave for work?)(图 1)
![]() 图 1:ProtoQA 数据集示例 [1]
图 1:ProtoQA 数据集示例 [1]
相较于众多的单选题式常识问答数据集,ProtoQA 的难点在于:1)该数据集没有提供候选答案选项,需要模型自行生成答案;2)每个问题可以有多个合乎常识的答案,但是越典型(普遍)的答案得分越高。
因此,需要模型评估和生成更典型的答案。计分有两种模式(下图 2),Max Answers @ k:限定总回答数量的最大得分,和 Max Incorrect @ k:限定回答错误答案数量的最大得分。
![]() 图 2:ProtoQA 计分规则 [1]
图 2:ProtoQA 计分规则 [1]
该基准数据集由 University of Massachusetts, Amherst 的研究者们在 2020 年提出,设计并提出的目标是测试人工智能系统对常识问题生成有效答案的能力。它是 Machine Common Sense (MCS) DARPA 项目的一部分,由 AI2 托管。训练集是从一个长期运营的国际游戏节目 FAMILY-FEUD 中现有问题集中收集的约 9k 个问答,隐藏评估集的答案则是通过收集 100 名人工回答创建的,共 102 个问答。
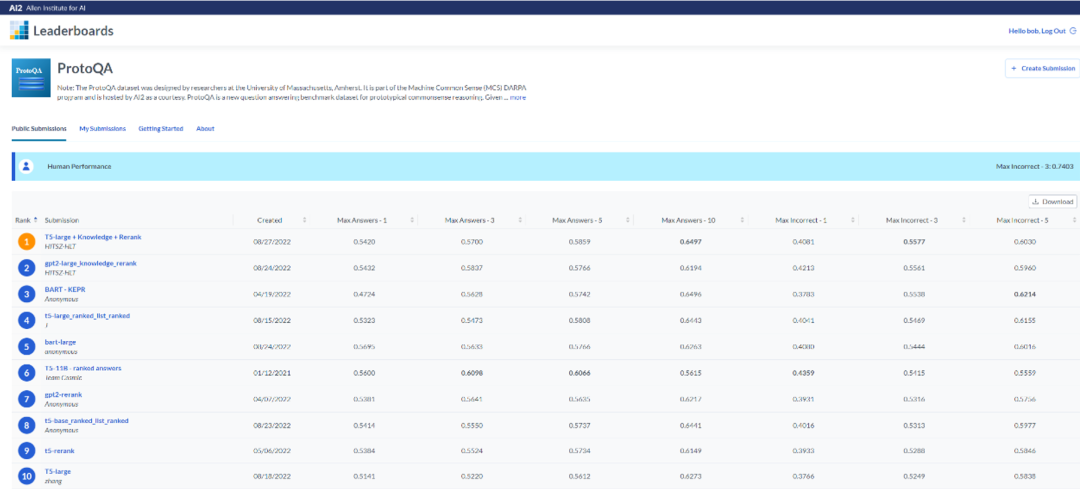
哈工大深圳 HLT 研究组于 2022 年 8 月 24 日获得 AI2 Leaderboards 中 ProtoQA 榜首。而后另一模型再次刷新榜首的记录。目前霸榜前两名。榜上第三和第六名分别被匿名团队和 Team Cosmic 获得。此外,还有 CMU/Bosch/USC,UMass Amherst,MOWGLI / USC INK Lab,USC LUKA,MOWGLI / USC LUKA,MOWGLI / Stanford 等团队参加(以上为非匿名团队)。
相关链接: https://leaderboard.allenai.org/protoqa/submissions/public
![]() 图 3:ProtoQA 榜单
图 3:ProtoQA 榜单
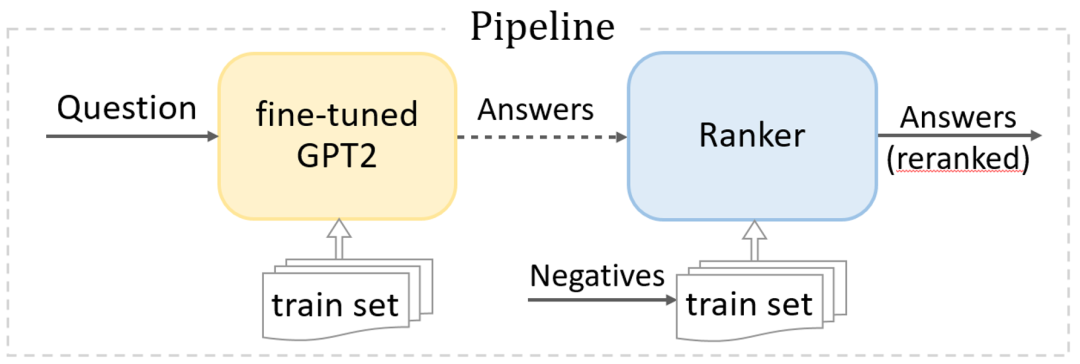
HITSZ-HLT 研究组提出的掩码模型重排序策略
对于该答案生成问题,HITSZ-HLT 研究组使用了先采样后排序的流水线框架(下图 4)。再由掩码模型计算采样结果的典型程度,将该数值经过sigmoid函数转换为是典型答案的概率,最后根据概率值降序输出最终的回答列表。其中,生成模型在数据集上微调,每个答案的权重均为 1;掩码模型学习不同答案的典型程度,具体训练过程如下:
-
对给定问题及其所有答案,计算每一个答案的频率,作为目标分布函数,记为 freq。其中,正样本的频数是其典型值,负样本的为零;
-
将每一个答案分别串接问题后面作为掩码模型的输入,由模型计算一个典型指数。对所有答案计算出的典型指数进行 softmax 归一化,得到预测分布,记为σ;
-
目标是让预测分布σ拟合目标分布 freq,根据 KL 散度来更新模型参数,记为 L_kl;
-
上述过程仅学习了正样本和负样本典型指数的相对大小,为了让模型更好地区分正样本和负样本,使用二元交叉熵给来约束负样本的取值,记为 L_bce;
-
目标函数为
![]() ,
当没有负样本时,该策略也同样适用目标函数为
,
当没有负样本时,该策略也同样适用目标函数为
![]()
-
使用 MRR(Mean Reciprocal Rank)来评价掩码模型的训练效果,保存 MRR1 值最大的模型。
![]() 图 4:掩码模型重排序流水线框架
图 4:掩码模型重排序流水线框架
实验结果表明,掩码模型可以学习到哪些答案更为典型,且加入适当负样例和相关知识可以提升掩码模型的区分能力。这里相关知识指的是题干中关键词的词定义,来自 WordNet [3]。
HITSZ-HLT 团队提出的掩码模型训练方法可适用于多个模型且计算快速、效果稳定。掩码模型中,考虑到各模型的特性和上限,DeBERTa 的效果最佳,明显优于 RoBERTa 和 BERT。此外,应用生成式模型 GPT-2,BART 和 T5 进行采样答案重排序的结果相较生成模型微调结果有大幅度提升,且不同生成模型间重排序的差距明显小于微调结果的差距。团队取得的榜首和榜二均由 DeBERTa 对生成模型重排序所得。
值得一提的是,直接将典型程度加入生成模型微调过程的损失计算仅平均提升约 3 个百分点,而重排序策略可以提升至少 11 个百分点。由此可见,借助掩码模型重排序比直接将典型程度加入生成模型的微调过程更有效得多。
HITSZ-HLT 团队表示这个工作为掩码语言模型在生成式常识问答上的应用提供一种可行的解决思路。同时,考虑到人们在回答问题时,除了特定的上下文外,还需要利用其丰富的世界知识,为此本研究在训练阶段借助 WordNet,并采用三种不同的策略为每个选项随机采样若干负样例,有效加强了模型的常识推理能力。
该模型优异的性能表现有力证明了掩码语言模型和自回归语言模型的结合在生成式问答任务上的强大优势,以及机器阅读理解模型可以通过构建合适的预训练 + 重排序方式实现超越复杂专业模型的表现。此外,除了重排序还可以通过强化学习的方式直接增强自回归语言模型的建模能力。
谈到常识问答目前的发展和趋势,HITSZ-HLT 团队表示,未来的常识问答会更注重几个方面的研究。首先是开放式问答,由机器自行从库中搜索并收集信息进行问答。其次通过对文本进行多步推理,从多条相关文本中获取答案的研究。最后是因果推理,即让模型像人类通过对相关数据分析进行因果发现,提取因果关系用于常识问答。
从应用上来说,这项工作可以为诸如人机对话场景提供很多技术支持,使得对话更为智能,帮助客服机器人、语音助手等更好地理解人类指令。
常识推理任务参与的同学有:罗璇、范创、张义策、黄仕爵、梁斌等。指导教师为徐睿峰教授和秦兵教授。项目工作也得到哈工大深圳 - 招商证券联合实验室的支持,江万国等参加了相关研发。相关研究工作近日已获自然语言处理国际顶级会议 EMNLP 2022 录用。
论文信息:Xuan Luo, Chuang Fan, Yice Zhang, Wanguo Jiang, Bing Qin and Ruifeng Xu*. Masked Language Models Know Which are Popular: A Simple Ranking Strategy for Commonsense Question Answering. Findings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP 2022 ), Abu Dhabi, UAE
[1] Michael Boratko, Xiang Li, Tim O’Gorman, Rajarshi Das, Dan Le, and Andrew McCallum. 2020. ProtoQA: A question answering dataset for prototypical common-sense reasoning. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1122–1136, online.
[2] Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. 2019. CommonsenseQA: A question answering challenge targeting commonsense knowledge. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4149–4158, Minneapolis, Minnesota.
[3] George A. Miller. 1994. WordNet: A lexical database for English. In Human Language Technology: Proceedings of a Workshop held at Plainsboro, New Jersey, March 8-11, 1994.
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
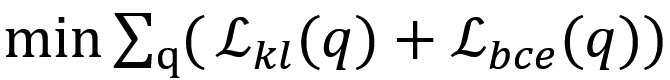 ,
,