哈工大讯飞联合实验室荣获多模态阅读理解评测VCR冠军
声明:本文转载自 哈工大讯飞联合实验室 公众号

2021年12月14日,哈工大讯飞联合实验室(HFL)以总分72.8获得多模态阅读理解评测VCR冠军。VCR评测(Visual Commonsense Reasoning)由华盛顿大学和AI2联合举办,旨在全面考察模型的多模态推理和理解能力。VCR评测举办以来吸引了众多知名高校和研究机构参加,其中包括快手、华盛顿大学、AI2、百度、腾讯微视、加利福尼亚大学伯克利分校(UC Berkeley)、微软、卡内基梅隆大学(CMU)、Facebook、Google等。
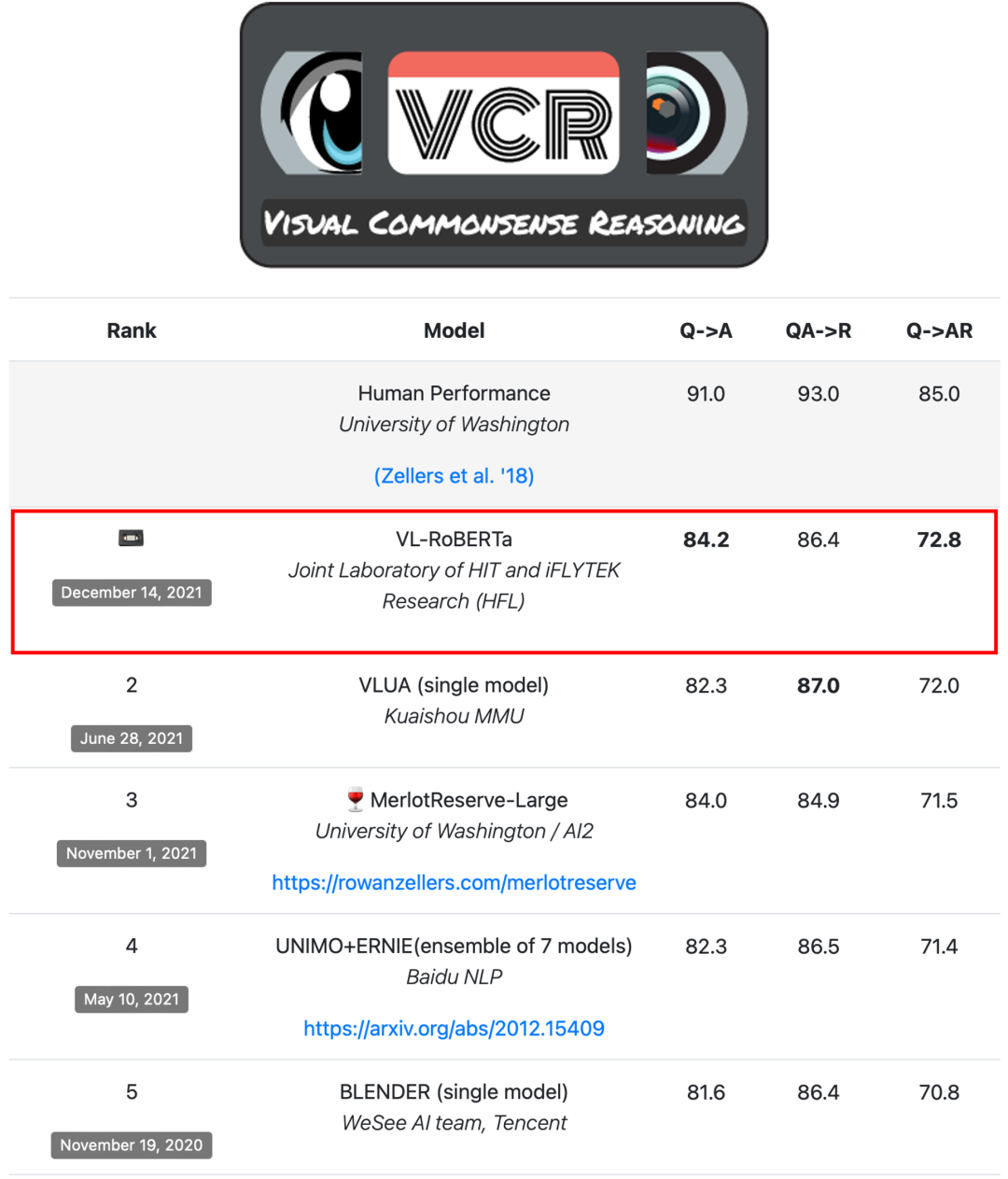
VCR评测
VCR评测任务是让机器识别并理解一张图片,并且回答图片场景中的问题,从A/B/C/D四个选项中选出正确答案。不仅如此,机器还需要从另外一组A/B/C/D选项中选择出答案的推理依据。VCR评测从以下三个指标对机器进行评测:
Q2A:根据图像&问题选出答案
QA2R:根据图像&问题&答案选出推理论据
Q2AR(综合指标):根据图像&问题选出答案和推理论据
因此,想要正确地回答问题并选择出推理依据需要机器对多模态信息进行综合处理,并且寻找图片与文本之间的关联,将问题内容与图像中的实体信息进行关联。这不论是相比早期哈工大讯飞联合实验室夺冠的权威阅读理解评测SQuAD还是多步推理阅读理解评测HotpotQA,对机器的综合理解能力提出了更高的要求,让机器同时具备能看会认以及能理解会思考的能力。

例如,在上面的例子中,问题是“[人物2]如何挣到她面前的钱?”。机器需要将人物实体与图片进行关联并且理解场景中的内容,从而选出答案“b) [人物2]通过演奏音乐挣钱”,以及选出答案的推理依据“c) [人物2]和[人物1]的手中都有乐器,所以可能通过街头卖艺来赚钱”。
夺冠系统
哈工大讯飞联合实验室提出的VL-RoBERTa多模态预训练模型以总成绩(Q2AR)72.8分位居VCR评测榜首,在Q2A及Q2AR指标上显著超越了榜单的第二名的成绩。
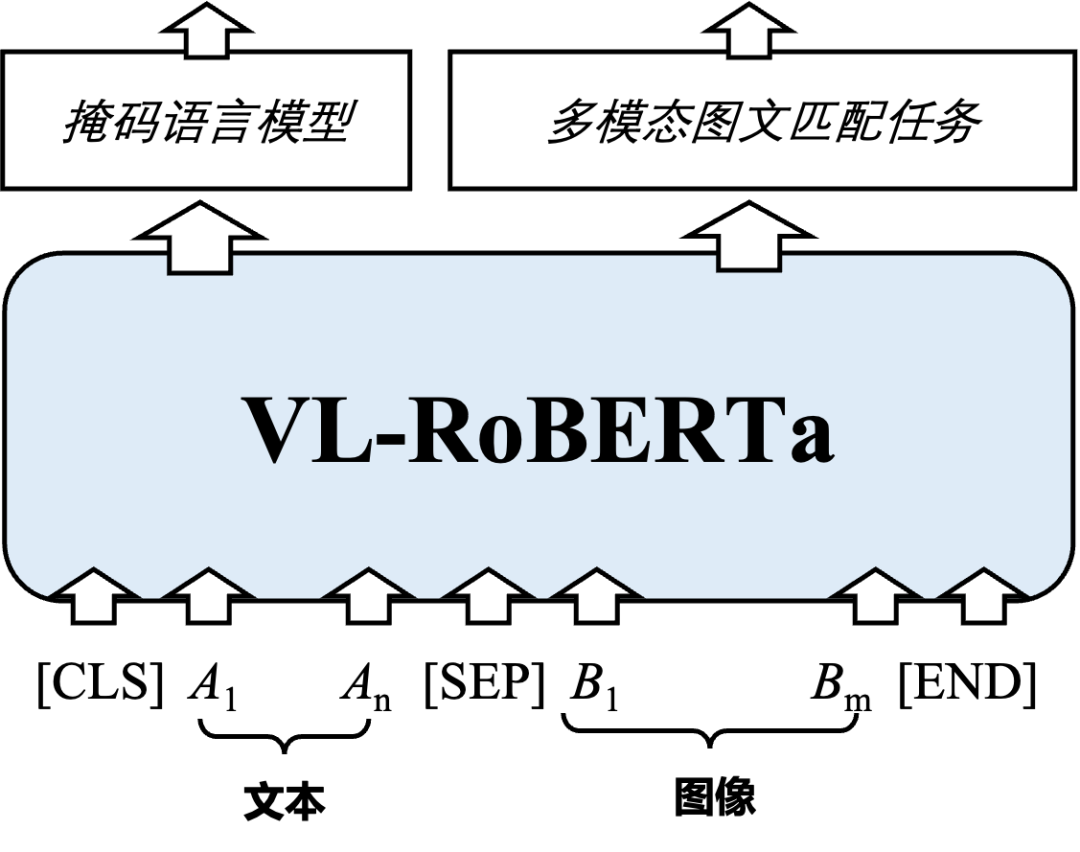
本次夺冠得益于团队自主研发的多模态预训练模型VL-RoBERTa。VL-RoBERTa在文本预训练模型RoBERTa的基础上加入了多模态处理模块,通过利用大规模文本数据以及多模态数据进行预训练,减少了对多模态数据的依赖,同时学习文本端的掩码语言模型(MLM)以及多模态图文匹配任务。同时,VL-RoBERTa创新地提出了一种增强式图文混合预训练机制(Enhanced Visual-Text Pre-training),构建重要图像目标与文本实体相对齐的预训练方法,使得模型能够精准地学习图像目标与文本实体之间的复杂语义关系,提升VCR任务的理解效果。
关于哈工大讯飞联合实验室(HFL)
哈工大讯飞联合实验室(HFL)是科大讯飞针对“讯飞超脑”项目计划,重点引进和布局的核心研发团队之一,由科大讯飞AI研究院与哈尔滨工业大学社会计算与信息检索研究中心(HIT-SCIR)共同创办。根据联合实验室建设规划,双方将在语言认知计算领域进行长期、深入合作,具体开展阅读理解、预训练模型、人机对话、智能校对、自动阅卷、类人答题等前瞻课题的研究。重点突破深层语义理解、逻辑推理决策、自主学习进化等认知智能关键技术,支撑科大讯飞实现从“能听会说”到“能理解会思考”的技术跨越,并围绕教育、司法、人机交互、智能办公等领域实现科研成果的规模化应用。哈工大讯飞联合实验室成立以来在阅读理解、文本校对、自然语言理解等国际重要评测中荣获十余项冠军。
本期责任编辑:冯骁骋
哈尔滨工业大学社会计算与信息检索研究中心
理解语言,认知社会
以中文技术,助民族复兴




