Deepmind 新成果 ,让机器挑战更复杂阅读理解问题

AI掘金志出品
雷锋网旗下只报道“AI+传统”的内容频道
自然语言处理始终是实现智能、自然人机交互愿景里一块重要的技术基石。而机器阅读理解则可以被视为是自然语言处理领域皇冠上的明珠,也是目前该领域的研究焦点之一。
在这一领域,最有名的数据集是由斯坦福大学自然语言计算组发起的 SQuAD(Stanford Question Answering Dataset)和相关的文本理解挑战赛,它也被誉为“机器阅读理解界的 ImageNet ”。而最近, Deepmind 发布了一个新的阅读理解数据集 NarrativeQA,那么这个数据集有什么特点呢?

在最近一篇论文《The NarrativeQA Reading Comprehension Challenge》中,Deepmind 解释了这个推出这个数据集的初衷:
自然语言理解试图创建阅读和理解文本的模型。评估理解模型语言理解能力的一个常用策略是证明他们能回答他们所阅读的文档的问题,类似于儿童在学习阅读时如何理解阅读内容的能力。
阅读文档后,读者通常不能从记忆中重现整个文本,但经常可以回答关于文档的潜在叙述元素的问题,如突出的实体,事件,地点以及其相互关系等。因此,测试理解需要创建检查高层次的抽象的问题,而不是只在一个句子中出现一次的事实。
不幸的是,关于文档的表面问题通常可以使用浅层模式匹配或基于全局显著性的策略或猜测成功(由人和机器)回答。我们调查了现有的QA数据集,结果显示它们要么太小、要么可以通过浅的启发式算法进行解答(第2节);
另一方面,在表面文字无法直接解答、必须通过内在叙述进行推导的问题,需要形成更多在文件过程中表达的事件和关系的抽象表征。回答这些问题要求读者将信息分散在整个文件中的几个陈述中,并根据这一综合信息产生一个有说服力的答案。也就是说,他们测试得失读者理解语言的能力,而不仅仅是模式匹配。
基于此,我们提出了一个新的任务和数据集,我们称之为NarrativeQA,它将测试并奖励接近这种能力水平的智能体。
Deepmind 还对目前主要的机器阅读理解数据集进行了比较:
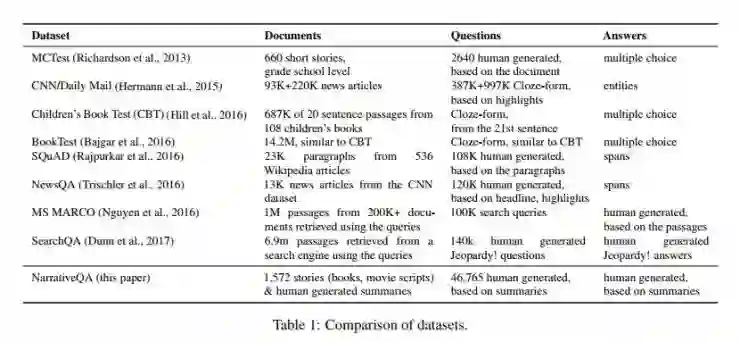
(图为目前主流机器阅读理解数据集的比较)
MCTest(2013年,Richardson等):660篇短文章,基于文章的2640个问题,回答在多个答案中进行选择,Deepmind认为,MCTest的局限性在于数量太小,因而更像一个评估测试,而不适合与一个端到端的模型训练;
而另一方面,如CNN/Daily Mail(93K+220K新闻文章,387K+997K问题)、CBT(从108本儿童读物中摘取的678K个20句左右的段落)、BookTest(14.2M个段落,类似CBT)等数据集均能够提供大量的答案-问题对,这些数据集的问题通常为完形填空(预测缺的词语),问题从摘要中进行抽象总结(CNN/Daily Mail)或者从前后一句话的上下文语境中提炼,并从一组选项中进行选择正确的答案。这类数据集的局限性在于偏差较大,部分通过指向特定类型操作的模型(如AS Reader)可能在这些数据集中表现突出,但这些模型却并不适合回答需要综合新的答案的回答。尤其在CNN/Daily Mail中,由于其上下文档均为新闻故事,通常会包含集中在单个事件的突出实体,这也进一步加大了这种偏差。
斯坦福大学Percy Liang等人推出的SQuAD(关于 SQuAD 测试参见雷锋网之前文章《专访科大讯飞:成为世界第一,只是阅读理解系统万里长征的第一步》)包含从536个维基百科词条中抽取的23K个段落。虽然SQuAD提供了大量的问题和答案,答案也并非只是某个单词或者对于某个实体的回答,但由于这些段落缺乏完整的文章包含的跨度,很多更合理的阅读理解的问题无法被提问和解答。此外,由于这些段落来自于较少的条目,这也限制了对这些数据训练中对于局部多样性和词法的效果,也限制了在SQuAD或者NewsQA等数据集中表现良好的模型回答更复杂问题的能力。
总体来说,DeepMind认为目前的阅读理解数据集均存在着一定的局限性,包括:数据集小、不自然、只需要一句话定位回答的必须信息,等等。因而 Deepmind 认为,在这些数据集上的测试可能都是一个不能真实反映机器阅读理解能力的伪命题。

(NarrativeQA主要数据)
相比之下,NarrativeQA 包含来自于书本和电影剧本的1567个完整故事,数据集划分为不重叠的训练、验证和测试三个部分,共有 46,765个问题答案对,问题由人类编写,并且多为“何时/何地/何人/为何”之类的较复杂问题。
虽然在论文和网站中并未公布数据集的下载地址,但在 Deepmind 的 Twitter 的留言中公布了在 Github 上的项目地址,详情请点击【阅读原文】
医学影像专题社开放
医学影像专题社开放,包含7期顶级AI+医学影像课程,只给AI从业者和影像科医生看的课程,往期讲师包括:
在肺部CT图像分析上有着深厚研究基础和丰富研究经验的北大王立威教授
独创的LP-NET算法在医疗影像病灶识别方面取得国际领先水平的肽积木CEO 柏文洁
率先在国内开展基于医学领域知识及深度学习的阿尔茨海默病早期诊断研究的中科院赵地老师
为医疗健康领域提供AI增强解决方案的宜远智能CEO吴博老师
讲师团队持续更新中.....
扫码入社,与数千名医生、AI从业者碰撞思维





