一言不合就想斗图?快用深度学习帮你生成表情包

AI研习社:斯坦福大学的两个学生 Abel L Peirson V 和 Meltem Tolunay 发表了自己的 CS224n 结业论文—— 用深度神经网络生成表情包(你没有看错)。论文主要内容是根据图片内容生成有关联的说明(吐槽)。可能该论文没有其他论文那么的一本正经,但在思路也算清奇,论文和代码已经公布。AI 科技评论也简单介绍一下论文内容。
摘要
Abel 和 Meltem两位同学开发了一个新型的表情包生成系统,给张图片就可以自动给图片配相应的文字(表情)。除此之外,这个系统还可以应用于用户自定义标签,让用户按图片内容分起类来更简单(表情包)。该系统先使用预训练 的Inception-v3 网络生成一个图片嵌入,然后将它传递到基于 attention 的深层 LSTM 模型中来生成最终注释,该做法灵感来自于大名鼎鼎的 SHow&Tell 模型,他们还稍微修改了一下集束搜索算法来保证配字的多样性(罪犯克星烏蠅哥+配字)。他们使用混淆度评估和人类评估来评估他们的模型,评估指标主要是两个,一是生成表情包的质量,二是是否可以以假乱真。
简介
每种文化中那些风靡的的表情包代表着一种理念或者行为风格(吐槽),它们通常旨在表达一种特定现象、主题和含义(社会人?)。
表情包无处不在,语言和风格也处在不停的变化中(过气网红)。表情包灵感来源广泛,形式也不断的演变。原本表情包只是利用文化(尤其是亚文化)主题来散播幽默的媒介。但是,表情包同样可以被用来宣传政治理想:),传播共鸣,为少数派发声。表情包是这一代人自己的交流方式,也真实的塑造了这一代人。AI 如今发展迅猛,急需新的挑战。表情包的具有高度相关性还需要强理解能力,故他们选择该项目(一本正经)。

不是谁都能简简单单就用深度学习生成表情包的
本任务只完成了上图的效果,即给图片配字。这种做法大大的简化了问题以及数据收集难度(๑乛v乛๑)。本篇论文中最主要的任务就是产生与图片高度相关的幽默配字,可以当模板表情包的那种。他们应用了一个已有的图片注释编解码系统,该系统首先是一个 CNN 图片嵌入阶段,然后再用一个 LSTM-RNN 去生成文字。他们还测试了不同的 LSTM 模型并评估它们的表现。
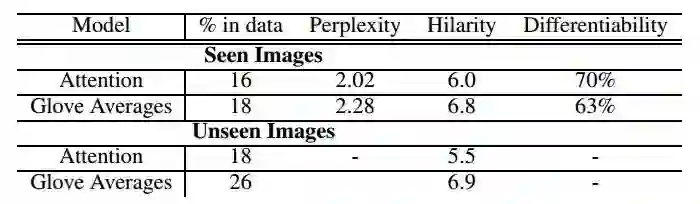
生成表情包的质量很难自动评估。他们使用混淆度作为指标来评估和调整他们的模型,混淆度与 BLEU(Bilingual Evaluation understudy)分数高度相关。他们的定量评估则是由人类测试员完成。人类测试员需要去辨别表情包是不是生成的,或者评估一下表情包的欢乐程度,毕竟表情包的灵魂就是有趣。
背景&相关工作
一、图片注释模型
《Show and tell: A neural image caption generator》(https://arxiv.org/abs/1411.4555) 这篇文章的作者介绍的图片注释模型是他们表情包生成模型的大腿。近年来对这个模型的改进中通过双向 LSTM 和注意力机制的使用得到很大的提升。但这些模型基本都没有用于「幽默注释」。StyleNet 的尝试也仅取得有限成功,但这些模型为作者的项目提供了弹药。
二、RNN 用于语言建模
RNN 及其变体模型最近在语言建模和机器翻译的 NLP 任务上取得的最好成果。其中 LSTM 尤为出色,因为它们使用「门控机制」来长时间记忆数据。两位作者使用的 LSTM 单元由于基于以下式子进行操作:
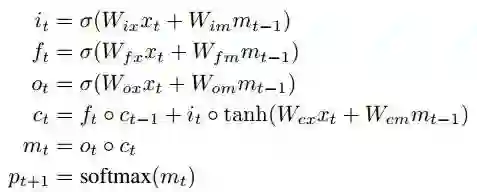
其中 f 是遗忘门,i 是输入门,o 是输出门,m 是存储器输出,W 是可训练矩阵。单词预测是通过输出词汇表中每个单词的概率分布的 softmax 层进行的。
三、预训练的 GloVe 向量
使用向量嵌入来表示单词在很多NLP任务中都是一种重要的语义相似性捕获手段。他们项目中使用的向量嵌入来自《Glove: Global vectors for word representation》(http://www.aclweb.org/anthology/D/D14/D14-1162.pdf)这篇文章。
四、RNN 的注意力机制
在语言建模、文本生成、机器翻译等连续 NLP 任务中,注意力机制解决了固定长度向量不适配长序列的问题。两位作者所建模型的一个变体中采用 了Luong et al 的注意力模型(https://arxiv.org/abs/1508.04025)。
具体方法
一、数据库
他们的数据集包含 400.000张图片,是他们自己写 Python 代码从 http://www.memegenerator.net/ 爬来的。在正式训练前,作者还对数据进行了预处理,注释中的每个字都被缩小以匹配 GloVe 格式,标点符号也被处理了一通。
二、模型变体
编码器:编码器的作用就是给解码器一个存在的理由。两位同学在该项目中做了三个模型变体(很棒),第一个忽略标签,第二个带了标签,第三个在第二个基础上还加了注意力机制。
解码器:解码器由一个单向LSTM网络组成,该网络根据上文描述的等式运行。每个LSTM单元都重用模型中的变量。而解码器存在的意义就是接编码器的锅,上述三个变体前两个可以用相同解码器解决,后一个作者也没提怎么解决。
推理和集束搜索:作者发现基于标准集束搜索的推理算法在应用中效果拔群,遂决定用该算法,为了保证生成表情包的多样性,他们在算法中还加了一个温度函数。
实验
一、训练
很稳(省略操作若干)。
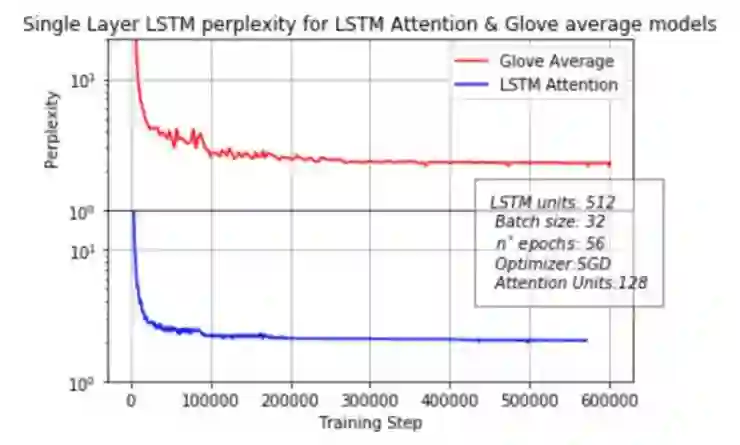
二、结果评估
还可以(呵,省略更多操作)。
我们来欣赏一些生成的表情吧







(还挺不错的哈,包括最后一张对单身狗的暴击 Orz.....)
总结
本论文介绍了如何用神经网络模型去给图片配字来生成表情包。Abel 和 Meltem两位同学还开发了多个模型变体,带标签和不带标签都有办法处理(周全),也提供了一个精调的 LSTM 模型,算是给语言建模做了一点微小的贡献(谦虚)。最后的测试结果表明生成的表情包和人为制作的表情包无法轻松区分(我信了)。
两位同学认为这个项目及其他类似语言建模任务最大的挑战就是理解各种人群和文化的梗。他们今后会再接再厉。还有最后一个问题,数据集中存在着偏见,种族歧视和性别歧视等,之后的他们之后的工作也会注意解决这个问题。
论文地址:
https://arxiv.org/abs/1806.04510
简简单单,用 LSTM 创造一个写诗机器人
▼▼▼




