点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达![]()
本文转载自:机器之心 | 论文已上传,文末附下载方式
基于 AI 目标检测系统生成的对抗样本可以使穿戴者面对摄像头「隐身」。
由美国东北大学林雪研究组,MIT-IBM Watson AI Lab 和 MIT 联合研发的这款基于对抗样本设计的 T-shirt (adversarial T-shirt),让大家对当下深度神经网络的现实安全意义引发更深入的探讨。目前该文章已经被 ECCV 2020 会议收录为 spotlight paper(焦点文章)。
![]()
论文链接:https://arxiv.org/pdf/1910.11099.pdf
在人脸识别和目标检测越来越普及的今天,如果说有一件衣服能让你在 AI 检测系统中「消失无形」,请不要感到惊讶。
![]()
熟悉 Adversarial Machine Learning(对抗性机器学习)的朋友可能不会觉得陌生,早在 2013 年由 Christian Szegedy 等人就在论文 Intriguing properties of neural networks 中首次提出了 Adversarial Examples(对抗样本)的概念。而下面这张将大熊猫变成长臂猿的示例图也多次出现在多种深度学习课程中。
很显然,人眼一般无法感知到对抗样本的存在,但是对于基于深度学习的 AI 系统而言,这些微小的扰动却是致命的。
![]()
随着科研人员对神经网络的研究,针对神经网络的 Adversarial Attack(对抗攻击)也越来越强大,然而大多数的研究还停留在数字领域层面。
Jiajun Lu 等人也在 2017 年认为:
现实世界中不需要担心对抗样本
(
NO Need to Worry about Adversarial Examples in Object Detection in Autonomous Vehicles)。
他们通过大量实验证明,单纯地
将在数字世界里生成的对抗样本通过打印再通过相机的捕捉,是无法对 AI 检测系统造成影响的。
这也证明了现实世界中的对抗样本生成是较为困难的,主要原因归于以下几点:
像素变化过于细微,无法通过打印机表现出来:
我们熟知的对抗样本,通常对图像修改的规模有一定的限制,例如限制修改像素的个数,或总体像素修改大小。而打印的过程往往无法对极小的像素值的改变做出响应,这使得很多对于对抗样本非常有用的信息通过打印机的打印损失掉了。
通过相机的捕捉会再次改变对抗样本:
这也很好理解,因为相机自身成像的原理,以及对目标捕捉能力的限制,相机无法将数字领域通过打印得到的结果再次完美地还原回数字领域。
环境和目标本身发生变化:
这一点是至关重要的。对抗样本在生成阶段可能只考虑了十分有限的环境及目标的多样性,从而该样本在现实中效果会大大降低。
近年来,Mahmood Sharif 等人(Accessorize to a crime: Real and stealthy attacks on state-of-the-art face recognition.)首次在现实世界中,通过一个精心设计的眼镜框,可以人脸检测系统对佩戴者做出错误的判断。但这项研究对佩戴者的角度和离摄像头的距离都有严格的要求。之后 Kevin Eykholt 等人(Robust Physical-World Attacks on Deep Learning Visual Classification)对 stop sign(交通停止符号)进行了攻击。通过给 stop sign 上面贴上生成的对抗样本,可以使得 stop sign 被目标检测或分类系统识别成限速 80 的标志!这也使得社会和媒体对神经网络的安全性引发了很大的探讨。
然而,这些研究都还没有触及到柔性物体的对抗样本生成。可以很容易地想象到,镜框或者 stop sign 都是典型的刚性物体,不易发生形变且这个类别本身没有很大的变化性,但是 T 恤不同,人类自身的姿态,动作都会影响它的形态,这对攻击目标检测系统的人类类别产生了很大的困扰。
最近的一些工作例如 Simen Thys 等人(Fooling automated surveillance cameras: adversarial patches to attack person detection)通过将对抗样本打印到一个纸板上挂在人身前也可以成功在特定环境下攻击目标检测器,但是却没有 T 恤上的图案显得自然且对对抗样本的形变和运动中的目标没有进行研究。
来自美国东北大学,MIT-IBM Watson AI Lab 和 MIT 联合研发的这款 Adversarial T-shirt 试图解决上述问题,并在对抗 YOLOV2 和 Faster R-CNN(两种非常普及的目标检测系统)中取得了较好的效果。通过采集实验者穿上这件 Adversarial T-shirt 进行多个场景和姿态的视频采集,在 YOLOV2 中,可以达到 57% 的攻击成功率,相较而言,YOLOV2 对没有穿 Adversarial T-shirt 的人类目标的检测成功率为 97%。
从多个已有的成功的攻击算法中得到启发,研究者们通过一种叫 EOT (Expectation over Transformation) 的算法,将可能发生在现实世界中的多种 Transformation(转换)通过模拟和求期望来拟合现实。这些转换一般包括:缩放、旋转、模糊、光线变化和随机噪声等。利用 EOT,我们可以对刚性物体进行对抗样本的生成。
但是当研究者们仅仅使用 EOT,将得到的对抗样本打印到一件 T 恤上时,仅仅只能达到 19% 的攻击成功率。这其中的主要原因就是文章上述提到的,人类的姿态会使对抗样本产生褶皱,而这种褶皱是无法通过已有的 EOT 进行模拟的。而对抗样本自身也是非常脆弱的,一旦部分信息丢失往往会导致整个样本失去效力。
基于以上观察,研究者们利用一种叫做 thin plate spline (TPS) 的变化来模拟衣服的褶皱规律。这种变化需要记录一些 anchor points(锚点)数据来拟合变化。于是研究者将一个棋盘格样式的图案打印到 T 恤上来记录棋盘格中的每个方块角的坐标信息,如下图所示:
![]()
这些锚点的坐标可以通过特定的算法自动得到无需手动标记。这样一个人工构建的 TPS 变化被加入了传统的 EOT 算法。这使得生成的对抗样本具备抗褶皱扰动的能力。
除此之外,研究者们还针对光线和摄像头可能引起的潜在变化利用一种色谱图进行的模拟,如下图所示:(a)数字领域中的色谱图;(b)该图通过打印机打印到 T 恤只会在通过相机捕捉到的结果;(c)通过映射 a-b 学到的一种色彩变换。
![]()
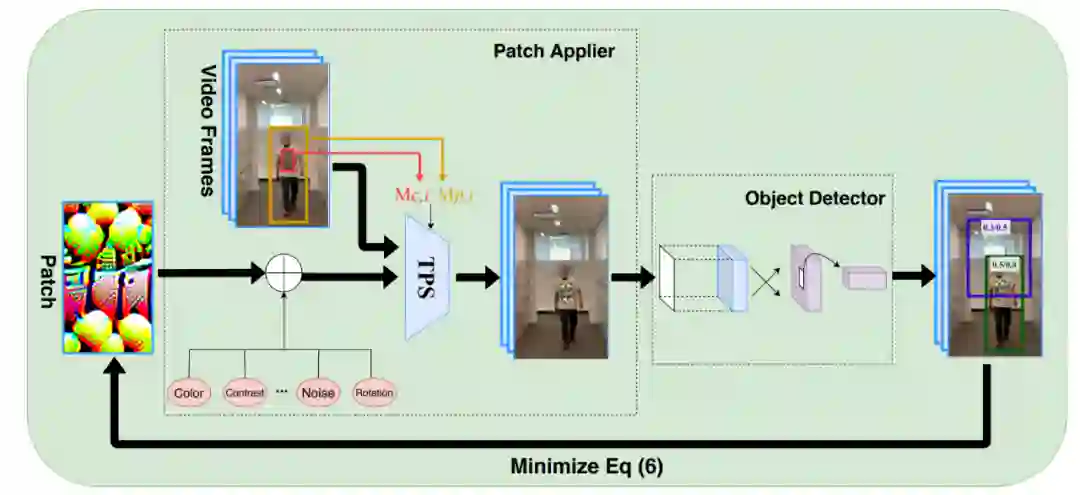
基于学习出的色彩变化系统,使得生成的对抗样本能最大限度的接近现实。最终该方法的整体框架如下:
![]()
通过增强的 EOT 和颜色转换系统,最小化 YOLOV2 的检测置信度,最终得到一个对抗样本。
除此之外,研究者们也第一次尝试了 ensemble attack (多模型攻击)。利用一张对抗样本同时攻击两个目标检测系统 YOLOV2 和 Faster R-CNN。结果显示不同于传统的加权平均的攻击方,利用鲁棒优化技术可以提高对两个目标检测系统的平均攻击成功率。
首先,研究者们在数字领域做了基础的比较试验,结果发现相较于非刚性变化—仿射变换,TPS 变化可以将攻击成功率在 YOLOV2 上从 48% 提升到 74%,在 Faster R-CNN 上由 34% 提升到 61%!这证明了对于柔性物体,加入 TPS 变化的必要性。
之后研究人员将这些对抗样本打印到白色 T 恤上,让穿戴者在不同场合以各种姿态移动并对其录制视频。最后将采集到的所有视频送入目标检测系统进行检测,统计攻击成功率。
![]()
最终,在现实世界中,该方法利用 TPS 生成的样本对抗 YOLOV2 可以达到 57% 的攻击成功率,相较而言,仅使用仿射变换只能达到 37% 攻击成功率。
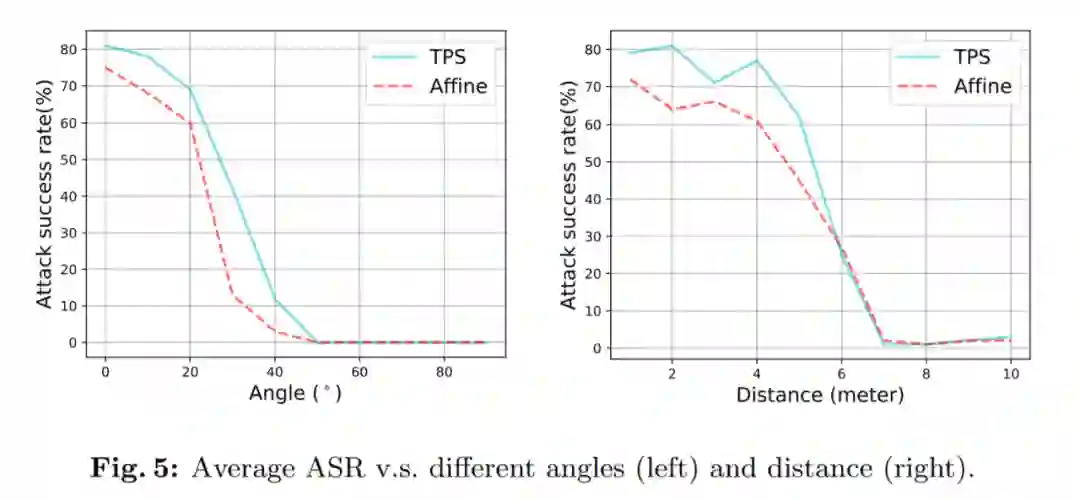
除此之外,研究者们还做了非常详尽的 ablation study:针对不同场景,距离,角度,穿戴者姿势进行研究。
![]()
![]()
结果显示,提出的方法对距离的远近和角度变化较为敏感,对不同的穿戴者和背景环境变化表现出的差异不大。
生成对抗样本其实和深度神经网络的训练是同根同源的。通过大量样本学习得到的深度神经网络几乎是必然的存在大量的对抗样本。就像无数从事 Adversarial Machine Learning(对抗性机器学习)的研究者一样,大家充分意识到了神经网络的脆弱性和易攻击性。但是这并没有阻碍我们对深度学习的进一步研究和思考,因为这种特殊且奇妙的现象来源于神经网络本身,且形成原因至今没有明确的定论。而如何构建更加鲁棒的神经网络也是目前该领域的 open issue。
该研究旨在通过指出这种特性,以及它有可能造成的社会潜在危害从而让更多的人意识到神经网络的安全问题,最终目的是帮助 AI 领域构建更加鲁棒的神经网络从而可以对这些对抗样本不再如此敏感。
许凯第:美国东北大学 ECE 系 PhD 三年级学生,主要研究领域为 Adversarial Machine Learning,研究内容已经在发表在 NeurIPS、ICML、ICCV、ECCV、CVPR、ICLR 等众多机器学习和计算机视觉会议。
下载
在CVer后台回复:对抗检测,可下载该论文
注:如果你想分享你的ECCV 2020工作,欢迎与CVer小助手联系,欢迎投稿和分享!
重磅!CVer-目标检测 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-目标检测 微信交流群,目前已汇集4100人!涵盖2D/3D目标检测、小目标检测、遥感目标检测等。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
![]()
▲长按加群
![]()
▲长按关注我们
整理不易,请给CVer点赞和在看!![]()