【干货】CVPR 2022 | 北邮ICN&CAD实验室开启人体姿态估计新篇章
导语:本文所分享的论文是由北京邮电大学电子院ICN&CAD实验室在人体姿态估计这个任务上的研究成果,团队成员主要包括北京邮电大学电子院ICN&CAD中心带头人宋梅教授,北京邮电大学电子院王小娟副教授,金磊博士,肖亚博博士以及EVOL Group负责人赵健博士等,本文将对其相关研究进行简要介绍,欢迎大家一起讨论交流。
研究团队通过研究在2D视角下各类人体姿态估计算法,包括自顶向下,自底向上和单阶段的2D人体姿态估计,发现现有方法存在的一些问题,在此基础上,又对传统的算法和方案进行了改进,并取得了一定的研究成果。同时,研究团队的最新研究进展将2D层面人体姿态估计的一些技术扩展到3D层面上,并提出了一种有效的单阶段解耦回归模型(DRM)来解决多人绝对三维姿态估计问题,该论文已被CVPR 2022收录。
01.SPCNet: Spatial Preserve and Content-aware Network for Human Pose Estimation (ECAI2020)
首先,研究团队关注于当前主流的自顶向下的2D人体姿态估计,本文主要解决复杂场景下的人体姿态估计问题。人体姿态估计作为计算机视觉中一项基本而又具有挑战性的任务,目前已经取得一定成果,但在特定的困难场景(例如,看不见的关键点、遮挡、复杂的多人场景和异常姿态)仍然没有得到很好的处理。为了缓解这些问题,本文提出了一种新的空间保存和内容感知网络(SPCNet),如图1所示,它包括两个有效的模块:扩张沙漏模块(Dilated Hourglass Module, DHM)和选择性信息模块(Selective Information Module, SIM)。
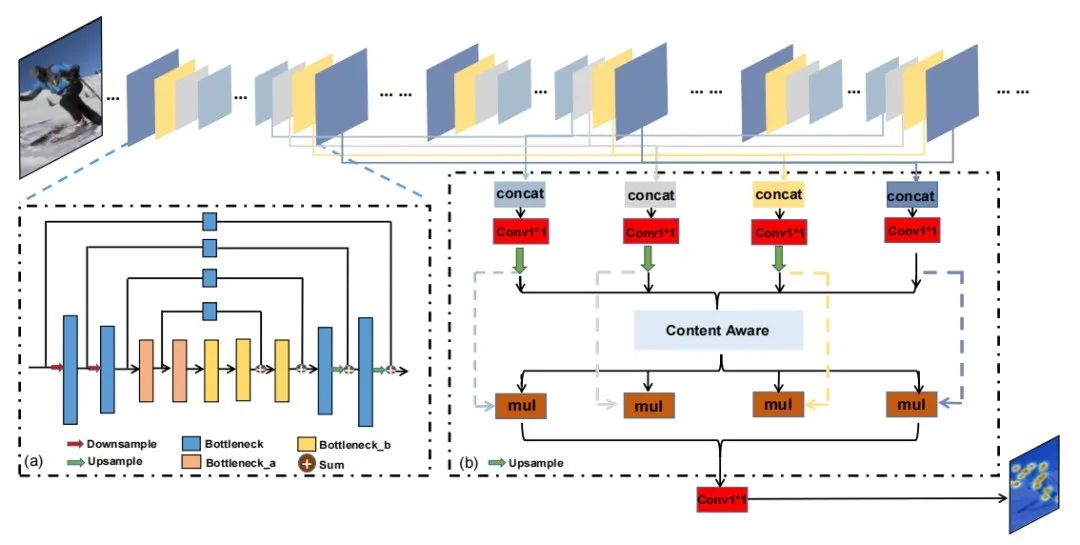
图 1 空间保持和内容感知网络(SPC-Net)
1)扩张沙漏模块
在单人姿态估计的任务中,大多数现代方法将其作为密集回归处理。编码过程中较大的下采样因子带来较大的有效感受野,有利于对遮挡、扭曲、重叠肢体的推理。但它会降低人体关键点位置的空间分辨率,而空间分辨率对于人体关键点位置的细化至关重要。因此,需要考虑全局特征和细节特征之间的权衡。本文引入了扩张沙漏模块(Dilated Hourglass Module,DHM),如图2所示,这不仅能够维持人体高分辨率结构,同时还可以获得较大的感受野。在原沙漏单元的自底向上方式下,进行4次下采样操作,将空间维数从64×64像素降至4×4像素,获得较大的接收野。最低分辨率特征图包含了对应关键点位置至关重要的高级语义信息,而降低了对关键点位置的细化提供详细信息的空间分辨率信息。
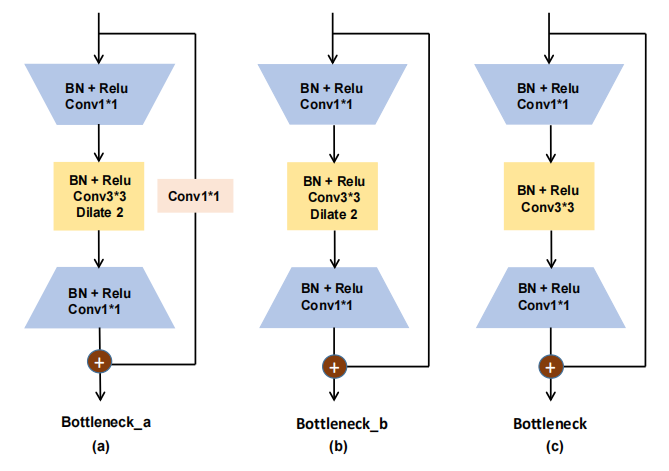
图 2 扩张沙漏模块示意图
本文提出的扩张沙漏模块DHM可以充分利用丰富的上下文信息和高空间分辨率信息。一方面,DHM只使用两次下采样操作来保持高空间维(1/4的输入分辨率),并在两次下采样操作后将空间分辨率固定为4x下采样,以缓解上述问题。另一方面,为了获得更大的接受野,研究团队引入了膨胀率为R的3×3卷积层来代替原有残差块的常规3×3卷积层。
2)选择性信息模块
高分辨率的特征图包含更多的细节,可以精确地定位关键点,但可能无法识别扭曲或重叠的关键点。低分辨率表示包含更多的能够处理困难场景(例如,看不见的关键点,扭曲的姿态)的语义上下文。一般来说,元素求和和通道级联是最常用的融合多级特性的方法。为了有效地对多尺度特征进行聚合,本文设计了选择信息模块(Selective Information Module,SIM)。SIM可以从多个层面自适应地组合空间特征,如图3所示。
本文提出的SIM有两个主要步骤: 信息收集和信息分发。通过信息收集,研究团队可以从堆叠的DHM中获取多级特征信息。通过信息分布,可以自适应地融合多级特征信息。具体来说,研究团队提出的模块通过在每个像素位置加权求和来融合多级特征,其中权值由可训练过程生成。后续实验也验证了该模块有效地融合了空间细节信息和上下文信息能够处理困难的场景(例如,看不见的关键点,扭曲的姿态)。
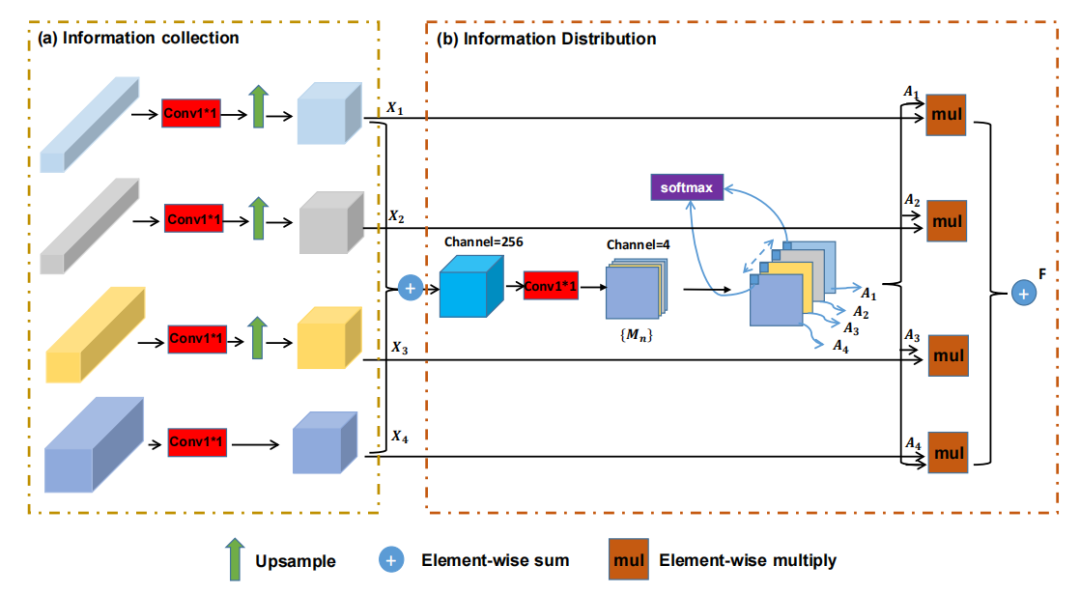
图 3 选择性信息模块示意图
研究团队的方法超过了以前的方法,并在MPII、LSP和FLIC这三个数据集上实现了最先进的性能。
02.Grouping by Center: Predicting Centripetal Offsets for the Bottom-up Human Pose Estimation (TMM)
随着技术的发展,自底向上的方法性能不断提升,研究团队发现该方法虽然效率较高,但是检测的精确度较低。针对现有问题,提出了新的自底向上人体姿态估计的分组方法——中心分组(Grouping by Center)。图4为多人姿态估计网络结构图,RGB图像被送到Backbone以提取将被传送到多路径以生成关节热图的特征。关节的热图与主干特征连接以产生远程偏移和局部中心偏移。通过Long-range Offsets和Local Center Offsets,研究团队可以获得每个关节的身体中心位置。之后,再将身体中心的位置作为分组线索,将热图检测到的关节组合起来。该方法首先检测人体关节,然后进行分组,可以预测人体姿态估计的向心偏移,将具有一致偏移结果的关键点归类为一个人,提高了分组策略的简洁性和准确性。此外,由于实例的大小差异,研究团队还设计了一个带有动态阈值的贪婪分组策略。
为了解决偏移量的尺度变化,研究团队提出了多尺度转换层和迭代细化。图5为多尺度转换结构图,其中Transform conv和Scale conv是1*1卷积。BMM是批量矩阵乘法,Deform conv是可变形卷积。普通的2D卷积只是从特征图中的固定位置提取特征。以3*3卷积为例,仅利用普通矩阵来决定采样区域。因为采样位置是固定的。那么这个矩阵在处理各种尺度和方位时效率不高。研究团队采用1*1卷积的比例conv,通过输入获得比例因子,将比例因子和矩阵相乘来修改矩阵的比例,使用Sigmoid操作来保持矩阵的符号,将防止矩阵的值在训练期间变得相似。接下来,研究团队使用变换conv(1*1卷积)通过输入特征获得变换矩阵。然后使用批量矩阵乘法(BMM)来合并变换矩阵和按比例缩放的特征矩阵。最后,有九个位置来提取特征地图中每个位置对应的特征。与由正规矩阵确定的原始采样位置相比,这九个位置是动态的,并且与输入特征相关。
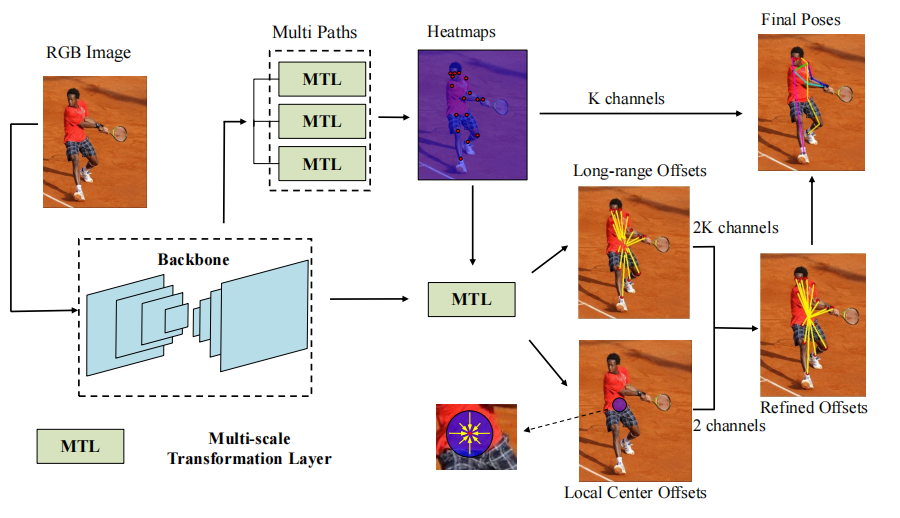
图 4 GBC多人姿态估计网络结构图
在图5中显示了MTL的详细形状参数。MTL的主要创新是使用conv缩放来控制卷积核缩放,使用conv变换来变换样本点的相对坐标。
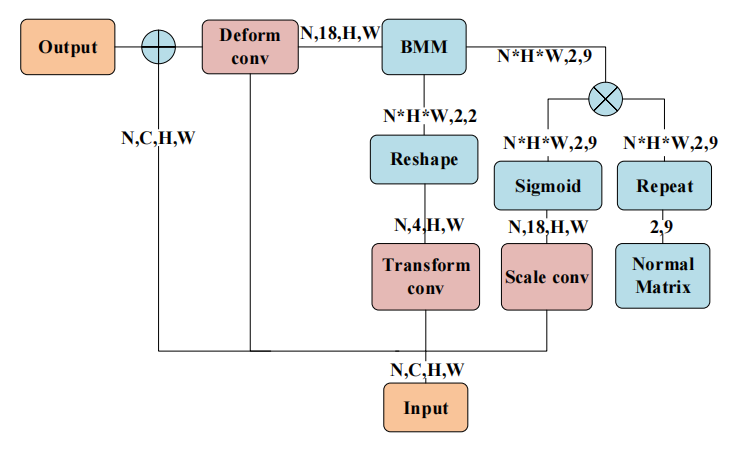
图 5 多尺度转换结构图

表 1 迭代细化结果
上表显示了以HRNetW32为骨干的COCO数据集的迭代细化结果。研究团队的框架性能得到了增强。通过综合比较,验证了研究团队的方法具有有效性和实用性,并在COCO数据集和Crowd Pose数据集上实现了当下最先进的自下而上的姿态估计性能。
03.Adaptive Pose: Human Parts as Adaptive Points (AAAI2022)
同时,研究团队针对目前的单阶段多人人体姿态估计任务展开研究。主流的多人姿态估计方案分为top-down和bottom-up两种模式,这两种模式均采用关键点热图来进行定位,但是其表征能力有限难以表达各种尺度与形变的人体。为此,研究团队提出了一种新方法,通过自适应点集来表示人体,该点集包括包括人体中心和七个与人体部位相关的点,以更细粒度的方式表示人体实例,这种新的表示方法更能捕捉各种姿态变形,并自适应地分解长距离中心到关节位移,使多人姿态估计更加紧凑高效。
研究团队利用区域感知模块(part perception module)从人体实例的中心(pixel-wise)回归七个自适应人体部位相关点(human part-related point),然后通过聚合自适应点的特征来预测中心热图,在增强中心感知分支(Enhanced Center-aware Branch)中进行感受野自适应(receptive field Adaptation)。图6是七个自适应人体部位相关点示意图,其中(a)自适应点集的可视化。白点表示人体中心,其他点是指与图(b)中相同颜色的部分对应的彩色点可视化的人体部分相关点。(b)根据自由度和变形程度划分人体部位。
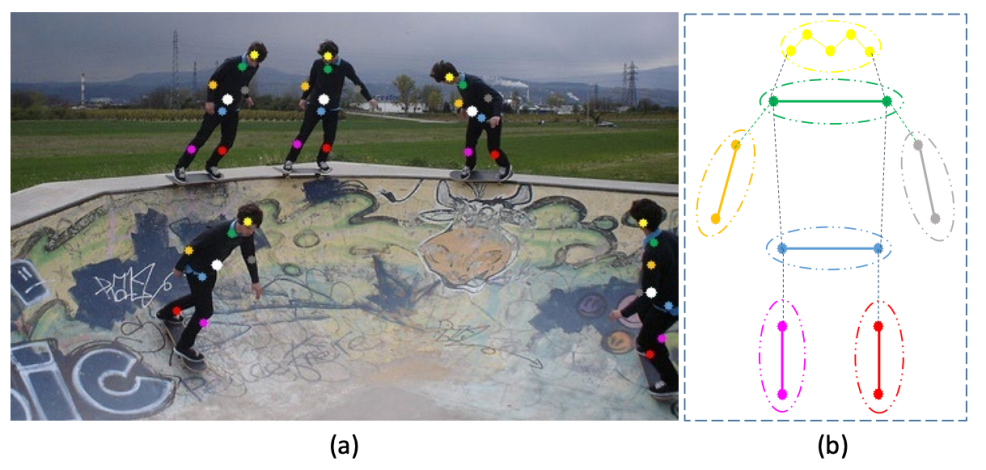
图 6 七个自适应人体部位相关点示意图
研究团队利用以每个人类实例为条件的自适应点集以细粒度的方式表示人类。基于新的人体表示方案, 提出了一个单阶段可微分的多人姿态回归网络,称为AdaptivePose,用以精确地回归多人姿态。图7中(a)部分感知模块的结构,自适应点表示七个与人体部分相关的点。(b)增强中心感知分支的结构,RP Adaptation是指感受野适应。(c)两跳回归分支示意图。(d)红色箭头是动态定位自适应人体部分相关点的一跳偏移量。(e)蓝色箭头表示用于定位人体关节的第二跳偏移。
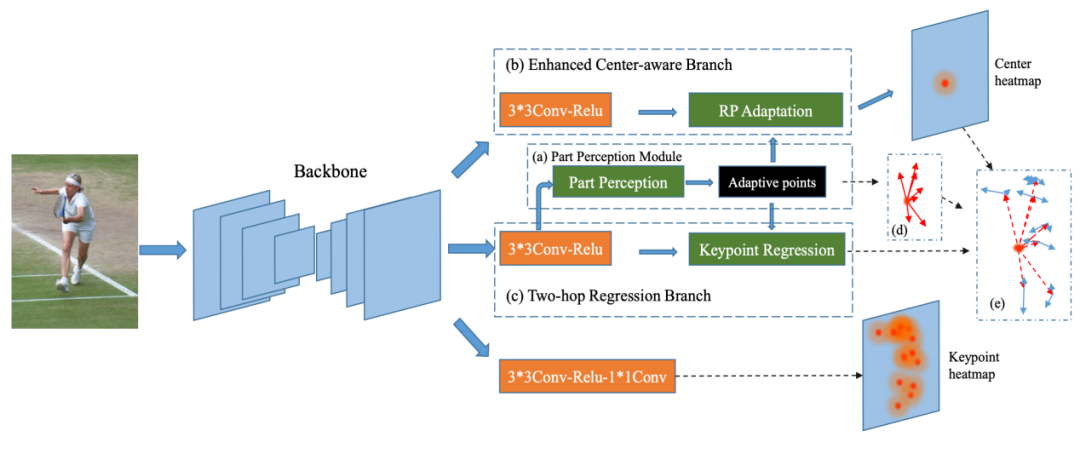
图 7 Adaptive Pose系统示意图
在推理阶段,研究团队提出的算法不需要grouping和任何refinements操作,只需要单步解码过程就可以形成多人姿态,并且在MS COCO数据集上在所有的single-stage和bottom-up方案中实现了最佳的速度精度权衡。
04.Learning Quality-aware Representation for Multi-person Pose Regression (AAAI2022)
当前的单阶段多人姿态回归方法存在两个不一致的问题:(1)人体实例的得分与姿态回归质量不是严格相关的。(2)用于预测实例得分的实例特征没有显式的编码对应的预测姿态的信息,从而不能有效的预测合理的得分来表示该姿态的回归质量。
为了解决这两个问题,研究团队首先提出了学习姿态质量感知的表示。针对第一个不一致问题,又提出了用一致性实例表示(Consistent Instance Representation)来表示实例定位的置信度。图8是研究团队提出的使用多分支结构分别回归关键点的网络示意图,(a)提出的查询编码模块包括对每个关键点的位置和语义信息进行编码以进行精确回归的关键点查询编码和将结构化姿态信息合并到实例特征中的姿态查询编码。(b)Consistent Instance Representation,利用姿态回归质量得分来表示实例定位的置信度。关键点查询的位置用黄色圆圈表示。K是关键点查询的数量。
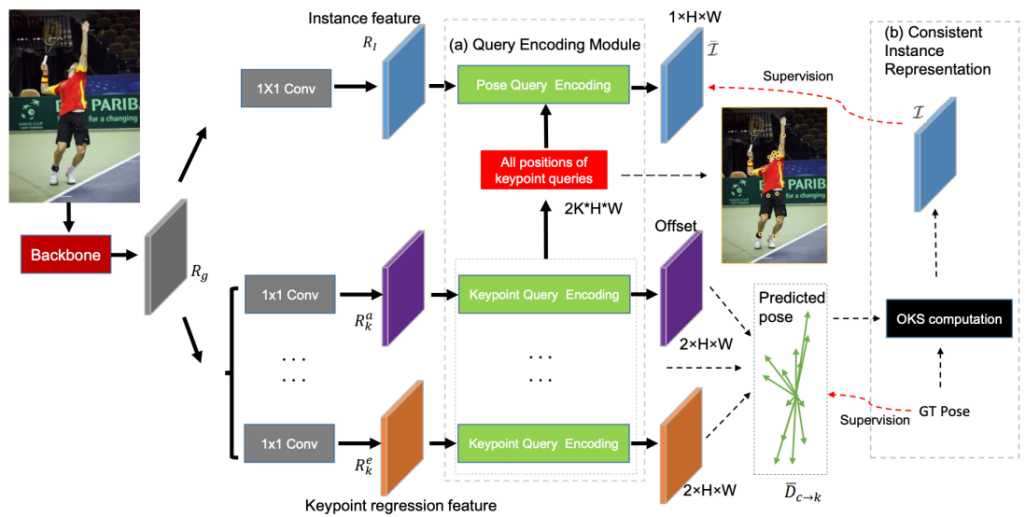
图 8 CIR流程示意图
缓解了第二个不一致问题,研究团队进一步提出了Query Encoding Module,包括了keypoint Query Encoding用于编码关键点的语义和位置信息和Pose Query Encoding显式的编码对应预测姿态到实例特征中,以更好地学习一致性实例表示。
在keypoint Query Encoding中,研究团队使用多分支结构来执行分离的关键点回归,其中每个分支都遵循相同的设计,又利用通用特征Rg通过分离的1×1卷积层生成分离的关键点表示Rk,并为每个关键点定义一个关键点查询,该查询对位置和语义信息进行编码以精确定位关键点,每个关键点查询的语义信息通过N个语义点的特征进行补充。
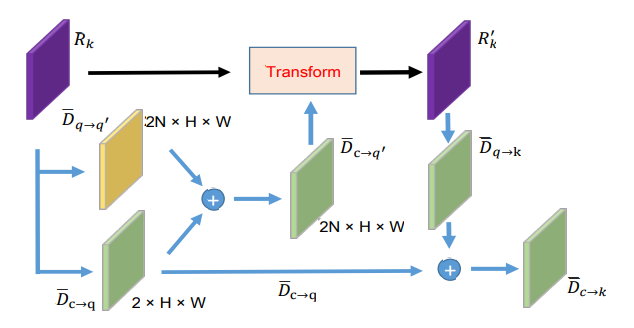
图 9 The architecture of Keypoint Query Encoding
基于关键点查询,研究团队引入姿态查询编码,将预测的结构姿态信息纳入实例特征,用于预测姿态回归质量得分。具体来说,研究团队将一般特征Rg转换为原始实例表示RI,然后在所有关键点查询的位置连接特征向量,如图10所示。Pose Query Encoding旨在将预测的结构姿态信息编码为实例特征,以预测姿态回归质量得分。
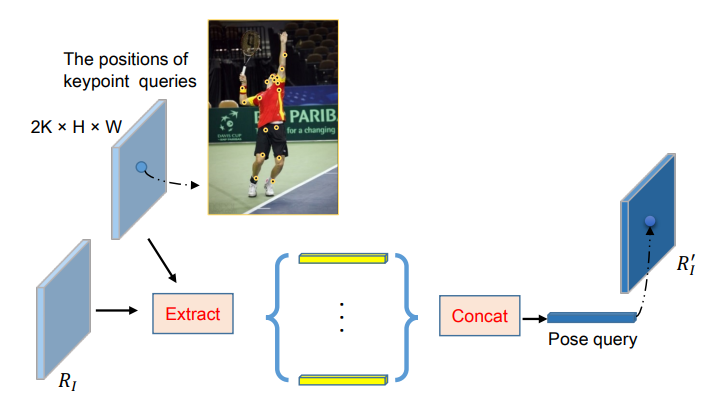
图 10 The architecture of Pose Query Encoding
研究团队的方法在MSCOCO上取得了71.7AP的性能,超过了所有single-stage regression-based甚至bottom-up的方案。
05.Single-Stage is Enough: Multi-Person Absolute 3D Pose Estimation (CVPR2022)
此外,当前3D任务越来越多研究关注,研究团队将单阶段的方案扩展到了3D人体姿态估计任务。本文主要解决当前多人三维姿态估计过程中存在的计算问题,目前的主流方法是基于自顶向下或者自底向上,导致计算冗余,增加成本。研究团队认为将这种两阶段模式简化为单阶段模式更有利于提高效率和性能,为此,提出了一种高效的单阶段解决方案——解耦回归模型(DRM),它有三个独特的创新之处:
1)3D姿态解耦表征法
DRM引入了一种新的3D姿态解耦表征法,它通过2D中心点(可见关键点的中心)和根点(表示为骨盆)分别表示图像中的2D姿态和每个3D人体实例的深度信息。
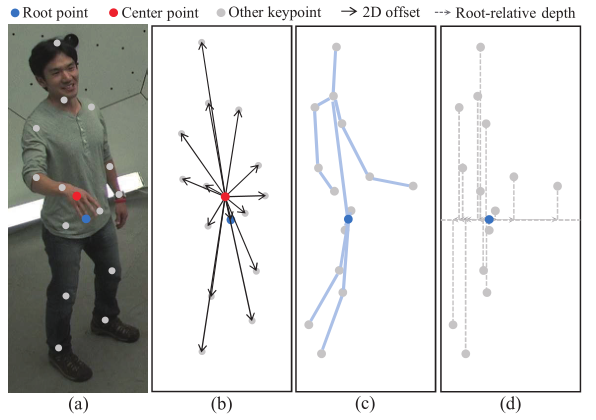
图 11 人体姿态表征方式
图11是对姿态表征的形象化和解释,其中(a)是在包含一个人实例的图像上的姿态表征。(b)是基于中心点的二维位姿表征。(c)是实例在右侧视图中的3D姿态。(d)是基于根点的相对深度表示。在研究团队的框架中,根点和中心点是不同的。
2)2D姿态引导的深度查询模块(PDQM)
从单一视角进行深度估计存在固有的模糊性。通过从整个图像中学习的特征表示直接估计绝对深度是困难的,因为它只关注根区域,而没有感知与实例规模相关的全局特征。事实上,人的绝对深度可以部分地由人的规模来表达。因此,本文认为二维位姿可以帮助提高绝对深度估计。为了预测根节点的深度,研究团队利用位于其他关键点的特性,提出了一个2D姿态引导深度查询模块(PDQM)。提取2D姿态回归分支的特征,使深度回归分支能够感知到实例的尺度信息,可以更好地学习人体深度回归的特征表示。
3)解耦绝对姿态损失(DAPL)
由于解纠缠回归方法,研究团队的网络预测的2D位姿在大多数情况下都足够准确,而估计的绝对深度性能较差。为了进一步优化绝对位姿,研究团队设计了一个解耦的绝对位姿损失(DAPL),它关注于绝对深度和相对深度。由于根相对深度是局部的、独立估计的,估计的根相对深度不能整合与实例规模相关的信息。采用DAPL感知实例规模,对根相对深度回归进行辅助监督。此外,其他关键点的相对深度从根点开始存在累积误差。DAPL通过间接监督其他关键点的绝对深度来缓解这个问题。具体来说,研究团队使用透视相机模型,利用相机坐标中估计的绝对深度、根相对深度和2D地面真实信息,重建估计的3D位姿。
图12是多人绝对三维位姿估计DRM整体模型框架。给出单目图像的输入,将单级网络分为四个流程,分别输出中心图、偏移量图、根深度图和根相对深度图。值得注意的是,在提出的PDQM中,2D偏移量回归的特性通过连接操作在根深度回归中共享。所有这些回归图可以重建所有人的绝对三维姿态。
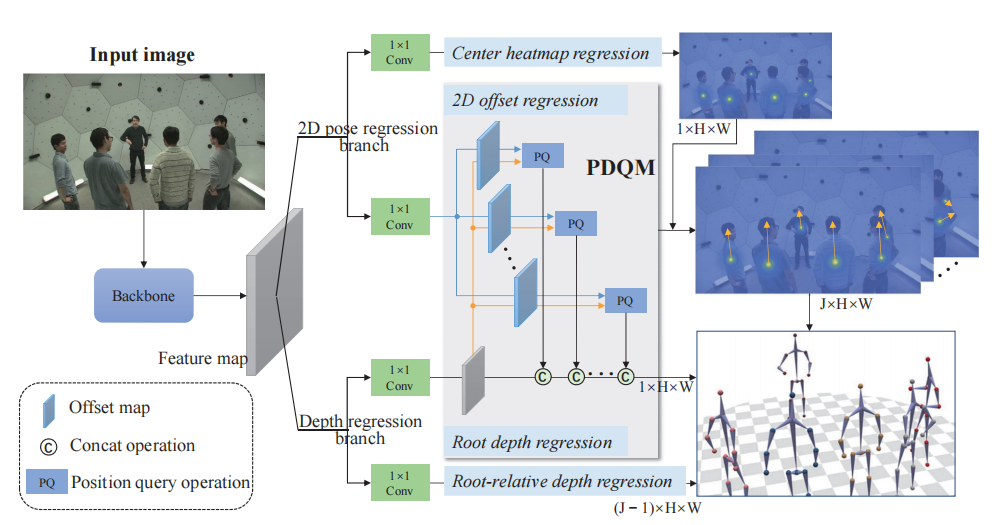
图 12 解耦回归模型(DRM)
在MuPoTS-3D和Panoptic具有挑战性基准数据集上的综合实验清楚地验证了研究团队的框架的优越性,它优于最先进的自底向上的绝对3D姿态估计方法。
人体姿态估计是计算机理解人类动作、行为必不可少的一步。针对2D人体姿态估计,本文分别优化改进了现有的一些方法,缓解了相关问题,包括复杂场景下的人体姿态估计问题、检测精确度较低问题、表征能力有限问题以及姿态回归不一致问题。针对3D人体姿态估计,本文解决了现有方法存在的计算冗余、成本高的问题,研究团队的方法提高了相关效率和性能。
在接下来的研究中,研究团队将致力于探索人体姿态估计在现实生活中更多的应用,例如用于健身、体育和舞蹈等自动教学活动,从而发挥人体姿态估计相关算法的优势。




