Apple:全局语义上下文可以改善神经语言模型吗?
编者按:从iOS 8开始,苹果就在iPhone上采用了一个全新的预测文本功能——QuickType键盘。当你在打字的时候,系统会根据你的书写风格,提示接下来可能会键入的字词或短语供你选择,类似中文输入法中的智能建议。
这一功能基于其背后强大的自然语言处理(NLP)模型,而在过去几年中,这种词向量模型也是新闻、搜索和地图等其他应用程序的核心。在这篇文章中,我们将介绍苹果研究人员近期的一项新探索:是否可以利用全局语义上下文改进QuickType键盘的单词预测?
简介
You shall know a word by the company it keeps.(现代语言学名句:观其伴而知其意。即通过分析大型语言语料库中词汇共现的模式,我们可以得出词语的语义表征)
现如今,训练词嵌入模型的大多数方法都围绕句子中给定单词的上下文,以出现在中心词前后的几个单词(比如5个)为观察“窗口”,从中挖掘信息。以美国《独立宣言》中出现的代词“self-evident”为例,它的左侧是“hold these truths to be”,右侧是“that all men are created”。
本文将在这类方法的基础上做进一步扩展,探索模型是否能捕获文档的整个语义结构,简而言之,在新模型中,“self-evident”将可以把整本《独立宣言》作为自己的上下文。那么,这种全局语义上下文能否提高语言模型的性能呢?要解决这个问题,我们先看看现在的词嵌入用法。
词嵌入
词嵌入(Word Embeddings)是NLP中的一个常见操作,现在,以无监督方式训练的连续空间词嵌入已经被证实可用于各种NLP任务,比如信息检索、文本分类、问答和序列语言建模等。其中最基础的一种词嵌入是1-of-N Encoding,即假设存在一个大小为N的基础单词集,每个单词都由一个N维系数向量表示(在单词索引处为1,在其他地方为0)。
但这种方法有两个缺陷,一是它的正交性会弱化相似单词之间关系,二是编码结果容易过长。因此我们也已经有了更复杂的嵌入——将单词映射到低维连续向量空间中的密集向量中,这种映射不仅能降低维度,还有利于捕获关于单词的语义、句法和语用信息。
有了词向量,我们就能通过计算向量之间的距离判断两个单词的相似程度。
比较常见的降维词嵌入类型有两种:
从单词所在文本的上下文中导出表示(前L个单词和后L个单词,L一般是个较小的整数)
利用围绕单词的全局上下文的表示(单词所在的整个文本)
其中,利用文本上下文的方法包括:
用于预测的神经网络架构,如连续词袋模型和skip-gram模型
序列语言模型中的投影层(projection layer)
自编码器的Bottleneck表示
利用全局上下文的方法包括:
全局矩阵分解方法,如潜在语义映射(LSM),它计算word-document共现次数
Log-Liner Model,如GloVe,它计算word-word共现次数
从理想的角度看,像LSM这种计算全局共现的方法其实是最接近真正的语义嵌入的,因为它们捕获的是整个文本传达的语义概念的统计信息。相比之下,基于预测的神经网络只是把语义关系封装到以目标单词为中心的局部文本中,不够全面。因此,当涉及全局语义信息时,由这种方法产生的嵌入往往存在局限。
但是,尽管存在这种局限,现在越来越多的研究人员还是投向神经网络,尤其是广受欢迎的连续词袋模型和skip-gram模型。因为它们能解决“国王对于女王就像男人对于女人”这类类比,而LSM经常失败。对此,一种普遍看法是基于LSM的方法会使向量空间的各个维度不够精确,因此只能产生次优的空间结构。
这个认识引起了苹果研究人员的极大兴趣,因为现用QuickType键盘是基于LSM设计的,在他们最新的博客中,他们就是否可以通过使用不同类型的神经网络架构来实现更强大的语义嵌入进行了探讨。
神经架构
谈及生成词嵌入,最著名的框架之一是word2vec,但研究人员在文章中采用的是一种能提供全局语义嵌入的特殊RNN——bi-LSTM。它允许模型访问先前、当前和未来的输入信息,把握全局上下文。
为了让模型能输入整个完整文档,他们重新设计了这个架构,如下图所示,模型的输出能提供与该文档相关联的语义类别这意味着生成的词嵌入捕获的是输入的整个语义结构,而不仅是局部上下文。
这个架构主要解决了两个障碍。其一是对目标单词上下文的单词数限制,它原则上可以容纳无限长度的上下文,这样就不仅可以处理句子,还可以处理整个段落,甚至是完整的文档。
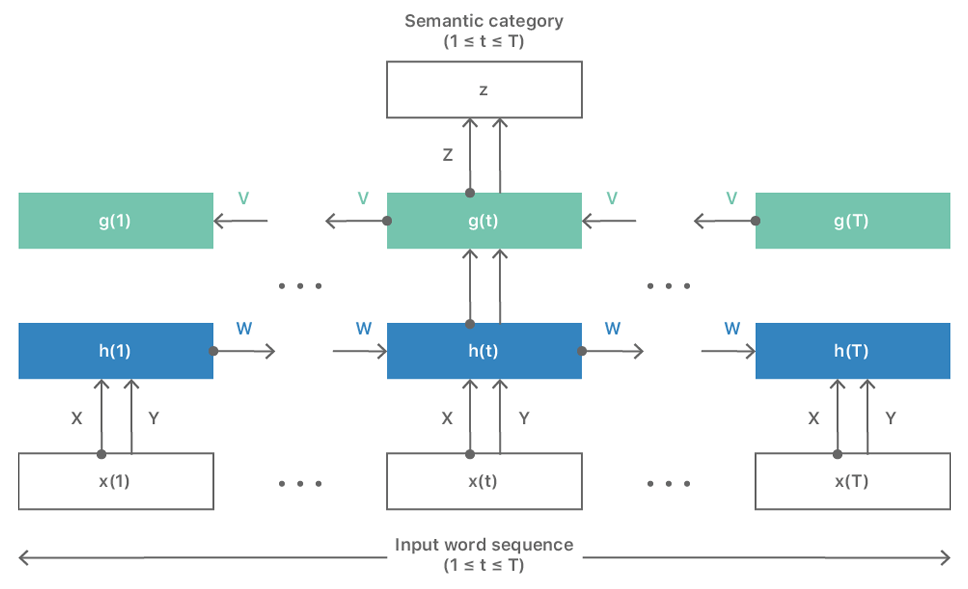
图一 能捕获全局语义结构的RNN
其二涉及预测目标本身。到目前为止,神经网络这种解决方案都基于局部上下文信息,无法充分反映全局语义信息,但是上图已经是一个能输入完整文本的神经网络了。为了简化语义标签的生成,研究人员发现派生合适的聚类类别是有帮助的,例如,他们可以用LSM获得初始word-document嵌入。
设当前存在一个文本块(可以是句子,也可以是段落、文档),它由T个单词x(t)构成(1≤t≤T),且存在一个全局关联的语义类别z。我们把它输入修改过的bi-LSTM。
用1-of-N encoding对输入文本中的单词x(t)编码,把x(t)转成N维稀疏向量。此时,x(t)左侧的上下文向量h(t − 1)维数为H,它包含前一个时间步的隐藏层中输出值信息的内部表示;x(t)右侧的上下文向量g(t + 1)维数也是H,它包含下一个时间步的隐藏层中的右侧上下文输出值信息。网络在当前时间步计算隐藏节点的输出值,如下所示:
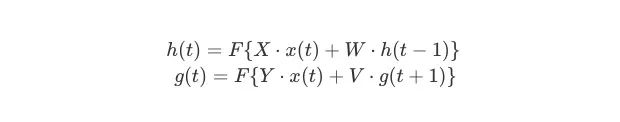
其中,
F{·}表示激活函数,如sigmoid、tanh、ReLU
s(t)表示网络状态,这是左右上下文隐藏节点的串联:s(t) = [g(t) h(t)],维数为2H。我们可以把网络状态看作是2H向量空间中,单词x(t)的连续空间表示
网络的输出是与输入文本相关联的语义类别。在每个时间步,对应于当前单词的输出标签z再被1-of-K encoding:
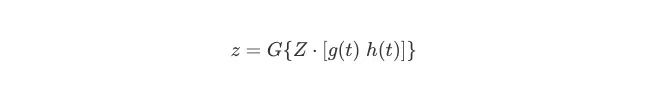
其中,G {·}表示softmax激活函数。
当我们训练网络时,我们假设有一组语义类别注释可用。如前所述,这些注释可能来自使用LSM获得的初始word-document嵌入。为了避免出现梯度消失,这个架构把隐藏节点设计成了LSTM和GRU里的形式,我们可以根据需要将图一中的单个隐藏层扩展到任意复杂、任意深度的网络。
神经语言建模
在实验中,研究人员使用的是之前训练QuickType时所用的语料库的子集,如下表所示,他们测试了三种不同嵌入模型在测试集上的困惑度表现,其中“1-of-N”表示标准稀疏嵌入,“word2vec”是标准word2vec嵌入,“bi-LSTM”是他们改进后的方法。

可以发现,“bi-LSTM”使用的训练数据是最少的,但它的性能却和比他多用了6倍训练数据的“word2vec”差不多,而“1-of-N”模型如果要达到同样的困惑度,它使用的训练数据得是“bi-LSTM”的5000倍以上。
因此,这种能捕获全局语义结构的方法非常适合数据量有限的公司、实验室。
结论
相比现有方法,将全局语义信息纳入神经语言模型具有明显的潜在优势,它也是NLP研究的一个趋势。但是,在实验过程中,研究人员也发现这种方法确实还存在限制,在段落数据上训练词嵌入和在句子数据上训练语言模型时,其中还存在一个长度不匹配的问题。
对此,研究人员提出的方案是修改语言模型训练中使用的客观标准,以便人们能在同一段落数据上同时训练嵌入和语言模型。总之,使用bi-LSTM RNN训练全局语义词嵌入确实可以提高神经语言建模的准确性,它还可以大大降低对训练所需的数据量的要求。
原文地址:machinelearning.apple.com/2018/09/27/can-global-semantic-context-improve-neural-language-models.html




