ICLR 2020 | 多模态下使用图片信息显著增强机器翻译效果

论文标题:
Neural Machine Translation with Universal Visual Representation
论文作者:
Zhuosheng Zhang, Kehai Chen, Rui Wang, Masao Utiyama, Eiichiro Sumita, Zuchao Li, Hai Zhao
论文链接:
https://openreview.net/forum?id=Byl8hhNYPS
收录情况:
ICLR 2020 (Spotlight)
代码链接:
https://github.com/cooelf/UVR-NMT
长期以来,机器翻译都只涉及到文本之间的转换,但实际上,人的感知功能可以是“多模态”的。
本文提出一种通用的视觉表征,将图片信息融合到机器翻译模型中。
使用这种视觉知识融合方法,不需要额外的双语-图片标注数据,模型就能够在多个数据集上取得显著的效果提升。
多模态与机器翻译
机器翻译是两种语言间的转换,比如“A dog is playing in the snow”翻译为中文就是“小狗在雪地里玩耍”。
但人类理解世界不只是用文字,还有视觉、听觉等感知能力;并且翻译的过程需要保持“语义”不变。比如下面的图:

讲中文的人会说“小狗在雪地里玩耍”,而讲英文的人会说“A dog is playing in the snow”。也就是说,人们对客观世界的本质认知是相同的,只是“方法”不同,体现在语言上,就是语法上的差异。
为此,我们可以假设在机器翻译模型中,融入这种“客观的世界知识”,比如把图片信息加入,以此期望增强翻译能力。同时考虑文本和图片,这就是一种多模态。
然而,过去的翻译-图片研究大都需要大量的双语-图片标注数据,这在数据上成为一个研究的瓶颈。本文针对这种情况,提出“通用的视觉表示”,仅用单语-图片标注数据,就能显著提高机器翻译的效果。
本文的方法在数据集EN-RO,EN-DE,EN-FR上均有约一个BLEU值的提高,这说明了本方法的有效性。
具体来说,本文贡献如下:
提出一种通用的视觉表示方法,无需双语-图片标注语料;
该方法可以在只有文本的数据集上使用;
实验证明了该方法效果提升的一致性。
在阅读完本文之后,读者可以思考下述问题:
如果要翻译单语-图片数据集
中没有的语言,可以怎么做?
在融合步骤,是否可以有其他的方法进行融合?
你认为本文这种方法从逻辑上是否真的有效?为什么?
通用视觉表示
本节来介绍本文的方法。
首先我们有一个单语-图片数据集


这个描述的句子为

然后,对




这样一来,每个图片

那么,现在输入一个句子,我们就可以按照同样的步骤:
1.去除停用词;
2.计算每个词的TF-IDF;
3.取前
4.在查询表中找到所有对应的图片;
5.按照出现次数的多少排序,取出前

现在,这个图片集合

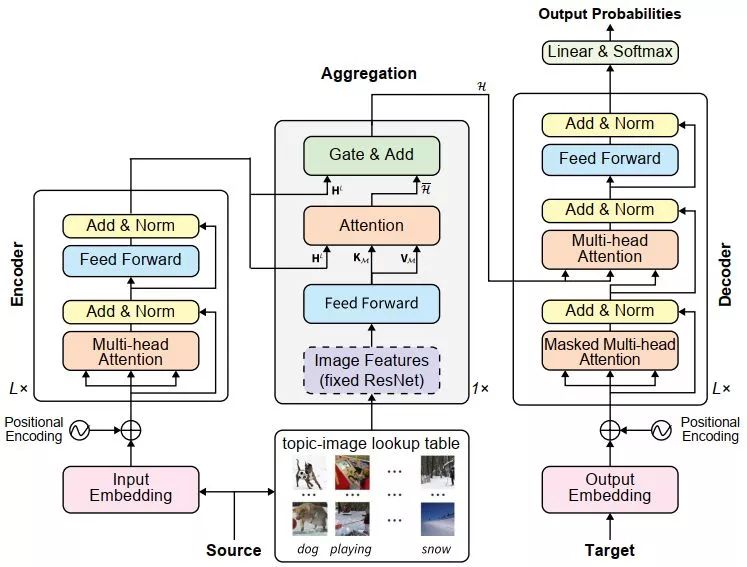
在机器翻译中融合图片信息
为了把图片融合进去,我们首先用一个预训练的ResNet提取图片集

这里,


在Decoder端,直接把
实验
我们在三个数据集上进行实验:WMT16 En-RO, WMT14 EN-DE和WMT14 EN-FR。这三个数据集大小从小到大增加,从而在不同大小的数据集上都能验证该方法。
下表是在这三个数据集上的结果,++表示显著更优。
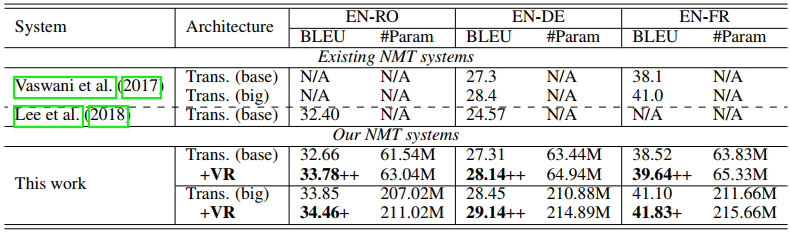
可以看到,和基线模型(Trans.(base/big))相比,本文的方法(+VR)在三个数据集上都能得到显著的提升,平均提升约一个BLEU值。同时,只引入了很少的参数量,这就不会使训练时间几乎不会增加。
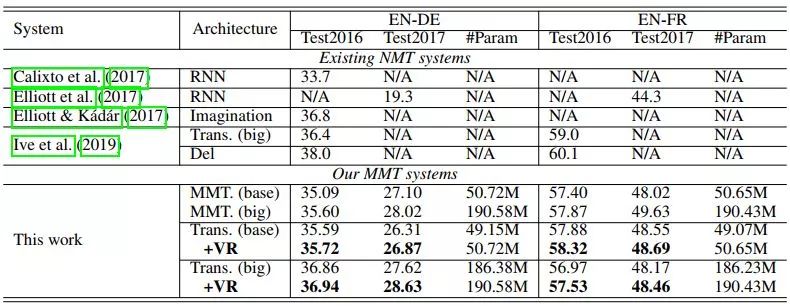
下表是在数据集Multi30K上的结果,这是一个多模态数据集。可以看到,即使在多模态设置下,本文方法依旧能够取得显著结果。
最后,我们来看看每个句子对应的图片集
下图分别是两个因素的影响结果。从图片数量来看,并不是越多的图片数量越好,也不是越少越好,而是在
参数
而且,手动控制它都没有模型自动学习好,这也说明模型对不同的输入句子,需要的视觉信息也是不同的。

小结
本文提出了一种简单、有效的多模态视觉知识融合方法——首先构建从主题词到图片的查询表,然后对输入句子找到相关的图片,然后使用ResNet提取图片信息融入到机器翻译模型中。
使用这种方法,可以避免对大规模双语-图片数据的依赖。实验结果也表明,这种方法可以一致地提高翻译效果。
思考题讨论
如果要翻译单语-图片数据集
中没有的语言,可以怎么做?
比如
没有日语,我们可以用一个日语的image caption模型去自动标注每个图片的描述。
或者可以用X-日语的机器翻译得到图片翻译后的描述;或者直接用一个现有的词典,把图片的主题词直接翻译成日语。其他方法亦可。
在融合步骤,是否可以有其他的方法进行融合?
另外一个简单的方法是,把ResNet得到的图片表示和句子一起,送入Encoder,再像往常一样解码。
你认为本文这种方法从逻辑上是否真的有效?为什么?
见仁见智,笔者倾向于有效,但是作用不大,因为只从模型的角度难以验证图片和文本之间语义的相关性,至于效果的提升,有可能是ResNet和Aggregate的共同结果。
笔者认为,可以考虑加一个图片预测描述的任务,和翻译一起学习;再将ResNet替换为普通的CNN进行实验。
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。