【数据科学家】数学是什么?麻省理工牛人解说数学体系
数学是什么?







麻省理工牛人解说数学体系
麻省理工牛人眼中的
数学体系

一、为什么要深入数学的世界
作为计算机的学生,我没有任何企图要成为一个数学家。我学习数学的目的,是要想爬上巨人的肩膀,希望站在更高的高度,能把我自己研究的东西看得更深广一些。说起来,我在刚来这个学校的时候,并没有预料到我将会有一个深入数学的旅程。我的导师最初希望我去做的题目,是对appearance和motion建立一个unified的model。这个题目在当今Computer Vision中百花齐放的世界中并没有任何特别的地方。事实上,使用各种Graphical Model把各种东西联合在一起framework,在近年的论文中并不少见。
我不否认现在广泛流行的Graphical Model是对复杂现象建模的有力工具,但是,我认为它不是panacea,并不能取代对于所研究的问题的深入的钻研。如果统计学习包治百病,那么很多“下游”的学科也就没有存在的必要了。事实上,开始的时候,我也是和Vision中很多人一样,想着去做一个Graphical Model——我的导师指出,这样的做法只是重复一些标准的流程,并没有很大的价值。经过很长时间的反复,另外一个路径慢慢被确立下来——我们相信,一个图像是通过大量“原子”的某种空间分布构成的,原子群的运动形成了动态的可视过程。微观意义下的单个原子运动,和宏观意义下的整体分布的变换存在着深刻的联系——这需要我们去发掘。
在深入探索这个题目的过程中,遇到了很多很多的问题,如何描述一个一般的运动过程,如何建立一个稳定并且广泛适用的原子表达,如何刻画微观运动和宏观分布变换的联系,还有很多。在这个过程中,我发现了两个事情:
我原有的数学基础已经远远不能适应我对这些问题的深入研究。
在数学中,有很多思想和工具,是非常适合解决这些问题的,只是没有被很多的应用科学的研究者重视。
于是,我决心开始深入数学这个浩瀚大海,希望在我再次走出来的时候,我已经有了更强大的武器去面对这些问题的挑战。我的游历并没有结束,我的视野相比于这个博大精深的世界的依旧显得非常狭窄。在这里,我只是说说,在我的眼中,数学如何一步步从初级向高级发展,更高级别的数学对于具体应用究竟有何好处。
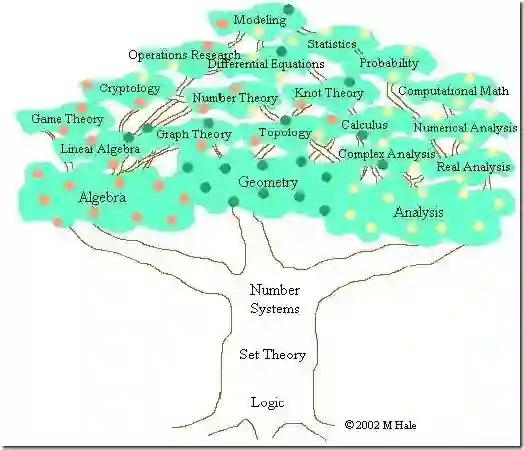
二、集合论:现代数学的共同基础
现代数学有数不清的分支,但是,它们都有一个共同的基础——集合论——因为它,数学这个庞大的家族有个共同的语言。集合论中有一些最基本的概念:集合(set),关系(relation),函数(function),等价 (equivalence),是在其它数学分支的语言中几乎必然存在的。对于这些简单概念的理解,是进一步学些别的数学的基础。我相信,理工科大学生对于这些都不会陌生。
不过,有一个很重要的东西就不见得那么家喻户晓了——那就是“选择公理” (Axiom of Choice)。这个公理的意思是“任意的一群非空集合,一定可以从每个集合中各拿出一个元素。”——似乎是显然得不能再显然的命题。不过,这个貌似平常的公理却能演绎出一些比较奇怪的结论,比如巴拿赫-塔斯基分球定理——“一个球,能分成五个部分,对它们进行一系列刚性变换(平移旋转)后,能组合成两个一样大小的球”。
正因为这些完全有悖常识的结论,导致数学界曾经在相当长时间里对于是否接受它有着激烈争论。现在,主流数学家对于它应该是基本接受的,因为很多数学分支的重要定理都依赖于它。在我们后面要回说到的学科里面,下面的定理依赖于选择公理:
拓扑学:Baire Category Theorem
实分析(测度理论):Lebesgue 不可测集的存在性
泛函分析四个主要定理:Hahn-Banach Extension Theorem, Banach-Steinhaus Theorem (Uniform boundedness principle), Open Mapping Theorem, Closed Graph Theorem
在集合论的基础上,现代数学有两大家族:分析(Analysis)和代数(Algebra)。至于其它的,比如几何和概率论,在古典数学时代,它们是和代数并列的,但是它们的现代版本则基本是建立在分析或者代数的基础上,因此从现代意义说,它们和分析与代数并不是平行的关系。
三、分析:在极限基础上建立的宏伟大厦
3.1微积分:分析的古典时代--从牛顿到柯西
先说说分析(Analysis)吧,它是从微积分(Caculus)发展起来的——这也是有些微积分教材名字叫“数学分析”的原因。不过,分析的范畴远不只是这些,我们在大学一年级学习的微积分只能算是对古典分析的入门。分析研究的对象很多,包括导数(derivatives),积分(integral),微分方程(differential equation),还有级数(infinite series)——这些基本的概念,在初等的微积分里面都有介绍。如果说有一个思想贯穿其中,那就是极限——这是整个分析(不仅仅是微积分)的灵魂。
一个很多人都听说过的故事,就是牛顿(Newton)和莱布尼茨 (Leibniz)关于微积分发明权的争论。事实上,在他们的时代,很多微积分的工具开始运用在科学和工程之中,但是,微积分的基础并没有真正建立。
那个长时间一直解释不清楚的“无穷小量”的幽灵,困扰了数学界一百多年的时间——这就是“第二次数学危机”。直到柯西用极限的观点重新建立了微积分的基本概念,这门学科才开始有了一个比较坚实的基础。直到今天,整个分析的大厦还是建立在极限的基石之上。
柯西(Cauchy)为分析的发展提供了一种严密的语言,但是他并没有解决微积分的全部问题。在19世纪的时候,分析的世界仍然有着一些挥之不去的乌云。而其中最重要的一个没有解决的是“函数是否可积的问题”。
我们在现在的微积分课本中学到的那种通过“无限分割区间,取矩阵面积和的极限”的积分,是大约在1850年由黎曼(Riemann)提出的,叫做黎曼积分。但是,什么函数存在黎曼积分呢(黎曼可积)?数学家们很早就证明了,定义在闭区间内的连续函数是黎曼可积的。可是,这样的结果并不令人满意,工程师们需要对分段连续函数的函数积分。
3.2实分析:在实数理论和测度理论上建立起现代分析
在19世纪中后期,不连续函数的可积性问题一直是分析的重要课题。对于定义在闭区间上的黎曼积分的研究发现,可积性的关键在于“不连续的点足够少”。只有有限处不连续的函数是可积的,可是很多有数学家们构造出很多在无限处不连续的可积函数。显然,在衡量点集大小的时候,有限和无限并不是一种合适的标准。
在探讨“点集大小”这个问题的过程中,数学家发现实数轴——这个他们曾经以为已经充分理解的东西——有着许多他们没有想到的特性。在极限思想的支持下,实数理论在这个时候被建立起来,它的标志是对实数完备性进行刻画的几条等价的定理(确界定理,区间套定理,柯西收敛定理,Bolzano-Weierstrass Theorem和Heine-Borel Theorem等等)——这些定理明确表达出实数和有理数的根本区别:完备性(很不严格的说,就是对极限运算封闭)。
随着对实数认识的深入,如何测量“点集大小”的问题也取得了突破,勒贝格创造性地把关于集合的代数,和Outer content(就是“外测度”的一个雏形)的概念结合起来,建立了测度理(Measure Theory),并且进一步建立了以测度为基础的积分——勒贝(Lebesgue Integral)。在这个新的积分概念的支持下,可积性问题变得一目了然。
上面说到的实数理论,测度理论和勒贝格积分,构成了我们现在称为实分析 (Real Analysis)的数学分支,有些书也叫实变函数论。对于应用科学来说,实分析似乎没有古典微积分那么“实用”——很难直接基于它得到什么算法。而且, 它要解决的某些“难题”——比如处处不连续的函数,或者处处连续而处处不可微的函数——在工程师的眼中,并不现实。
但是,我认为,它并不是一种纯数学概念游戏,它的现实意义在于为许多现代的应用数学分支提供坚实的基础。下面,我仅仅列举几条它的用处:
黎曼可积的函数空间不是完备的,但是勒贝格可积的函数空间是完备的。简单的说,一个黎曼可积的函数列收敛到的那个函数不一定是黎曼可积的,但是勒贝格可积的函数列必定收敛到一个勒贝格可积的函数。在泛函分析,还有逼近理论中,经 常需要讨论“函数的极限”,或者“函数的级数”,如果用黎曼积分的概念,这种讨论几乎不可想像。我们有时看一些paper中提到L^p函数空间,就是基于勒贝格积分。
勒贝格积分是傅立叶变换(这东西在工程中到处都是)的基础。很多关于信号处理的初等教材,可能绕过了勒贝格积分,直接讲点面对实用的东西而不谈它的数学基础,但是,对于深层次的研究问题——特别是希望在理论中能做一些工作——这并不是总能绕过去。
在下面,我们还会看到,测度理论是现代概率论的基础。
3.2.1现在概率论:在现代分析基础上再生
自从Kolmogorov在上世纪30年代把测度引入概率论以来,测度理论就成为现代概率论的基础。在这里,概率定义为测度,随机变量定义为可测函数,条件随机变量定义为可测函数在某个函数空间的投影,均值则是可测函数对于概率测度的积分。值得注意的是,很多的现代观点,开始以泛函分析的思路看待概率论的基础概念,随机变量构成了一个向量空间,而带符号概率测度则构成了它的对偶空间,其中一方施加于对方就形成均值。角度虽然不一样,不过这两种方式殊途同 归,形成的基础是等价的。
在现代概率论的基础上,许多传统的分支得到了极大丰富,最有代表性的包括鞅论 (Martingale)——由研究赌博引发的理论,现在主要用于金融(这里可以看出赌博和金融的理论联系,:-P),布朗运动(Brownian Motion)——连续随机过程的基础,以及在此基础上建立的随机分析(Stochastic Calculus),包括随机积分(对随机过程的路径进行积分,其中比较有代表性的叫伊藤积分(Ito Integral)),和随机微分方程。对于连续几何运用建立概率模型以及对分布的变换的研究离不开这些方面的知识。
3.3拓扑学:分析从实数轴推广到一般空间--现代分析的抽象基础
随着实数理论的建立,大家开始把极限和连续推广到更一般的地方的分析。事实上,很多基于实数的概念和定理并不是实数特有的。很多特性可以抽象出来,推广到更一般的空间里面。对于实数轴的推广,促成了点集拓扑学(Point- set Topology)的建立。很多原来只存在于实数中的概念,被提取出来,进行一般性的讨论。在拓扑学里面,有4个C构成了它的核心:
Closed set 闭集
在现代的拓扑学的公理化体系中,开集和闭集是最基本的概念。一切从此引申。这两个概念是开区间和闭区间的推广,它们的根本地位,并不是一开始就被认识到的。经过相当长的时间,人们才认识到:开集的概念是连续性的基础,而闭集对极限运算封闭——而极限正是分析的根基。
Continuous function 连续函数
连续函数在微积分里面有个用epsilon-delta语言给出的定义,在拓扑学中它的定义是“开集的原像是开集的函数”。第二个定义和第一个是等价的,只是用更抽象的语言进行了改写。我个人认为,它的第三个(等价)定义才从根本上揭示连续函数的本质——“连续函数是保持极限运算的函数” ——比如y是数列x1, x2, x3, … 的极限, 那么如果 f 是连续函数,那么 f(y) 就是 f(x1), f(x2), f(x3), …的极限。
连续函数的重要性,可以从别的分支学科中进行类比。比如群论中,基础的运算是“乘法”,对于群,最重要的映射叫“同态映射”——保持“乘法”的映射。在分析中,基础运算是“极限”,因此连续函数在分析中的地位,和同态映射在代数中的地位是相当的。
Connected set 连通集
比它略为窄一点的概念叫(Path connected),就是集合中任意两点都存在连续路径相连——可能是一般人理解的概念。一般意义下的连通概念稍微抽象一些。在我看来,连通性有两个重要的用场:一个是用于证明一般的中值定理(Intermediate Value Theorem),还有就是代数拓扑,拓扑群论和李群论中讨论根本群(Fundamental Group)的阶。
Compact set 紧集
Compactness似乎在初等微积分里面没有专门出现,不过有几条实数上的定理和它其实是有关系的。比如,“有界数列必然存在收敛子列”——用compactness的语言来说就是——“实数空间中有界闭集是紧的”。它在拓扑学中的一般定义是一个听上去比较抽象的东西——“紧集的任意开覆盖存在有限子覆盖”。这个定义在讨论拓扑学的定理时很方便,它在很多时候能帮助实现从无限到有限的转换。对于分析来说,用得更多的是它的另一种形式 ——“紧集中的数列必存在收敛子列”——它体现了分析中最重要的“极限”。Compactness在现代分析中运用极广,无法尽述。微积分中的两个重要定 理:极值定理(Extreme Value Theory),和一致收敛定理(Uniform Convergence Theorem)就可以借助它推广到一般的形式。
从某种意义上说,点集拓扑学可以看成是关于“极限”的一般理论,它抽象于实数理论,它的概念成为几乎所有现代分析学科的通用语言,也是整个现代分析的根基所在。
3.4微分几何:流形上的分析——在拓扑空间上引入微分结构
拓扑学把极限的概念推广到一般的拓扑空间,但这不是故事的结束,而仅仅是开始。在微积分里面,极限之后我们有微分,求导,积分。这些东西也可以推广到拓扑空间,在拓扑学的基础上建立起来——这就是微分几何。
从教学上说,微分几何的教材,有两种不同的类型,一种是建立在古典微机分的基础上的“古典微分几何”,主要是关于二维和三维空间中的一些几何量的计算,比如曲率。还有一种是建立在现代拓扑学的基础上,这里姑且称为“现代微分几何”——它的核心概念就是“流形”(manifold)——就是在拓扑空间的基础上加了一套可以进行微分运算的结构。现代微分几何是一门非常丰富的学科。比如一般流形上的微分的定义就比传统的微分丰富,我自己就见过三种从不同角度给出的等价定义——这一方面让事情变得复杂一些,但是另外一个方面它给了同一个概念的不同理解,往往在解决问题时会引出不同的思路。除了推广微积分的概念以外,还引入了很多新概念:tangent space, cotangent space, push forward, pull back, fibre bundle, flow, immersion, submersion 等等。
近些年,流形在machine learning似乎相当时髦。但是,坦率地说,要弄懂一些基本的流形算法, 甚至“创造”一些流形算法,并不需要多少微分几何的基础。对我的研究来说,微分几何最重要的应用就是建立在它之上的另外一个分支:李群和李代数——这是数学中两大家族分析和代数的一个漂亮的联姻。分析和代数的另外一处重要的结合则是泛函分析,以及在其基础上的调和分析。
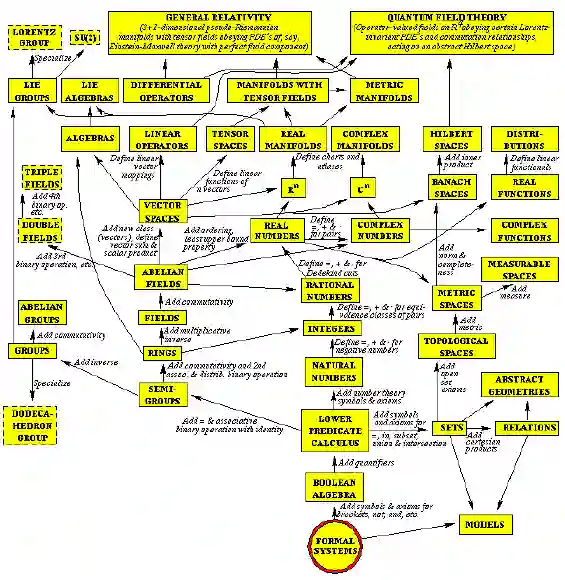
四、代数:一个抽象的世界
回过头来,再说说另一个大家族——代数。
如果说古典微积分是分析的入门,那么现代代数的入门点则是两个部分:线性代数(linear algebra)和基础的抽象代数(abstract algebra)——据说国内一些教材称之为近世代数。
代数——名称上研究的似乎是数,在我看来,主要研究的是运算规则。一门代数, 其实都是从某种具体的运算体系中抽象出一些基本规则,建立一个公理体系,然后在这基础上进行研究。一个集合再加上一套运算规则,就构成一个代数结构。
在主要的代数结构中,最简单的是群(Group)——它只有一种符合结合率的可逆运算,通常叫“乘法”。如果,这种运算也符合交换率,那么就叫阿贝尔群 (Abelian Group)。如果有两种运算,一种叫加法,满足交换率和结合率,一种叫乘法,满足结合率,它们之间满足分配率,这种丰富一点的结构叫做环(Ring), 如果环上的乘法满足交换率,就叫可交换环(Commutative Ring)。如果,一个环的加法和乘法具有了所有的良好性质,那么就成为一个域(Field)。基于域,我们可以建立一种新的结构,能进行加法和数乘,就构成了线性代数(Linear algebra)。
代数的好处在于,它只关心运算规则的演绎,而不管参与运算的对象。只要定义恰当,完全可以让一只猫乘一只狗得到一头猪:-)。基于抽象运算规则得到的所有定理完全可以运用于上面说的猫狗乘法。当然,在实际运用中,我们还是希望用它 干点有意义的事情。学过抽象代数的都知道,基于几条最简单的规则,比如结合律,就能导出非常多的重要结论——这些结论可以应用到一切满足这些简单规则的地 方——这是代数的威力所在,我们不再需要为每一个具体领域重新建立这么多的定理。
4.1关于抽象代数
抽象代数有在一些基础定理的基础上,进一步的研究往往分为两个流派:研究有限的离散代数结构(比如有限群和有限域),这部分内容通常用于数论,编码,和整数方程这些地方;另外一个流派是研究连续的代数结构,通常和拓扑与分析联系在 一起(比如拓扑群,李群)。我在学习中的focus主要是后者。
4.2线性代数:“线性”的基础地位
对于做Learning, vision, optimization或者statistics的人来说,接触最多的莫过于线性代数——这也是我们在大学低年级就开始学习的。线性代数,包括建立在它基础上的各种学科,最核心的两个概念是向量空间和线性变换。线性变换在线性代数中的地位,和连续函数在分析中的地位,或者同态映射在群论中的地位是一样的 ——它是保持基础运算(加法和数乘)的映射。
在learning中有这样的一种倾向——鄙视线性算法,标榜非线性。也许在很多场合下面,我们需要非线性来描述复杂的现实世界,但是无论什么时候,线性都是具有根本地位的。没有线性的基础,就不可能存在所谓的非线性推广。我们常用的非线性化的方法包括流形和kernelization,这两者都需要在某个阶段回归线性。流形需要在每个局部建立和线性空间的映射,通过把许多局部线性空间连接起来形成非线性;而kernerlization则是通过置换内积结构把原线性空间“非线性”地映射到另外一个线性空间,再进行线性空间中所能 进行的操作。而在分析领域,线性的运算更是无处不在,微分,积分,傅立叶变换,拉普拉斯变换,还有统计中的均值,通通都是线性的。
4.2.1泛函分析:从有限维向无限维迈进
在大学中学习的线性代数,它的简单主要因为它是在有限维空间进行的,因为有限,我们无须借助于太多的分析手段。但是,有限维空间并不能有效地表达我们的世界——最重要的,函数构成了线性空间,可是它是无限维的。对函数进行的最重要的运算都在无限维空间进行,比如傅立叶变换和小波分析。这表明了,为了研究函数(或者说连续信号),我们需要打破有限维空间的束缚,走入无限维的函数空间——这里面的第一步,就是泛函分析。
泛函分析(Functional Analysis)是研究的是一般的线性空间,包括有限维和无限维,但是很多东西在有限维下显得很trivial,真正的困难往往在无限维的时候出现。在泛函分析中,空间中的元素还是叫向量,但是线性变换通常会叫作“算子”(operator)。除了加法和数乘,这里进一步加入了一些运算,比如加入范数去表达“向量的长度”或者“元素的距离”,这样的空间叫做“赋范线性空间”(normed space),再进一步的,可以加入内积运算,这样的空间叫“内积空间”(Inner product space)。
大家发现,当进入无限维的时间时,很多老的观念不再适用了,一切都需要重新审视。
1、所有的有限维空间都是完备的(柯西序列收敛),很多无限维空间却是不完备的(比如闭区间上的连续函数)。在这里,完备的空间有特殊的名称:完备的赋范空间叫巴拿赫空间(Banach space),完备的内积空间叫希尔伯特空间(Hilbert space)。
2、在有限维空间中空间和它的对偶空间的是完全同构的,而在无限维空间中,它们存在微妙的差别。
3、在有限维空间中,所有线性变换(矩阵)都是有界变换,而在无限维,很多算子是无界的(unbounded),最重要的一个例子是给函数求导。
4、在有限维空间中,一切有界闭集都是紧的,比如单位球。而在所有的无限维空间中,单位球都不是紧的——也就是说,可以在单位球内撒入无限个点,而不出现一个极限点。
5、在有限维空间中,线性变换(矩阵)的谱相当于全部的特征值,在无限维空间 中,算子的谱的结构比这个复杂得多,除了特征值组成的点谱(point spectrum),还有approximate point spectrum和residual spectrum。虽然复杂,但是,也更为有趣。由此形成了一个相当丰富的分支——算子谱论(Spectrum theory)。
6、在有限维空间中,任何一点对任何一个子空间总存在投影,而在无限维空间中, 这就不一定了,具有这种良好特性的子空间有个专门的名称切比雪夫空间(Chebyshev space)。这个概念是现代逼近理论的基础(approximation theory)。函数空间的逼近理论在Learning中应该有着非常重要的作用,但是现在看到的运用现代逼近理论的文章并不多。
4.2.2继续往前:巴拿赫代数,调和分析,李代数
基本的泛函分析继续往前走,有两个重要的方向。第一个是巴拿赫代数 (Banach Algebra),它就是在巴拿赫空间(完备的内积空间)的基础上引入乘法(这不同于数乘)。比如矩阵——它除了加法和数乘,还能做乘法——这就构成了一 个巴拿赫代数。除此以外,值域完备的有界算子,平方可积函数,都能构成巴拿赫代数。巴拿赫代数是泛函分析的抽象,很多对于有界算子导出的结论,还有算子谱 论中的许多定理,它们不仅仅对算子适用,它们其实可以从一般的巴拿赫代数中得到,并且应用在算子以外的地方。
巴拿赫代数让你站在更高的高度看待泛函分析中 的结论,但是,我对它在实际问题中能比泛函分析能多带来什么东西还有待思考。
最能把泛函分析和实际问题在一起的另一个重要方向是调和分析 (Harmonic Analysis)。我在这里列举它的两个个子领域,傅立叶分析和小波分析,我想这已经能说明它的实际价值。它研究的最核心的问题就是怎么用基函数去逼近和构造一个函数。它研究的是函数空间的问题,不可避免的必须以泛函分析为基础。除了傅立叶和小波,调和分析还研究一些很有用的函数空间,比如Hardy space,Sobolev space,这些空间有很多很好的性质,在工程中和物理学中都有很重要的应用。对于vision来说,调和分析在信号的表达,图像的构造,都是非常有用的工具。
五、分析与代数的结合
当分析和线性代数走在一起,产生了泛函分析和调和分析;当分析和群论走在一 起,我们就有了李群(Lie Group)和李代数(Lie Algebra)。它们给连续群上的元素赋予了代数结构。我一直认为这是一门非常漂亮的数学:在一个体系中,拓扑,微分和代数走到了一起。
在一定条件下,通过李群和李代数的联系,它让几何变换的结合变成了线性运算,让子群化为线性子空间,这样就为Learning中许多重要的模型和算法的引入到对几何运动的建模创造了必要的条件。因此,我们相信李群和李代数对于vision有着重要意义,只不过学习它的道路可能会很艰辛,在它之前需要学习很多别的数学。
作者:林达华
来源:P.Linux‘s blog与 ima
网 址:http://www.penglixun.com/study/science/mit_math_system
高等数学、线性代数、概率论与数理统计、几何学这些知识可以用来干什么?主要应用有哪些?

知乎@谢漠烟
其他三项,不研究少数工科确实没用,但概率统计真乃应用数学之王。鄙人学业从数学院开始,以经济学院结束,现在在证券公司做苦逼行业研究,深有体会。
概率统计抛开了数学中的「确定性」,以「不确定性」的视角看待世界,并且做出了「量化不确定性」的壮志,这种气魄,真的不是其他数学分支能够比拟的。
大多数数学分支,比如数学分析(对不起,高等数学这么业余的词我实在不习惯),都是站在高峰看人类,是上帝的视角,研究出美轮美奂的数学公理框架。
但是概率统计,真正贴合日常生活中人类的感知。
在社会中,并不存在「给你一个因为,你还给我一个所以」的确定性。一切社会规律,都需要概率统计来挖掘!
所以,绝大多数社会科学最终都会通过概率统计走向量化,这也是现在「经济学帝国主义」泛滥的原因——毕竟经济学是数学渗透最狠的社会科学了。
举几个例子。
1. 经济学
经济学中,被称为恐怕是经济学最准确的定理是恩格尔系数:随着收入的提高,食物消费比重下降。这个如果没有概率统计的挖掘,仅仅凭眼睛去看是无效的。
因为恩格尔系数定理,如果翻译成数学语言:其实是「当收入提高时,在 90%的情况下,食物消费比重有所下降」。只有明白了这一点,才能够有力驳斥对恩格尔系数的质疑——毕竟你总能找到增加了一点收入就去吃一顿大餐的反例。
2. 游戏营销
游戏营销中有一个很有用的指标,叫做 ARPU 值。即平均每用户收入,一个游戏 1 千万用户,每个月收入 5 千万,那么月 ARPU 就是 5 元。
学了概率统计的人,就应该很敏感地意识到,5 元的 ARPU 值,不是每多一个用户,就多 5 块钱的收入。5 元只是期望(均值),但是期望仅仅是数据分布中的一个重要指标而已,即使加上方差,也不能反映全部。
所以,5 元的 ARPU 值游戏,和另一个 5 元 ARPU 值游戏,是本质上不一样的!
这一点,突出反映在中国和海外的手机游戏的区别。
一旦用概率统计分析海内外游戏的差别,就会发现,同样 ARPU 值为 5 的手机游戏,中国游戏方差极大,而海外游戏方差小很多。
所以继续深挖,采用另一个统计指标 ARPPU,平均每付费用户收入。(上述游戏,如果有 100 万付费用户,ARPPU 为 50)
这个时候,你就能发现,同样是 ARPU 为 5 元的游戏,国内 ARPP可能是 100,而海外的是 30。
那么你需要做什么呢?这个时候经营过的人就能想出,面对海外市场,你应该扩大流量,让游戏好玩。
面对国内市场,你要伺候好土豪,比如分级客服(交钱最多的 VIP1,其次的 VIP2,等等),比如弄几个人和金主土豪陪玩坑钱,等等等等。
而现在国内手游市场,就是这样做的。
3. 考试
用概率统计的思路,你就知道考试是由三方面决定的。一、水平(期望);二、稳定性(方差),以上两点决定了你分数的概率分布;三、运气(最后落在哪一个样本上)。
你能控制的只有前两项。
所以面对比较有希望的考试,或者高考这样考在每个分数都有用的考试,你应该做的是增加期望,减小方差两方面努力,就是努力做题目(提高期望),做题目做得面面俱到(减小方差)。
面对如数学竞赛这样考不上一等奖啥用都没有的考试,而你水平恰恰又差一个档次,希望相对较小,这时你要做的呢,就是努力做题目(提高期望),把最重要最可能考的类型钻研到很深,不太可能考的就算了(增加方差)。
知乎@西贝心合
大家从各个方面解释了这几课的功用,那我就从工程(机械工程)的角度来说明一下吧 。
第一,高等数学,这门课通用性之广可能是你所想不到的,举个例子(因为我是机电专业,故而例子大部分是机电设计):
PID 控制器,P 是比例,I 是积分,D 是微分,PID 控制器可以模拟电路,也可以是数字系统来模拟的电路。
例如用单片机来模拟,但无论哪种方法,都涉及系统的参数设定,顾名思义,PID 需要比例参数,积分参数,微分参数,这三者的确定以及之后的运算,均是在高等数学的基础上的。
液压伺服阀,对于液压方面的计算,其实原理应用均为「流体力学」,对于流体力学,你们日后大概会接触到,通用公式,基本上都是需要高数基础来推导的。详情请去图书馆借阅《液体力学》 。
第二,线性代数,这门课,说实话,更是牛 B,我想你在高中时代肯定学过坐标系的转换,例如坐标平移,极坐标转换等等。
那你现在想一个问题,给你一个两关节机械手,你如何控制这个机械手的运动问题,我如何控制各个伺服电机来决定这些机械的运动位置与力的大小呢?
这些问题在《机器人运动学》与《机器人动力学》中有详细的探讨。
如果让我告诉你,它们运用到的知识,可以这么说,用的是「矩阵」,我想通过线代的学习,你应该对它不会陌生,对矩阵的运算,如求逆阵啦,伴随阵啦,都需要。这只是在我了解的领域内知道的线代应用。
第三,概率与统计,我想这个不用我多说了,古典概率不必多讲,生活中用到它的情况比比皆是,还有一些实例,我想在课本上应该有所涉及,如医学上,用概率论来判断一种新型药物是否有效。
统计呢,这个……以后你到公司里,不能一涉及账单就找财务吧,那财务还不忙死……还有很多问题账务也处理不了,因为如果涉及工业工程,学经济的财务还真不一定懂,你可以看一下《工程经济学》,这里面有很多统计方面的应用。
第四,几何学,对于一些经典的几何模型,其实我们每天都在用到,例如求圆周长,面积,求一些标准体的体积等等,只不过我们把这些知识划归了常识。
而现代文明仅仅是这些基本的几何知识是远远不够的,所以我们要用很多高等数学的知识来解决一些几何问题。
例如几何学中的一个重要的分支——解析几何,工程中常用的 Pro/E 三维软件,只要你构建了一个几何体,无论它有多么的不规则,只需要点一下求体积的按键,它就能给你算出来,如何实现呢?电脑运算快,但不智能,所以算法要你来写,用程序写出来,这些算法,其实就是高等数学中的解析几何啦。
当然,不会那么简单,其中定然还要用到一些更高深的数学,例如一些有限元的算法之类的。(没有深入了解过 Pro/E 中的求体积算法,如若有误还请见谅)
如@陈然所说,这些课的学习能让你用一种区别于普通人的眼光来审视这个世界,你会惊奇地发现,这个世界其实是由数学构成的。(学美术的会认为世界是由颜色构成的,学文学的会认为世界是由思想汇聚的,学经济的会认识世界是由货币铸成的。)你可以更抽象地去认识这个世界,了解它的前因后果。陈然的答案很棒,我也很赞同,不过我想,还是补充一些关于现实生活中能看到的「活生生」的例子比较好。
我在此作出这个解答的原因,也是希望大家知道,这些东西并不是所谓的一无所用,它们功用之大,超乎我们的想象,如果没有高等数学,你连一台普通机床都做不出来,更不必说什么数控系统了。
其实随着学习的深入你会发现,其实就你们学的这点儿高等数学,都不够用,如果你以后要自己做工程,肯定还要补习一些拉氏变换,傅氏变换,Z 变换,更有甚者要学一些专门领域才用得到的「专业」的数学,如《数值分析》,系统变式等,不过那时候,我想,你已经深入地了解到数学的意义了。
我曾经也迷惑过,但没有人给我解答过,但庆幸,我没有放下数学,物理,化学,现如今,才真切地发现这些学问之美,希望我的答案,对你有所帮助。
机器学习的数学焦虑
机器学习的数学焦虑

开始机器学习之旅,需要什么层次的数学功底? 尤其是对于那些没有学过数学和统计学的同学们来说,这个问题当前不甚清楚,在这篇文章中,我将要为那些使用机器学习技术来开发产品或做学术研究的人们提供一些数学背景方面的建议。这些建议源于我与机器学习工程师、研究人员和教育工作者的对话,以及我在机器学习研究和产业方面的独到经验。

为了构造(机器学习中)数学的背景,我会先讲一些与传统课堂不同的思维模式和策略。然后,我会概述不同类型机器学习工作所需的具体背景,毕竟机器学习涉及的学科范围太广泛了(它涵盖了高中级别的统计和微积分,也涵盖了概率图形模型(PGM)的最新进展)。
我希望读者们在读到文章的最后时,能够知道自己有效使用机器学习所必需的数学知识。
作为这篇文章的前言,我想说:对于不同学习者的个人需求或目标来说,学习的风格、架构和资源都应该是独一无二的!
数学焦虑症的小贴士

事实证明,很多人——包括工程师——都害怕数学。首先,我想谈谈“擅长数学”这类传说。
事实是,擅长数学的人都做过大量的数学练习。因此,在研究数学问题被卡住时,他们依然能够“风雨不动安如山”。如最近的研究所示,学生的心态,而非先天才能,才是预测一个人学习数学的能力的主要因素。
要清楚的是,要达到这种境界,需要时间和精力。这显然不是你天生就有的能力。本文的剩余部分将帮助您确定所需的数学功底,并概述构建它的策略。
万事开头难
作为软性先修数学条件,我们假设你对线性代数/矩阵微积分都有了解,这样你就不会为奇怪的符号苦恼。同时我们还假设你有基础的概率知识。我们鼓励你拥有基本的编程能力,这是领悟机器学习中的数学的有力工具。之后,你可以根据你感兴趣的内容调整你的学习重点。
如何在课外学习数学?

我相信学习数学的最佳方式是以学生的身份全职学习。脱离了学校的环境,你可能不太容易获得系统的知识结构、正能量的同学压力和其他可用资源。
为了在课外学习数学,我建议大家将学习小组或午餐研讨会作为学习的重要途径。在研究型的实验室中,这可能以阅读小组的形式呈现。在构建知识结构方面,你的小组可以把教科书各章节过一遍,并定期对课程进行讨论,同时通过Slack平台的途径参与远程问答。
这里,企业文化发挥着重要的作用——这种“额外”的研究学习应该受到管理层的鼓励和激励,而不是被视为影响产品交付的消极怠工行为。事实上,虽然短期内会花费一些成本,但是构建同伴驱动的学习环境可以使你在长期的工作中更有效率。
数学与代码
在机器学习工作流程中,数学和代码紧密结合。代码通常直接由数学直觉构建,有时它甚至会和数学符号使用相同的句法。事实上,现代数据科学框架应用(例如NumPy)使得数学运算(例如矩阵/矢量积)与可读代码之间的转换变得直观和有效。
我鼓励你将编写代码作为巩固学习的一种方式。学习数学和编写代码都依赖于你对问题理解和表述的精准程度。例如,手动编写损失函数或优化算法,就是真正理解这些基础概念的好方法。
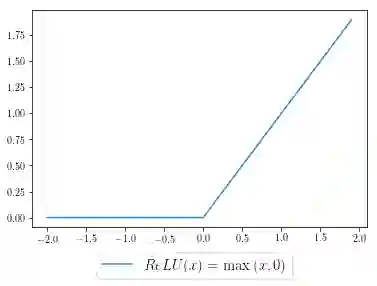
让我们来探索一个实际的问题:在你的神经网络中实现ReLU函数激活的反向传播(是的,即使Tensorflow / PyTorch可以替你做这个!)。这里简单介绍一下,反向传播是一种依赖于微积分链式规则来有效计算梯度的技术。为了在这个问题设定下使用链式规则,我们将上游导数与ReLU函数的梯度相乘。
我们先将ReLU激活函数进行可视化(就是下图的样子),然后这样定义这个函数:
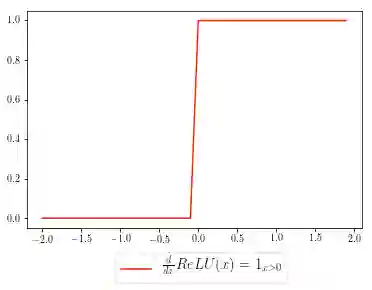
为了计算函数的梯度(直观来说就是斜率),你可以想象出这样一下分段函数,如下面的指示函数所示:
NumPy为我们提供了有用且直观的语法——我们的激活函数(蓝色曲线)可以通过代码表述出来,其中x是我们的输入,relu是我们的输出:
relu = np.maximum(x, 0)
ReLU函数的梯度函数(红色曲线)可以如下所示,grad表示上游梯度:
grad[x < 0] = 0
在没有首先自己推导梯度公式的情况下,这行代码可能没有任何意义。在我们的代码中,对于满足[h <0]条件(即x<0)的所有元素,将其对应上游激活函数的梯度(grad)数值设置为0。在数学上,这实际上相当于ReLU梯度函数的分段表示,所有x轴上小于0的数值,当乘以上游梯度时,它的值会变成0。
正如我们所见,通过我们对微积分的基本理解,我们可以清楚地理解代码的含义。
构建机器学习产品必需的数学知识

为了介绍这一节,我与机器学习工程师进行了交谈,确定了数学在调试系统时最有力的地方。以下是工程师基于数学见解回答的问题示例。
如果你还没有遇到过它们,请不要担心。希望本节能够为你提供一些特定问题的相关内容,也许你也会遇到类似的问题并尝试解决哟!
Q:我该用哪种聚类方法可视化高维的客户数据呢?
A:PCA或者tSNE。
Q:我该如何校准用来阻隔虚假用户交易的安全阈值(例如在0.9或0.8的置信水平下)?
A:可以使用概率校准(Probability calibration)。
Q:描述我卫星数据在世界特定地区(如硅谷与阿拉斯加州)的偏差的最佳方法是什么?
A:这是一个开放的研究型问题。也许可以基于“人口平价”(demographic parity,该方法是要求预测必须与某特定敏感属性不相关)的原则展开。
通常,统计和线性代数可以通过某种方式应用于这些问题中的任何一个。但是,要获得满意的答案通常需要针对特定领域的方法。如果是这样的话,你如何缩小你所需学习的数学范畴呢?
定义一个系统
我们并不缺乏资源(例如数据分析使用scikit-learn,深度学习使用keras)去帮助我们进行系统建模。而在建模之前,我们需要围绕将要被建模的系统考虑这些问题:
系统的输入/输出分别是什么?
应该如何准备好合适的数据格式,从而适应系统要求?
如何进行特征建模或数据整理,以便于模型的推广?
如何为需要解决的问题设定合理的目标?
你会惊讶地发现——要定义一个系统,其实非常复杂。而搭建数据工作流(data pipeline)也并不容易。换句话说,构建一个机器学习产品需要进行大量的繁琐复杂的工作;而这些工作并不需要太深的数学背景。
数学需要“按需学习”
当你一头扎进一个机器学习的任务中时,会发现其中有些步骤对你来说难以进行,这种情况在进行算法调试时尤为常见。当你停滞其中时,是否知道该如何解决这一窘境呢?你设定的权重是否合理?
为什么模型没有按照某个损失定义进行收敛?衡量成功的正确指标是什么?此时,有一些方法可以帮助到你:对数据做出假设、以不同方式约束优化、或尝试不同的算法。
通常,你会发现建模/调试过程中需要数学直觉(例如,选择损失函数或评估指标),这些直觉可能有助于做出明智的工程决策。 这些是你学习的机会!
来自Fast.ai的Rachel Thomas是这种“按需”方法的支持者——在教育学生时,她发现对于深度学习的学生来说,让他们对将要学习的内容感到兴奋更为重要。之后,针对这些学生的数学教育即可“按需”填补之前未涉及的知识漏洞。

接下来我将介绍对研究性工作中的机器学习方法有用的数学思维方式。批判性的观点认为,机器学习研究方法就像是就像是“拿来主义”,人们只是通过把更多运算扔进模型中,从而获得更好的预测表现。在一些圈子里,研究人员对实证研究方法仍然持怀疑态度,认为这些方法缺乏数学上的严谨性(例如某些深度学习方法),这些方法是不能将人类智慧发挥到极致的。
值得关注的是,研究界是建立在现有系统和假设的基础上,而这些系统和假设可能不会扩展我们对该领域的基本理解。研究人员需要提供新的基本模块,供我们在该领域中获取全新洞察力和方法。
这可能意味着我们需要像“深度学习教父” Geoff Hinton在他最近的Capsule Networks论文中所做的那样 ,重新思考构建某些领域的基础知识(如应用于图形分类的卷积神经网络)。
为了迈出下一步,我们需要提一些基本问题。这需要在数学方面的极度熟练——深度学习一书的作者Michael Nielsen称之为“有趣的探索”。这个过程涉及数千小时停滞、提问、重新思考问题以探索新观点。
“有趣的探索”使科学家们能够提出深刻,富有洞察力的问题,而不仅仅是简单的想法或架构的结合。显而易见,想要学会机器学习研究领域内需要的所有知识,是不可能的任务!要正确地进行“有趣的探索”,你需要遵循自己的兴趣,而不是为最热门的新结果感到焦虑。
机器学习研究是一个非常丰富的研究领域。当然,它在公平性、可解释性和可获得性方面也存在亟待解决的问题。在所有科学学科中都是如此,基本思维的获得并不能一蹴而就。要在解决关键问题所需的高水平数学框架的广度进行思考,需要长期的耐心。
将机器学习研究“大众化”
希望我没有把“研究数学”描绘得太深奥,因为这些通过数学而产生的思考应该以直观的形式呈现!可悲的是,许多机器学习论文仍然充斥着复杂且不一致的术语,使关键的直觉难以被辨别。作为一名学生,你可以尝试将密集的论文翻译成容易被直观理解和消化的小块文章,通过博客和推特等发表,这将对你自己和这个领域大有裨益。你甚至可以从distill.pub中找些例子,当作解释机器模型研究方法结果的读物。换句话说,将技术思想的祛魅化作“有趣的探索”手段——你自己的学习(和机器学习Twitter)会感谢你的!
主要领悟
总的来说,我希望这篇文章为你提供了一个思考研究机器学习所需数学教育的开端。
不同的问题需要不同程度的直觉,我鼓励你首先弄清楚你的目标是什么。
如果你希望构建产品,请通过问题寻找同行和学习小组,并深入研究最终目标,激发你的学习。
在研究领域,广泛的数学基础可以为你提供工具,通过提供新的基础知识来推动该领域的发展。
在工程领域中,机器学习的数学理论基础尤为重要
数学在机器学习中非常重要,但我们通常只是借助它理解具体算法的理论与实际运算过程。近日加州大学圣巴巴拉分校的 Paul J. Atzberger 回顾了机器学习中的经验风险与泛化误差边界,他认为在科学和工程领域中,我们需要从基本理论与数学出发高效使用现有方法,或开发新方法来整合特定领域与任务所需要的先验知识。

近期研究人员越来越多地关注将机器学习方法应用到科学、工程应用中。这主要是受自然语言处理(NLP)和图像分类(IC)[3] 领域近期发展的影响。但是,科学和工程问题有其独特的特性和要求,对高效设计和部署机器学习方法带来了新挑战。这就对机器学习方法的数学基础,以及其进一步的发展产生了强大需求,以此来提高所使用方法的严密性,并保证更可靠、可解释的结果。正如近期当前最优结果和统计学习理论中「没有免费的午餐」定理所述,结合某种形式的归纳偏置和领域知识是成功的必要因素 [3 , 6]。因此,即使是现有广泛应用的方法,也对进一步的数学研究有强需求,以促进将科学知识和相关归纳偏置整合进学习框架和算法中。本论文简单讨论了这些话题,以及此方向的一些思路 [1 , 4 , 5]。
在构建机器学习方法的理论前,简要介绍开发和部署机器学习方法的多种模态是非常重要的。监督学习感兴趣的是在不完美条件下找出输入数据 x 的标注与输出数据之间的函数关系 f,即 y = f ( x) + ξ,不完美条件包括数据有限、噪声 ξ 不等于 0、维度空间过大或其他不确定因素。其他模态包括旨在发现数据内在结构、找到简洁表征的无监督学习,使用部分标注数据的半监督学习,以及强化学习。本文聚焦监督学习,不过类似的挑战对于其他模态也会存在。
应该强调近期很多机器学习算法的成功(如 NLP、IC),都取决于合理利用与数据信号特质相关的先验知识。例如,NLP 中的 Word2Vec 用于在预训练步骤中获取词标识符的词嵌入表示,这种表示编码了语义相似性 [3]。在 IC 中,卷积神经网络(CNN)的使用非常普遍,CNN 通过在不同位置共享卷积核权重而整合自然图像的先验知识,从而获得平移不变性这一重要的属性 [3]。先验知识的整合甚至包括对这些问题中数据信号的内在层级和构造本质的感知,这促进了深层架构这一浪潮的兴起,深层架构可以利用分布式表征高效捕捉相关信息。
在科学和工程领域中,需要类似的思考才能获取对该领域的洞察。同时我们需要对机器学习算法进行调整和利用社区近期进展,以便高效使用这些算法。为了准确起见,本文对监督学习进行了简要描述。与传统的逼近理论(approximation theory)相反,监督学习的目的不仅是根据已知数据逼近最优解 f,还要对抗不确定因素,使模型在未见过的数据上也能获得很好的泛化性能。这可以通过最小化损失函数 L 来获得,其中 L 的期望定义了真实风险 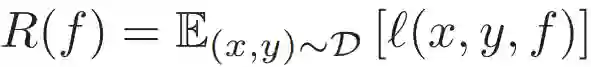
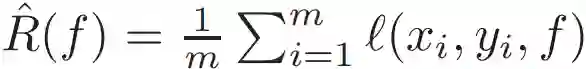
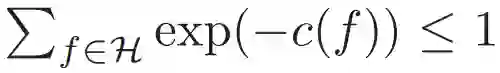
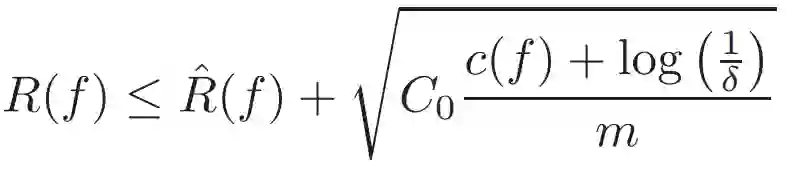
其中,概率 1 − δ 适用于随机数据集 [2]。类似的边界也可以从具备其他复杂度(如 VC 维或 Rademacher 复杂度)的连续假设空间中推导出。这在数学层面上捕捉了当前很多对应 RHS 优化的训练方法和学习算法。常见的选择是适用于有限空间的经验风险最小化,使用 c(f) = log(|H|),其中 c 不再在正则化中发挥作用。
我们可以了解到如何通过对假设空间 H 和 c(f) 的谨慎选择来实现更好的泛化与更优的性能。对于科学和工程应用而言,这可能包括通过设计 c(f) 或限制空间 H 来整合先验信息。例如限制 H 仅保持符合物理对称性的函数、满足不可压缩等限制、满足守恒定律,或者限制 H 满足更常见的线性或非线性 PDE 的类别 [1,4,5]。这可以更好地对齐优秀的 c(f) 和 R hat,并确保更小的真实风险 R(f)。尽管传统上这是机器学习的重点,但这不是唯一策略。
正如近期深度学习方法所展示的那样,你可以使用复杂的假设空间,但不再依赖于随机梯度下降等训练方法,而是支持更低复杂度的模型以仅保留与预测 Y 相关的输入信号 X。类似的机会也存在于科学和工程应用中,这些应用可获得关于输入信号相关部分的大量先验知识。例如,作为限制假设空间的替代方法,训练过程中你可以在输入数据上执行随机旋转,以确保选择的模型可以在对称情况下保持预测结果不变。还有很多利用对输入数据和最终目标的洞察来结合这些方法的可能性。
我们看到即使在本文提到的泛化边界类型方面也可以获取大量新观点。针对改进边界和训练方法做进一步的数学研究,可能对高效使用现有方法或开发新方法来整合先验知识方面大有裨益。我们希望本文可以作为在一般理论和当前训练算法中进行数学研究的开端,开发出更多框架和方法来更好地适应科学和工程应用。原文地址:https://arxiv.org/pdf/1808.02213.pdf
机器学习中的数学
【机器学习中的数学】从西格玛代数、测度空间到随机变量
σ代数
令X是一个样本空间(sample space)Ω的所有子集(subsets)的集合的一个子集,那么集合X被称为σ代数(σ-algebra)又叫σ域(σ-field)。
它有以下几个性质:
(1)Φ∈X;(Φ为空集)
(2)若A∈X,则A的补集A^c∈X;
(3)若Ai∈X(i=1,2,…)则∪Ai∈X;
可测空间
Ω是任意集合,而X是把Ω中的极端情况去掉后又Ω的子集组成的集合,这样剩下的就是可以处理的集合,所以(Ω,X)称为可测空间(a measurable set)。X满足σ代数的三个性质,我们可以对X中的元素定义测度,故X的元素称为可测集(measurable set)。
测度空间
定义了测度的可测空间称为测度空间。
令(Ω,X)为一个可测空间,在X中定义一个方程ν称为测度(a measure)。
它满足以下条件:
(i )非负性:0≤ν≤∞
(ii )ν(空集)=0
(iii)如果Xi ∈X,其中Xi互不相交,则ν(∪Xi)=Σν(Xi)。
那么(Ω,X,ν)称为测度空间(measure space)。
勒贝格测度(Lebesgue Measure)
数学上,勒贝格测度是赋予欧几里得空间的子集一个长度、面积、或者体积的标准方法。它广泛应用于实分析,特别是用于定义勒贝格积分。可以赋予一个体积的集合被称为勒贝格可测;勒贝格可测集A的体积或者说测度记作λ(A)。
如果A是一个区间[a, b], 那么其勒贝格测度是区间长度b−a。 开区间(a, b)的长度与闭区间一样,因为两集合的差是零测集。
如果区间是[0,1],勒贝格测度L([0,1])是一个概率测度。
概率空间
如果ν(Ω)=1,则ν是概率测度,记为P。(Ω,X,P)称为概率空间。
这样,我们可以将P当做是对集合的一种测度,将集合和概率联系起来。
概率论研究的概率空间就是一个测度空间(Ω,X,P),其中P是定义在X中的测度,叫概率测度。集合Ω我们一般叫做样本空间,X中的元素叫可测集,但是我们更愿意叫做事件,而把X叫做事件域。任取X中元素A,它是Ω的子集,这时是一个事件,它的测度P(A)就是事件A的概率。可见这三元组(Ω,X,P)中的东西缺一不可。
对可测空间和测度空间的讨论
我们知道任一事件都是样本空间的子集,但样本空间的子集却不一定是事件。为了讨论方便,还是用一个比较好理解的现象作一个比喻。 假设研究人的性取向,这样样本空间X={男,女,不男不女},由于不男不女不好确定其性取向,这样在研究时就将这种情况排出,只研究男和女。或者说,样本空间是Ω={全体男人和女人},是个有限集,其对应的事件域取F={Ω的子集全体}完全可以,(Ω, F)就是可测空间。你说的性取向问题对应的F上的概率测度P是未知的,需要用统计方法确定。
更常见的做法是在(Ω,F,P)上定义一个随机变量,用统计方法确定随机变量的分布而不是P本身。例如任取ω∈Ω,定义X(ω)=0;若ω是和尚,X(ω)=1;若ω是尼姑,X(ω)=2;若ω是丈夫,X(ω)=3;若ω是妻子,X(ω)=4。
随机变量
定义一个随机变量X是一个可测的映射(a measurable map)X:Ω->R(该映射将集合映射成一个实数),使得Ω的任意一个元素ω(即事件)通过X(ω)赋予其一个实数。
这里,可测的意思是对于每个x,都有{ω:X(ω)≤x} ∈ A,这里的A是一个σ代数,其中的元素是可测的。
所以,概率是一个作用在集合中的测度。
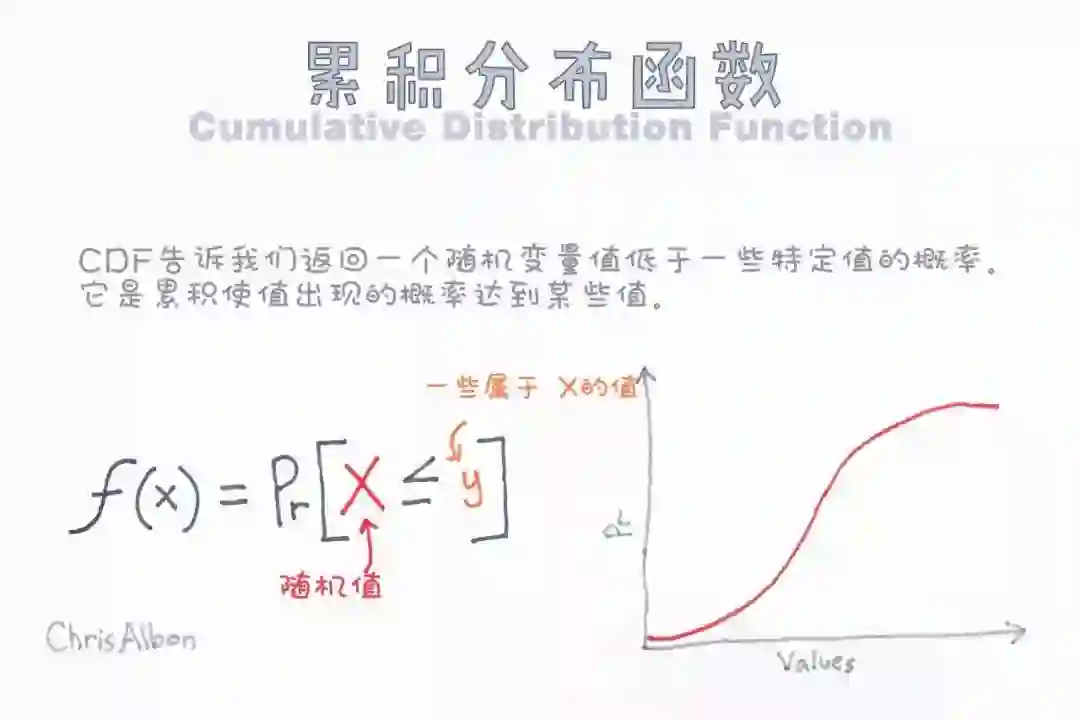
分布函数
分布函数(Distribution Function,又称Cumulation Distribution Function),是一个映射Fx:R->[0,1]。
Fx(x)=P(X≤x),分布函数Fx将一个事件对应的随机变量映射为0到1的一个概率值。
应用举例
说了这么多,那么随机变量、概率分布具体是怎么和可测映射联系上的呢?我们以Bernoulli分布为例,介绍一下这其中的隐含关系。
Bernulli分布的pmf(Probabilistic Mass Function)是
即当x=1时概率为p,当x=0时概率为1-p。
令样本空间Ω=[0,1],根据勒贝格测度,Pr([a,b])=b-a,其中0≤a<b≤1。
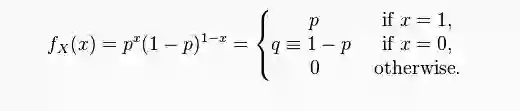
取一个固定的p∈(0,1),定义,当ω≤p时,X(ω)=1;当ω>p时,X(ω)=0。
于是,Pr(X=1) = Pr(ω≤p) = Pr([0,p]) = p; Pr(X=0)=1-p。
基于上面的介绍,我们可以发现,在日常的学习中,其实是省略了将集合映射到实数这一隐含的步骤的。
【机器学习中的数学】广义逆高斯分布及其特例
引言
广义逆高斯作为一种含义丰富的概率分布,其参数为特定值时又衍生出几种经典有用的分布,现做一整理介绍。
广义逆高斯分布(Generalized Inverse Gaussian Distribution)
广义逆高斯分布的概率密度函数为:
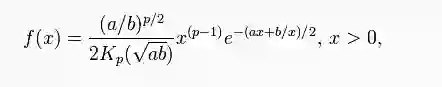
其中,Kp是a>0且b>0的第二类修正贝塞尔函数(Modified Bessel function of the second kind)。
特别要注意这里,支撑集是x>0,即对于非负随机变量。
其中第二类修正贝塞尔函数满足以下性质:
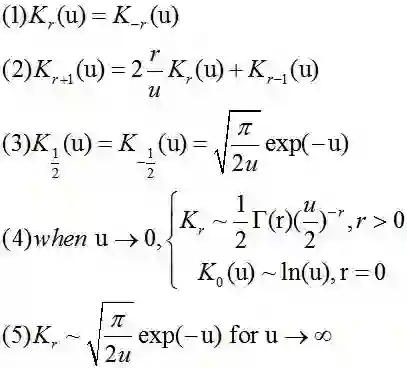
伽玛分布(Gamma Distribution)
当上面的广义逆高斯分布的b=0,r>0,a>0时,称为伽玛分布。
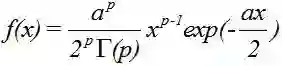
记为X~Ga(p,a/2),这里的p称为形状参数,a/2称为尺度参数。
其实际定义与观念是假设随机变量X为等到第p件事发生所需之等候时间。
伽玛分布满足加成性,当两随机变量服从Gamma分配,互相独立,且单位时间内频率相同时,Gamma分布具有加成性。
当p=1时,Gamma分布变成了指数分布(Exponential Distribution)。
逆伽玛分布(Inverse Gamma Distribution)
令广义逆高斯分布的参数a=0,r<0,b>0,就称作逆伽玛分布。
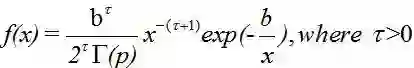
这里的τ=-p,记为IG(τ,b/2)。
逆高斯分布(Inverse Gaussian Distribution)
令广义逆高斯分布的参数p=-1/2,称为逆高斯分布。
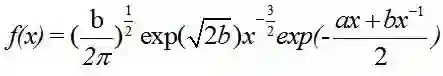
先验分布和后验分布共轭的意义
从贝叶斯角度进行参数估计,是求最大后验估计的过程。要求先验分布和后验分布是同一种形式但参数不同的分布(即先验分布和后验分布呈共轭关系),这是一个数学技巧,可以使计算变得简单,而求后验概率最大的积分过程转化成了求后验分布的众数(mode)的过程。
实例一
假设随机变量X~Bernoulli(θ),0<θ<1。
因为θ的取值是在(0,1)之间,很自然会想到Beta分布是定义在该区间的,故给θ一个Beta分布作为先验,θ~Beta(α,β)。
后验分布
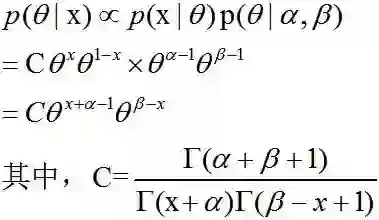
这也是一个Beta分布。
实例二
假设随机变量X~N(0,λ),这里我们把方差σ^2设为λ,其中λ>0。
(1)我们假设λ满足Gamma分布,λ~Ga(λ|r,α/2)。
这样,其后验
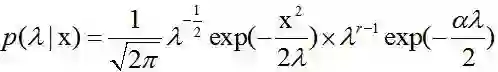
这是一个广义逆高斯分布,当然我们也可以把Gamma分布看做一个广义逆高斯分布,但这做起来比较麻烦
(2)我们假设λ满足逆Gamma分布,λ~Ig(τ,β/2)。
其后验为
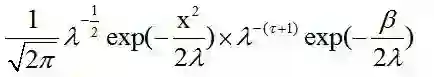
这也是一个逆Gamma分布。
这样方便计算。
【机器学习中的数学】比例混合分布
比例混合分布(Scale Mixture Distribution)
混合分布是来自其他随机变量的集合构成的随机变量的概率分布:一个随机变量是根据给定的概率从集合随机选取的,然后所选随机变量的值就得到了( first, a random variable is selected by chance from the collection according to given probabilities of selection, and then the value of the selected random variable is realized)。
当潜在的随机变量是连续的情况下,混合得到的随机变量也是连续的,并且其概率密度函数有时被称作是一个混合密度,其累积分布函数(cumulative distribution function)可以表示成其他分布函数的凸组合(convex combination,i.e. a weighted sum, with non-negative weights that sum to 1)。
有限可数混合体
给定一个有限的概率密度函数集合p1(x),…,pn(x),或者相对应的累积分布函数P1(x),…,Pn(x)和权值w1,…,wn(wi>=0,sum(wi)=1),该混合分布可以被表示为密度函数f,或者分布函数F:
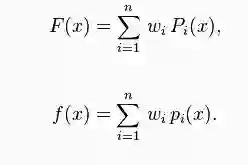
这种类型的混合体称作有限混合(finite mixture)。
不可数混合体
当组成的分布式不可数的,这个分布就被称为混合概率分布(compound probability distribution)。这种分布的构造是用积分来代替有限情况下的求和形式。
考虑一个随机变量为x,参数为a的概率密度函数p(x;a)。对于在集合A中的每一个值a,p(x;a)是一个关于x的概率密度函数,给出概率密度函数w(要求w非负且积分为1),则函数:
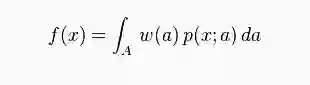
f(x)就是一个关于x的概率密度函数。
Gamma函数
了解Gamma函数的性质和一些有用的计算公式,在后面复杂的分布中会用到这些公式和表示方式。
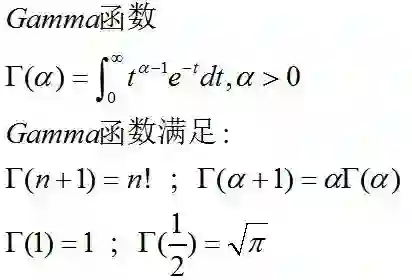
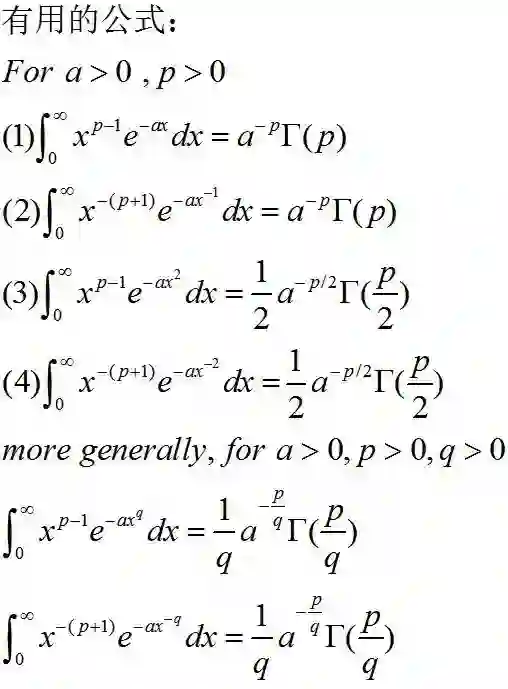
学生t-分布及其混合分布
学生t-分布(Student’s t-distribution)
在概率论和统计学中,学生t-分布(Student’s t-distribution),可简称为t分布。应用在估计呈正态分布的母群体之平均数。它是对两个样本均值差异进行显著性测试的学生t检定的基础。
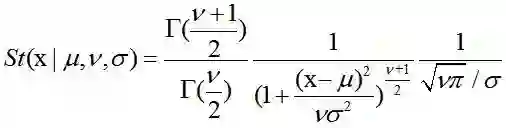
其中,ν被称作自由度(degrees of freedom),当ν=1时,该分布退化为柯西分布(Cauchy Distribution);当ν→∞时,该分布为高斯分布。
Scale Mixture of Normals
Student T分布可以看做是正态分布和Gamma分布的混合体,由于是连续分布,所以该混合体表示为积分形式。其公式推导如下,在求解积分时用到了之前Gamma函数中列举的有用的积分公式:
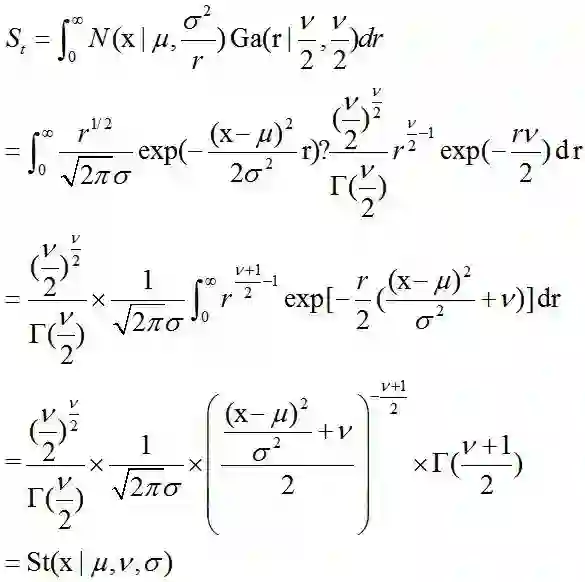
Laplace分布及其混合分布
laplace分布
在概率论与统计学中,拉普拉斯分布是以皮埃尔-西蒙·拉普拉斯的名字命名的一种连续概率分布。由于它可以看作是两个不同位置的指数分布背靠背拼接在一起,所以它也叫作双指数分布。两个相互独立同概率分布指数随机变量之间的差别是按照指数分布的随机时间布朗运动,所以它遵循拉普拉斯分布。
如果随机变量的概率密度函数分布为:
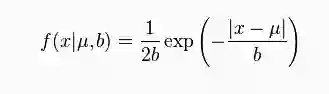
那么它就是拉普拉斯分布。其中,μ是位置参数,b>0是尺度参数。
Gaussian-Exponential Mixture
laplace分布可以看成是高斯分布和指数分布的混合体。

负二项分布及其混合分布
负二项分布(Negative Biomial Distribution)
负二项分布是统计学上一种离散概率分布。“负二项分布”与“二项分布”的区别在于:“二项分布”是固定试验总次数N的独立试验中,成功次数k的分布;而“负二项分布”是所有到成功r次时即终止的独立试验中,失败次数k的分布。
其概率质量函数为:
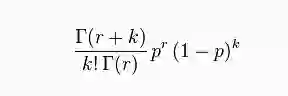
Gamma-Poisson Mixture
Negative Biomial分布可以看做是Gamma分布和泊松分布的混合体。
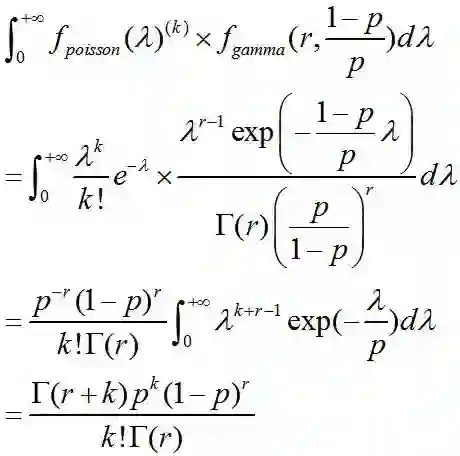
混合分布的意义
这里我们列举了三种常见分布及其混合分布,这种混合分布的表示形式的意义在于,复杂分布的期望和方差等数字特征不好求解,但可以将其表示为更加简单的分布的混合形式,我们知道高斯分布、泊松分布等分布的数字特征可以由其参数得到,这样的话,就可以很容易的通过简单的分布得到复杂分布的一些数字特征。
参考资料 机器学习技法课程,林轩田,台湾大学 转载请注明作者Jason Ding及其出处 GitCafe博客主页(http://jasonding1354.gitcafe.io/) 来源:机器人2025

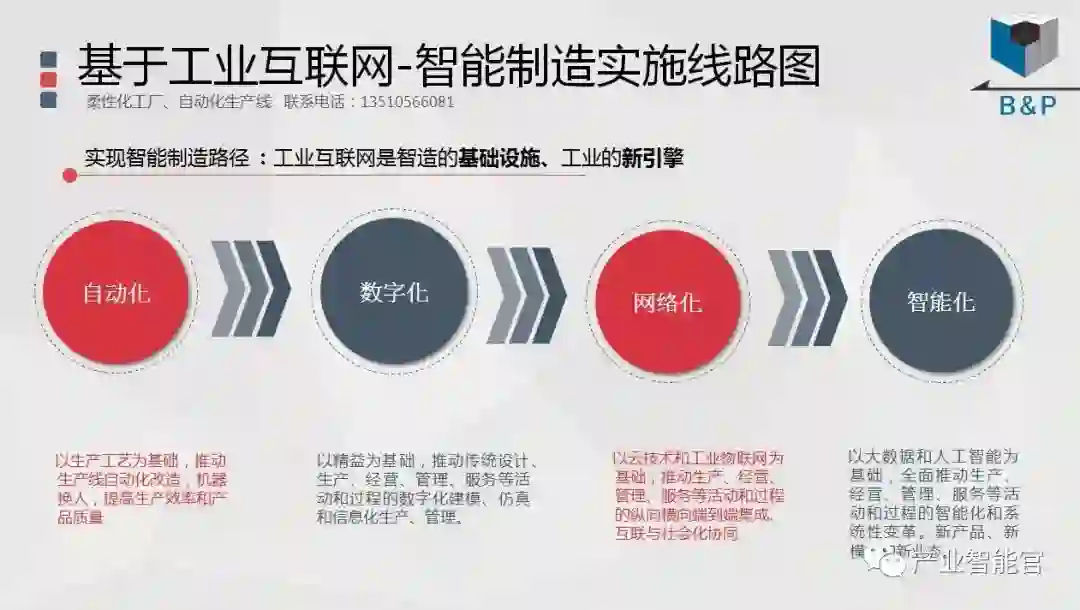

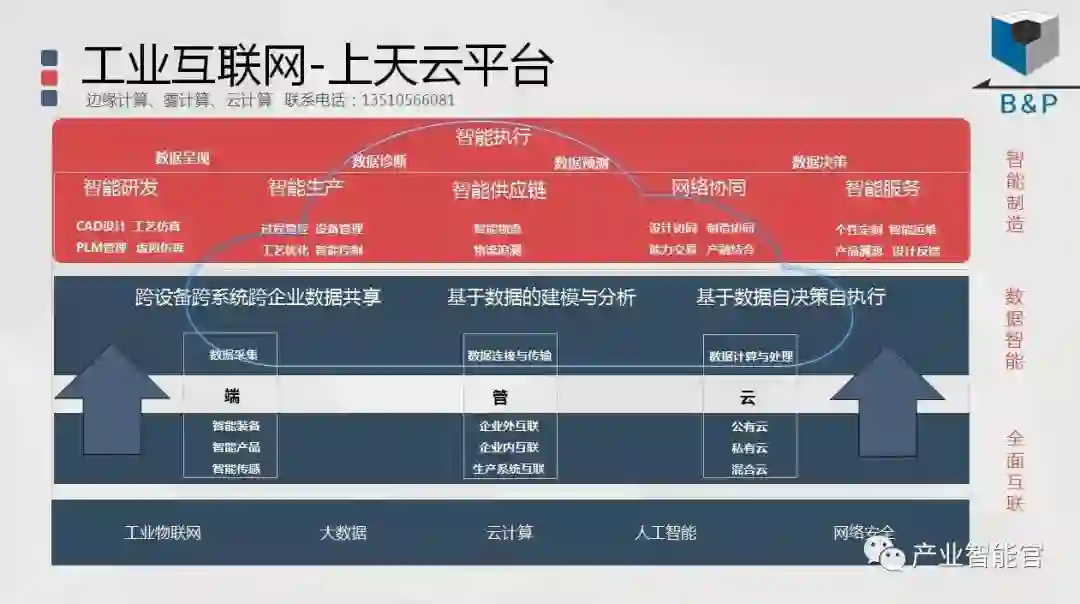
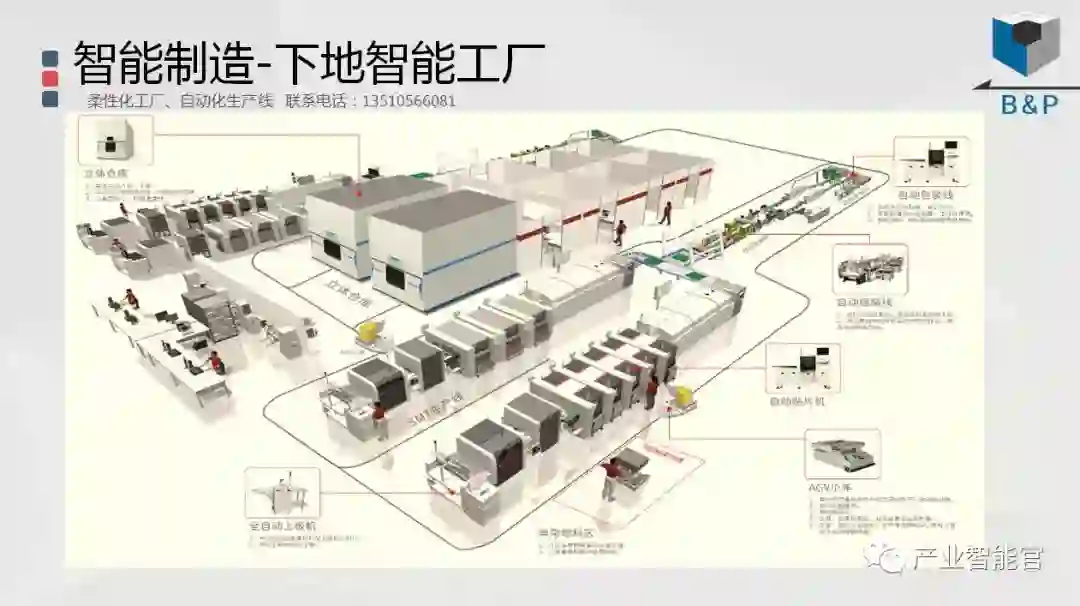
工业互联网
产业智能官 AI-CPS
加入知识星球“产业智能研究院”:先进产业OT(工艺+自动化+机器人+新能源+精益)技术和新一代信息IT技术(云计算+大数据+物联网+区块链+人工智能)深度融合,在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的机器智能认知计算系统;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。
版权声明:产业智能官(ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源,涉权烦请联系协商解决,联系、投稿邮箱:erp_vip@hotmail.com。



