吃瓜笔记 | 旷视研究院:被遮挡人脸区域检测的技术细节(PPT+视频)
转自:吃瓜社
12月27日晚,量子位·吃瓜社联合Face++论文解读系列第四期开讲,本期中旷视(Megvii)研究院解读了近期发表的Face Attention Network论文。
本篇论文所提出的Face Attention Network,是基于分层注意力机制的人脸图像区域检测器,能够在不影响速度的情况下显著提高被遮挡的人脸检测问题的召回率。
本期主讲人为旷视研究院研究员袁野,同时也是论文共同一作,wider face legend board第一。主要负责face detection工作。
量子位应读者要求,将精彩内容整理如下:
△ 分享视频回放
这篇论文中主要提出的是如何设计和使用Attention的机制去解决大尺度变化下的遮挡问题。论文通过精心设计的anchor setting和anchor level 的attention机制能够在不影响速度的情况下显著提高被遮挡的人脸的召回率。
Face detection的主要背景
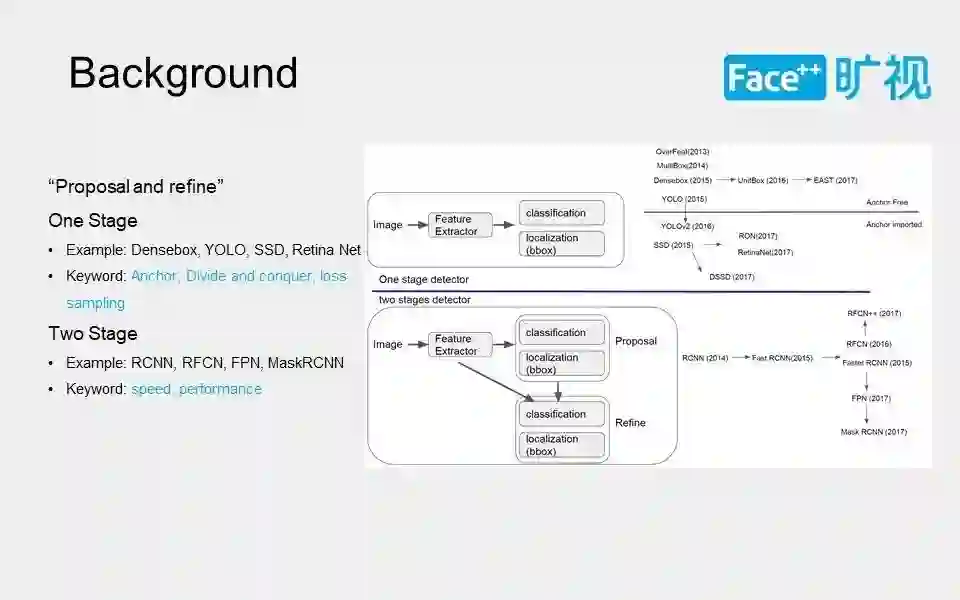
从背景上来看,对于Face的检测,跟General detection一脉相承。从是否需要提取proposal和是否需要对这个proposal进行二次操作的角度来简单划分的话,主要分为One stage detector和Two stage detector。
这两个方法总体来说是各有利弊。One stage detector主要的优势是快速,这个主要是从工程上来说,假如你在手机上从一个256甚至更高维度的1024的 channel上直接crop一个feature出来,是一个相当耗时的工作,所以one stage天然就有很好的速度优势。
但是one stage有也存在不足,它由于没有后面refine的过程,在两个人脸或者是两个物体挨得比较近,或者是难以辨认的情况下,one stage通常会在性能上会有一定的劣势。
Face detection的挑战

首先是scale,由于face自身的特殊性,不论是通用物体或者行人检测,通常情况下,我们只是在意比较近处的物体。scale的变化远远没有人脸这么大。
其次是occlusion,也就是遮挡问题。遮挡问题简单地分为两部分:物体的遮挡;face的自遮挡。识别戴头巾或者口罩的人脸,这是一个典型的物体遮挡的问题。如果两个人挨得特别近,以至于把后面的人挡住了一部分,但是勉强还是可以看到另一部分,这就是face的自遮挡。
原文链接:
https://mp.weixin.qq.com/s/gZWBhMP8Q3Mrc3hNGKvWXg





