【机器视觉】旷视研究院解读COCO2017物体检测夺冠论文
主讲人:彭超 | 旷视研究院研究员
屈鑫 整理编辑
量子位·吃瓜社 出品 | 公众号 AI7gua
12月6日晚,量子位·吃瓜社联合Face++论文解读系列第一期开讲,本期中旷视(Megvii)研究院解读了近期发表的物体检测论文:《MegDet:A Large Mini-Batch Object Detector》,基于此篇论文提出的MegDet模型,Face++摘下COCO 2017 Detection冠军。
本期主讲人为旷视研究院研究员彭超,同时也是MegDet论文第一作者、COCO 2017 Detection竞赛主力队员,在比赛中主要负责物体检测模型的撰写、训练和调优工作,拥有丰富的深度学习模型调优经验。
此次分享大家反应热烈,全程干货满满,量子位应读者要求,将主要内容整理如下:
△ 论文解读完整回放视频
今天我们主要讲的内容主要集中在Detection和Instance Segmentation上,关于COCO Keypoint比赛相关论文,会在12月13日的晚上7点半由竞赛队的owner王志成,给大家进行一个充分的讲解。
MegDet

在COCO Detection比赛中,我们优先解决的是Batchsize的问题;回顾ImageNet Classification的工作,他们的Batchsize在训练过程中非常大,从起步开始就已经是128,最新的一些研究甚至达到了8000或者32K的水平,这使得人们可以在一个小时、乃至半个小时之内完成ImageNet的训练。
但在COCO Detection任务中,我们发现人们使用的BatchSize非常小。最开始的只有2,相当于是两张卡,一张卡一张图;到后面的一些版本,BatchSize也仅有8,就是8张卡训练,一张图一张卡;最新一些研究的结果会达到16,这个结果跟Classification任务相比,连零头都不到。
这个时候,我们就有了一个疑问:为什么在物体检测中Batchsize会这么小呢?要回答这个问题,我们需要了解物体检测和图像识别的不同之处。对于图像识别而言,算法只需要判断一张图中的主要物体,而主要物体所占像素比例通常较大,因此一张224x224的小图即可满足需求。 但是在物体检测里,人们往往需要检测一些精细的小物体,这些物体所占像素比例非常小,常常不足1%。而现有的神经网络技术一般会逐步缩小特征图的尺寸,为了保证小物体在最后的特征图上占有一定的比例,算法需要一张较大的输入图片,通常的做法是800x800。

由于输入图片尺寸的增长,图像检测所需显存量也会同比例增长,这也使得已有的深度学习框架无法训练大Batch-Size的图像检测模型。而小Batch-Size的物体检测算法又常常会引入如下四个问题:

不稳定的梯度。由于Batch-Size较小,每次迭代生成的梯度的变化会非常大,这会导致SGD算法在一个区域内来回震荡,不易收敛到局部最优值。
BN层统计不准确。由于Batch-Size较小,难以满足BN层的统计需求,人们常常在训练过程中固定住BN层的参数,这意味着BN层还保持着ImageNet数据集中的设置,但其余参数却是COCO这个数据集的拟合结果。这种模型内部的参数不匹配会影响最后的检测结果。
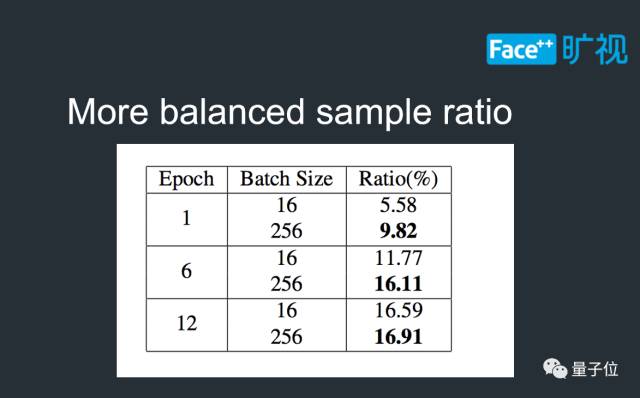
正负样本比例失调。由于Batch-Size较小,一个minibatch之中的图片变化可能非常大,很可能某些阶段正样本框只有个位数。当Batch-Size增大的时候,由于一个minibatch内部的图片数量增加,正负样本比例会优于小Batch-Size的情况。
超长的训练时间。这个原因非常好理解:当Batch-Size较小时,我们必须迭代更多的次数来让算法收敛;随着Batch-Size的增加,算法每次迭代见过的图片数量也随之增长,相应的迭代次数就可以下降,人们也能更快地得到结果。
基于上述四点分析,我们应该对Batch-Size这一问题有了一个直观的认识。我们在比赛中,为了解决这个问题,特意研发了一整套多机训练系统,以实现我们大Batch-Size物体检测算法:MegDet。因为有良好的内部支持,我们的MegDet算法可以几乎无开销完成算量,产生几乎线性的加速比和更优的检测结果。下面,我将介绍MegDet实现过程中的四个要点。
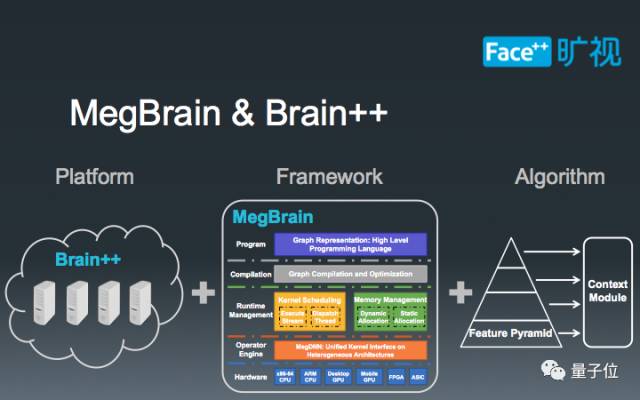
要实现MegDet,首先需要大量的底层支持,大致上可以分为三类:第一是一套GPU 计算云平台,这在我们内部被称为Brain++平台,专门负责统筹规划硬件资源的使用;第二是基于Brain++平台的MegBrain软件框架,提供了诸多深度学习必备的工具箱。第三是在前面两者之上建立的物体检测算法,在此我们基于FPN框架设计了一套检测算法。
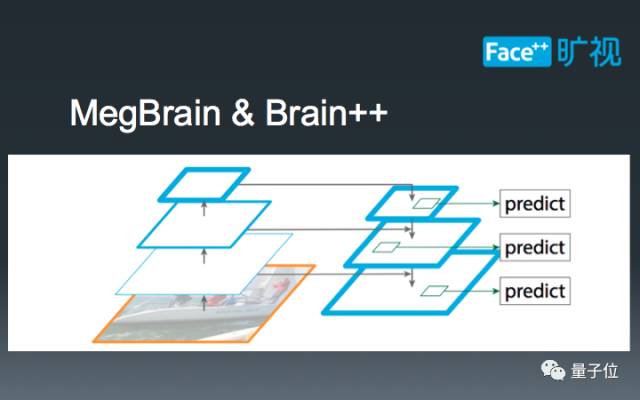
这里,我们简单科普一下FPN检测框架。和传统的Faster-RCNN框架不同,FPN在不同尺寸的特征图上提取RoI,以此达到分而治之的效果,即:大物体在小特征图上检测,小物体在大特征图上检测。这种设计既能充分利用现有卷积神经网络的锥形结构,又能有效解决COCO数据集中普遍存在的小物体问题,一举两得。
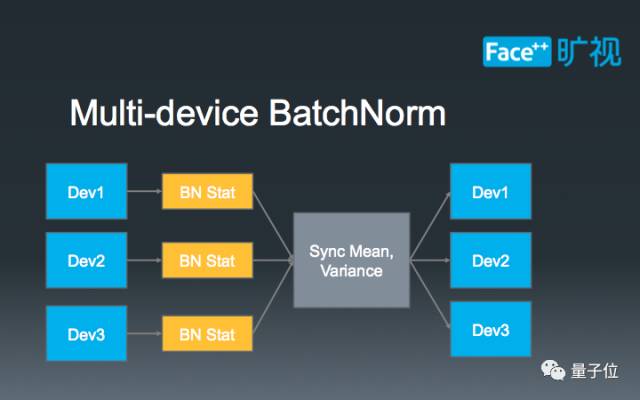
解决了BN统计不准确的问题。简单来讲,已有的BN统计方法局限于统计单张卡上的图片,做不到多张卡联合统计。由于物体检测本身的特性,单张卡上的图片数量达不到BN统计的要求,因此只能通过多卡联合统计来训练得到结果。为此,我们利用了NCCL(NVIDIA Collective Communications Library)代码库,实现了多卡BN。具体的算法流程可以参照上图,首先通过单卡自主统计BN的参数,再将参数发送到单张卡上进行合并,最后再把BN的结果同步到其他卡上,以进行下一步的训练。
Sublinear Memory技术。这项技术的目的在于减少深度卷积神经网络的显存消耗量,保证我们在比赛之中可以尽可能地使用大模型。我们可以通过上图来简单地体会这项技术的作用。在现有训练方法中,为了计算Conv2中参数(W2, b2)的梯度,人们一般需要保存Conv2的输出结果;但实际上,Conv2的输出结果可以根据Conv1的结果来动态计算,这样Conv2的输出结果就不需要保存,显存消耗也能进一步下降;特别是一些非常深的神经网络,例如152层的模型,Sublinear Memory能显著降低显存的使用量,帮助我们尝试更多的技巧。
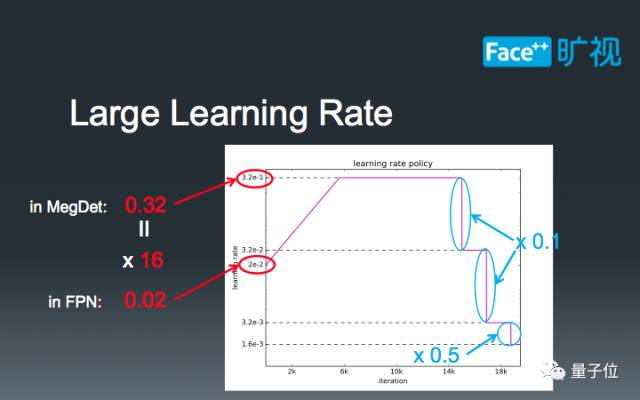
介绍一些在大Batch-Size下的学习率调参技巧。16-batch的FPN标准学习率是0.02, 而我们的MegDet的Batch-Size是256。在这种情况下,我们如果直接设定学习率为0.32=0.02 x 16,会导致模型早期迅速发散,无法完成训练。因此,我们需要有一个“逐步预热”的过程,让模型逐渐适应较大的学习率。当训练到一定阶段的时候,我们设定了三个下降阶段:在前两个阶段,我们直接将学习率除以10,最后再将学习率减半。这种学习率的设计主要是为了在比赛中取得极致性能,也是我们的经验所得。


至此,我们可以比较一下不同年份,物体检测的Batch-Size规模。最初,2015年,人们使用2-batch来训练物体检测算法;过了一年之后,这个数字增长到了8倍,即16-batch;今年,在我们Megvii研究院的推动下,又增长到了256-batch,是原始Faster-RCNN的128倍,FPN的16倍。这个数字也恰好是ImageNet常见的Batch-Size。
在MegDet的帮助之下,我们取得了COCO Detection Challenge 2017的冠军,同时也部分解决了之前提到的小Batch-Size训练的问题。
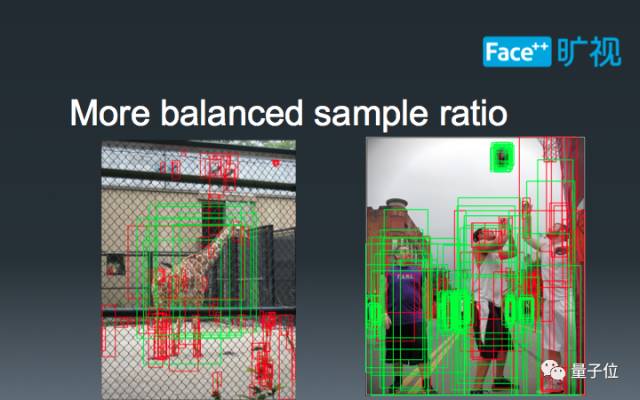
首先,根据我们的统计,在训练过程之中,正负样本比例比小Batch-Size更优,这也意味着梯度的计算能更好地拟合数据分布。下图展示了两张正样本比例相差较大的结果,由于大Batch-Size能够同时计算这两种极端情况的梯度,使得模型参数更新更加平稳。

其次,我们通过多机BN的实现,实现了大Batch-Size下物体检测算法的性能提升。在已有的ImageNet Classification任务中,人们研究大Batch-Size的目的是为了防止掉点;然而在物体检测任务之中,我们却惊奇地发现,大Batch-Size可以直接带来性能提升,这和已有的经验并不相符。另一方面,通过上图的逐Epoch精度曲线,我们还发现256-batch和16-batch在同等Epoch下的精度并不能重合,甚至还有较大的间隔,这也和ImageNet Classification已有的研究结果相违背。一个潜在的因素是物体检测的多loss计算扰乱了中间结果的检测精度,但详细研究这个现象还需要跟多的实验,这已经超出了本文的范畴。
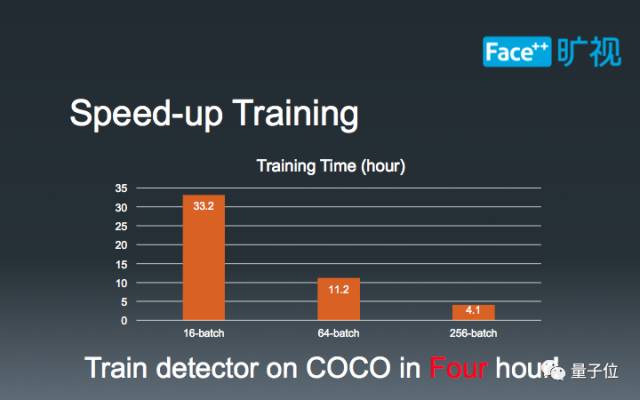
第三点,也是我们做MegDet算法的初衷,即加快训练速度。如图所示,基于ResNet-50网络,在16-batch的设置下, 训练一个模型需要33个小时;当我们增加Batch-Size到64的时候,11个小时就足够完成训练;最后,在256-batch的设定下,仅需要4个小时就可以顺利完成训练。这使得我们在相同的计算力下,可以深度优先地搜索吗模型参数,而非广度优先地并行搜索模型参数,大大降低了试错时间。
COCO的比赛过程

总结一些物体检测的比赛结果。
和论文中不同,我们使用了一个较好的基础网络,让我们一开始的Baseline就达到了43.0 mmAP。然后,我们利用了MegDet中提到的所有技巧,模型的结果为45.0 mmAP。紧接着,我们加入了Semantic Semgnetation的监督loss,以及下文将要提到的Context Module,检测结果涨到了47.0 mmAP。此时,我们再加入了Multi-Scale训练和测试的技巧,达到了50.5 mmAP。这个结果是我们最好的单模型结果。最后,我们ensemble了四个基于不同基础网络训练的模型,虽然其余三个模型的结果都比50.5要差,但多个模型融合能够有效补充不同模型之间的不足,最后我们的点数是52.8 mmAP。

这是我们使用47.0 mmAP的模型出的检测结果图。虽然比我们最终比赛提交的52.8的模型要弱,但在这种中等难度的场景下,已经能够很有效地检测出拥挤的物体和较远处的小物体。这也意味着,在不考虑计算量的情况下,现有的算法已经能够很好地检测出常见物体,达到了实用需求。
Instance Segmentation

介绍一下Instance Segmentation上的经验。
Instance Segmentation现有的实现流程大致如下:首先用一个Detection的模型,比如我们之前的MegDet,给出一个待选框;通过这个框在特征图上扣取一块区域,并做一些Context处理;最后,通过一个精心设计的Mask来计算最后的loss。Instance Segmentation最重要的就是如图所示的三个模块,这也是我们本次比赛着力探索的部分。
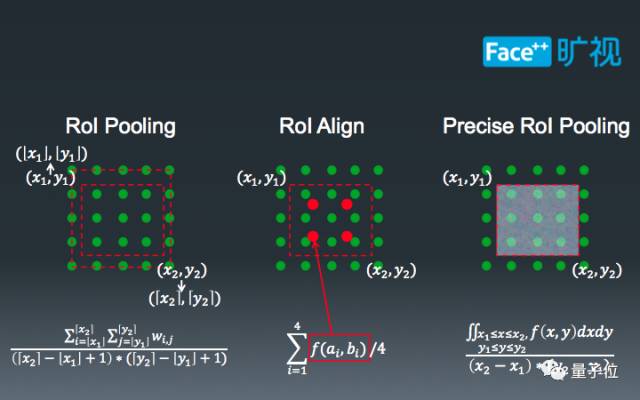
第一个部分是Pooling,也就是扣取特征图的过程。最原始的RoIPooling比较暴力。如左图所示,中间较小的红色虚线框是MegDet给出的ROI,由于浮点数的影响,这个框并不能完全对齐到绿色的特征图格点上。现有的计算逻辑是把红色的虚线框拉伸到外围红色虚线框,然后计算框中部分特征格点。最近,Mask-RCNN的提出将这个“硬”过程软化成了插值流程,即计算格点附近四个点的平均结果。而我们提出的Precise RoI Pooling讲这个过程做了进一步细化,即利用一个积分的过程代替插值过程,使得我们可以更好地扣取ROI对应的特征图。

第二部分,是Context抽取部分,我们在COCO比赛中也使用了这个技巧来改善Detection的结果。如图所示,在第x层,我们扣去了一个14x14的ROI,同时我们在更小的特征图x+1上也扣取了相同尺寸的ROI,并通过两者的和作为一个初始ROI。在更大的特征图x-1上,我们扣取了更大的28x28区域,作为额外的Context,辅助分割。值得一提的是,我们在每个特征图上都增加了右上角所示的large kernel模块,这个模块已被证明在Semantic Segmentation中拥有非常好的效果,在Instance Segmentation中它也同样有效。
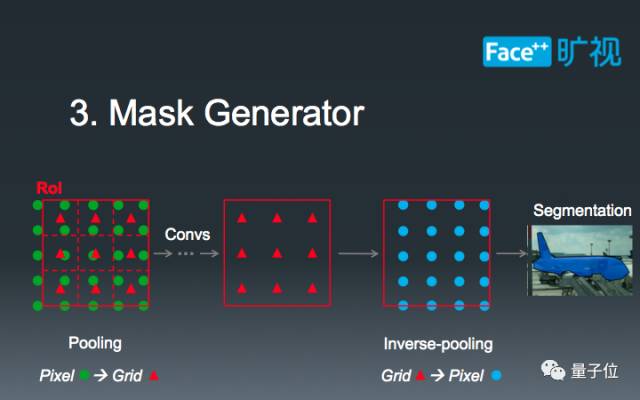
第三部分,也是最后一部分,我们精心设计了Mask的生成。在第二部扣取整合了Context之后,实际的ROI对应的GroundTruth已经发生了一定的坐标偏移,如图中红色小三角所示。在这种偏移下,我们不能直接用绿色格点对应的GroundTruth来计算loss(即蓝色格点)。此时,我们的做法是把ROI Feature重新插值到蓝色格点处,以此来精确计算Instance Segmentation的Loss。
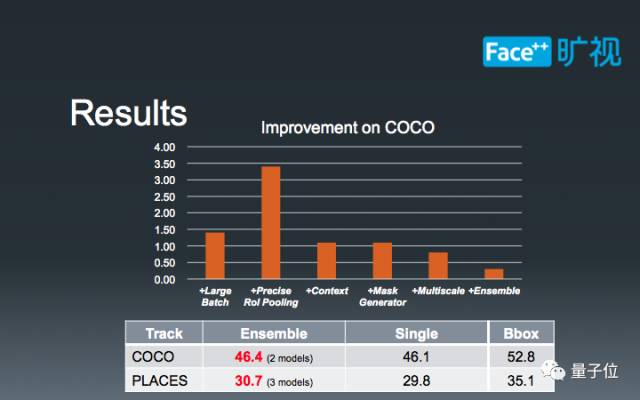
通过实践上述三种技巧,外加一些在COCO Detection中使用的技巧,我们取得了COCO Instance Segmentation第二,PLACES Instance Segmnetation第一的成绩。
图中的柱状图展示了我们在相同基础下,增加不同模块导致的模型精度增加。可以发现,诸如Large Batch、MultiScale、Context和Ensemble的技巧是通用的,而另外两种方法则是Instance Segmnetation独享的。值得一提的是,我们在COCO Instance Segmentation中和第一名相差只有0.3,由于时间和资源的限制,我们只做了ensemble两个模型。如果可以ensemble四个模型,那么我们很有希望取得更优的结果。

这张图片展示了我们比赛中的单模型结果。可以发现,针对分割中较为困难的细长杆状物体,我们已经能够做得比较好,基本满足了实用需求。但同Detection任务相比,Instance Segmentation还有较多的发展空间。
最后,我们总结一下这次比赛带来的经验。

第一,我们实现了世界上第一个大Batch detctor:MegDet。在一些列任务中,我们发现MegDet是有效的训练技巧。第二,在做Segmentation任务重,像素点的对齐操作是一个巨大的难点,无论是扣取ROI Feature还是计算loss。最后,训练速度非常重要,这也是我们公开MegDet方法的原因。一旦实现了MegDet,物体检测及其相关领域的发展会变得非常迅速,更好的算法可以被提出和验证。
一则招人硬广:
希望加入旷视科技一起登上CV巅峰的同学可以投简历至yugang@megvii.com,长期招聘算法实习生。实习优秀者,更有跳过面试阶段,入职Megvii研究院的机会。
Q&A
处理误检有什么好办法吗?
如果是处理两类的物检问题,你实际上可以在后端再接一个比较小的分类器,来把误检的框给去掉。但就我们的经验来说,如果是做一个多类物体检测算法,特别是像COCO比赛这类的物体检测器,你很难有一个较好的小分类器。最好的方法还是提升模型的性质,比如说我们会在Rol pooling出来之后,我们会加比较多的一些计算量上去,以及加一些训练的技巧,动态地让模型自身去把误检的问题给弄掉。
Batch size大,GPU也多,时间肯定减少,这怎么能证明是算法带来的收益呢?
实际上我们没有说这个是算法带来的收益,我们说的是Batch size大,带来的不光是实验的减少,而且还是性能的一个提升。这个是算法本身带来的一个收益,相当于也是这个算法,可能它本身就需要再一个比较大的Batch size下,才能工作的比较好。
针对小物体有什么好的解决方法?
实践上针对小物体好的解决方法不多,小问题的解决方法不多的原因在于:1) 小物体的图已经比较糊了,人们自己也很难分清。第二个是小物体经常会出现一种像素偏移的情况,特别是在做Pooling的时候。大物体偏离两个像素,基本没有影响,但小物体偏移两个像素可能已经飞出了框外。现有的解决逻辑是用比较浅层的特征图去定向检测小物体,例如FPN。另外一种方法是强行增大图片尺寸,使小物体的像素点尽可能的多。在比赛中,我们两种方法都有用,并且都验证涨点。
人脸识别中,什么策略是有意义的研究路线?
就我个人来说,我认为只要能在限制性条件下涨点的策略都是有意义的研究路线,但如何来实现限制性条件下能涨点,就得具体看你们就做这个模型的一个需求。因为如果是打比赛的话,那当然是什么涨点什么有用;但在做手机端模型的时候,某些消耗巨大的方法可能就并不适用。具体如何研究,如何取舍,还需要和业务场景相结合。
SGD外其他方法试过吗?
我们试过一些其他方法,但是我们发现好像都和SGD差不多。在多机训练场景下,SGD会更加方便实现。

人工智能赛博物理操作系统
AI-CPS OS
“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能)分支用来的今天,企业领导者必须了解如何将“技术”全面渗入整个公司、产品等“商业”场景中,利用AI-CPS OS形成数字化+智能化力量,实现行业的重新布局、企业的重新构建和自我的焕然新生。
AI-CPS OS的真正价值并不来自构成技术或功能,而是要以一种传递独特竞争优势的方式将自动化+信息化、智造+产品+服务和数据+分析一体化,这种整合方式能够释放新的业务和运营模式。如果不能实现跨功能的更大规模融合,没有颠覆现状的意愿,这些将不可能实现。
领导者无法依靠某种单一战略方法来应对多维度的数字化变革。面对新一代技术+商业操作系统AI-CPS OS颠覆性的数字化+智能化力量,领导者必须在行业、企业与个人这三个层面都保持领先地位:
重新行业布局:你的世界观要怎样改变才算足够?你必须对行业典范进行怎样的反思?
重新构建企业:你的企业需要做出什么样的变化?你准备如何重新定义你的公司?
重新打造自己:你需要成为怎样的人?要重塑自己并在数字化+智能化时代保有领先地位,你必须如何去做?
AI-CPS OS是数字化智能化创新平台,设计思路是将大数据、物联网、区块链和人工智能等无缝整合在云端,可以帮助企业将创新成果融入自身业务体系,实现各个前沿技术在云端的优势协同。AI-CPS OS形成的数字化+智能化力量与行业、企业及个人三个层面的交叉,形成了领导力模式,使数字化融入到领导者所在企业与领导方式的核心位置:
精细:这种力量能够使人在更加真实、细致的层面观察与感知现实世界和数字化世界正在发生的一切,进而理解和更加精细地进行产品个性化控制、微观业务场景事件和结果控制。
智能:模型随着时间(数据)的变化而变化,整个系统就具备了智能(自学习)的能力。
高效:企业需要建立实时或者准实时的数据采集传输、模型预测和响应决策能力,这样智能就从批量性、阶段性的行为变成一个可以实时触达的行为。
不确定性:数字化变更颠覆和改变了领导者曾经仰仗的思维方式、结构和实践经验,其结果就是形成了复合不确定性这种颠覆性力量。主要的不确定性蕴含于三个领域:技术、文化、制度。
边界模糊:数字世界与现实世界的不断融合成CPS不仅让人们所知行业的核心产品、经济学定理和可能性都产生了变化,还模糊了不同行业间的界限。这种效应正在向生态系统、企业、客户、产品快速蔓延。
AI-CPS OS形成的数字化+智能化力量通过三个方式激发经济增长:
创造虚拟劳动力,承担需要适应性和敏捷性的复杂任务,即“智能自动化”,以区别于传统的自动化解决方案;
对现有劳动力和实物资产进行有利的补充和提升,提高资本效率;
人工智能的普及,将推动多行业的相关创新,开辟崭新的经济增长空间。
给决策制定者和商业领袖的建议:
超越自动化,开启新创新模式:利用具有自主学习和自我控制能力的动态机器智能,为企业创造新商机;
迎接新一代信息技术,迎接人工智能:无缝整合人类智慧与机器智能,重新
评估未来的知识和技能类型;
制定道德规范:切实为人工智能生态系统制定道德准则,并在智能机器的开
发过程中确定更加明晰的标准和最佳实践;
重视再分配效应:对人工智能可能带来的冲击做好准备,制定战略帮助面临
较高失业风险的人群;
开发数字化+智能化企业所需新能力:员工团队需要积极掌握判断、沟通及想象力和创造力等人类所特有的重要能力。对于中国企业来说,创造兼具包容性和多样性的文化也非常重要。
子曰:“君子和而不同,小人同而不和。” 《论语·子路》云计算、大数据、物联网、区块链和 人工智能,像君子一般融合,一起体现科技就是生产力。
如果说上一次哥伦布地理大发现,拓展的是人类的物理空间。那么这一次地理大发现,拓展的就是人们的数字空间。在数学空间,建立新的商业文明,从而发现新的创富模式,为人类社会带来新的财富空间。云计算,大数据、物联网和区块链,是进入这个数字空间的船,而人工智能就是那船上的帆,哥伦布之帆!
新一代技术+商业的人工智能赛博物理操作系统AI-CPS OS作为新一轮产业变革的核心驱动力,将进一步释放历次科技革命和产业变革积蓄的巨大能量,并创造新的强大引擎。重构生产、分配、交换、消费等经济活动各环节,形成从宏观到微观各领域的智能化新需求,催生新技术、新产品、新产业、新业态、新模式。引发经济结构重大变革,深刻改变人类生产生活方式和思维模式,实现社会生产力的整体跃升。
产业智能官 AI-CPS
用“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能),在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的认知计算和机器智能;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。


长按上方二维码关注微信公众号: AI-CPS,更多信息回复:
新技术:“云计算”、“大数据”、“物联网”、“区块链”、“人工智能”;新产业:“智能制造”、“智能农业”、“智能金融”、“智能零售”、“智能城市”、“智能驾驶”;新模式:“财富空间”、“数据科学家”、“赛博物理”、“供应链金融”。
官方网站:AI-CPS.NET
本文系“产业智能官”(公众号ID:AI-CPS)收集整理,转载请注明出处!
版权声明:由产业智能官(公众号ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源。部分文章推送时未能与原作者取得联系。若涉及版权问题,烦请原作者联系我们,与您共同协商解决。联系、投稿邮箱:erp_vip@hotmail.com



