天池智慧交通比赛总结
(点击上方公众号,快速关注一起学AI)
|| 前言
抽空参加了一下阿里天池的智慧交通预测挑战赛,惭愧最后成绩并不是太好(勉勉强强1%左右),但自己确实是尽力了,还是打算写个小小的总结,来回顾一下漫长的比赛历程(7月20号开始),也反思一下可以提升的地方,大神们见笑。
此次比赛以“移动互联时代的智慧交通预测”为主题,要求参赛者基于互联网交通信息建立算法模型,精准预测各关键路段在某个时段的车辆平均通行时间。

提供的数据包括以下几个部分:
· 路段(link)属性表
每条道路的每个通行方向由多条路段(link)构成,数据集中会提供每条link的唯一标识,长度,宽度,以及道路类型,如表1所示;图1示例了地面道路link1和link2的属性信息。
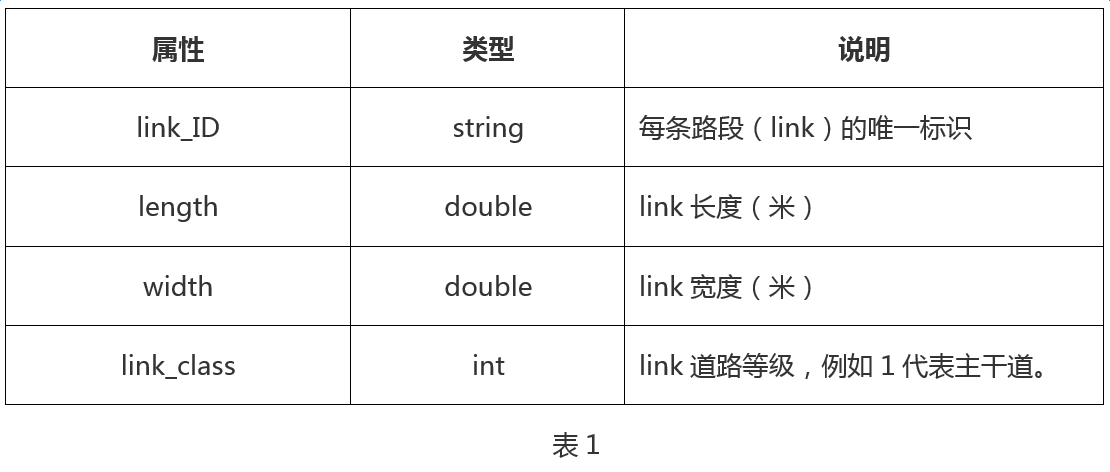

· link上下游关系表
link之间按照车辆允许通行的方向存在上下游关系,数据集中提供每条link的直接上游link和直接下游link,如表2所示;图2示例了link2的in_links和out_links。

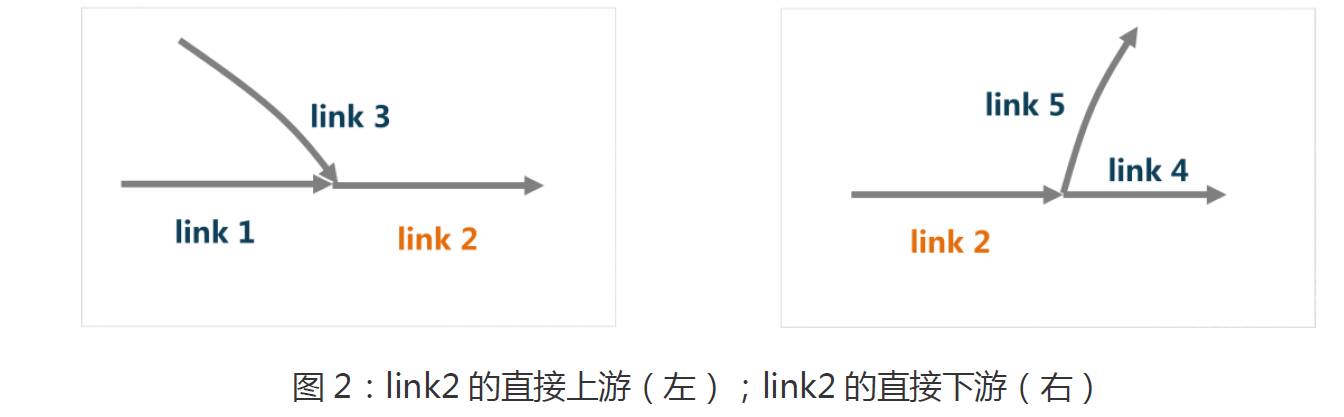
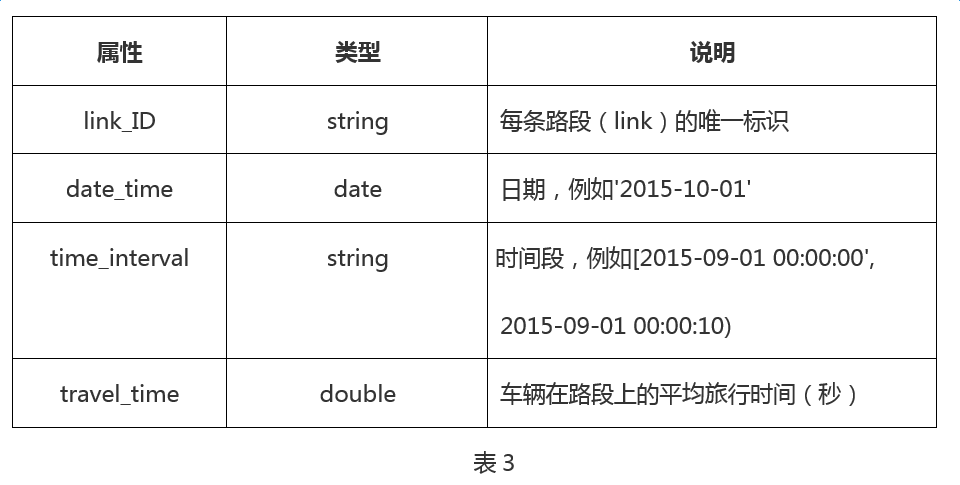
· link历史通行时间表
数据集中记录了历史每天不同时间段内(2min为一个时间段)每条link上的平均旅行时间,每个时间段的平均旅行时间是基于在该时间段内进入link的车辆在该link上的旅行时间产出。字段解释如表3所示:
这是一个回归类问题,预测的y是通行时间,X是自己需要构造的特征,需要大家展开脑洞,想想有什么因素会引起堵车。可以快速做一些基础特征,用xgboost跑一版,出一个baseline的版本,再做后期的优化,比如以下是一些快速脑洞出来的特征(注意,通过观察所给数据,可以发现数据里可以产出2大类特征——一类是历史同时间片的统计特征,另外一类是上一个时间片的特征):
2.1 时间维度
· 时间段
· 星期几
· 是否节假日
· 所属拥堵时段等级(历史时间上统计得到)
2.2 道路属性维度
(拥堵程度,可以用 长度/通行时间 确定)
· 道路宽度
· 道路长度
· 汇入道路条数
· 汇入道路宽度之和
· 汇入的最拥堵道路的宽度
· 汇入道路平均长度
· 出口道路条数
· 出口道路总宽度
· 出口最拥堵的道路宽度
2.3 历史统计数据维度
· 同周几 同时段 同节假日 平均时长
· 上一天同时段时长
· 前三天的平均时长
· 趋势数据(通行时长变化)
· 之前时间段(前15分钟)本道路的平均时长
· 之前时间段(前15分钟)汇入道路的状况
· 之前时间段(前15分钟)汇入的最拥堵的道路状况
· 之前时间段(前15分钟)历史平均最拥堵道路(当前时间段平均)状况
· …
通过所有数据上简单的特征构造和xgboost建模,最终排名可以勉强进入80,显然还是有很多细化的工作可以做的。在所有数据驱动的方法里,有一句广为流传的话“数据决定了最后效果的上限,模型只是在想办法逼近这个上限”,我在数据层面做一些了些工作。
3.1 缺失值处理
看过数据的同学会发现,数据本身并不完整,有很多时间片的数据是缺失的(如果大家仔细分析,你会发现有2条link在2017年的5月和6月整个2个月都是无数据的,这显然会带来很严重的问题,当然,对于这样的link,我们也可以考虑单独拎出来处理,比如通过它的上下游同时间片的数据去做一个补全或者直接预估),我们需要对部分关键的缺失时间片做填充。
这里的填充是在原始数据上进行的填充,我们有时候的处理方式,也可以是在做完特征以后,对部分特征进行填充。
大家都知道数据填充有几种常用的方式:
1)同一列的均值或者中位数填充
2)在时序问题中,相邻的时间点数据填充
3)利用其他列进行建模预测填充该列数据(比如电商里根据用户的行为,可能可以预测缺失的用户年龄)
我这里采用的是1和2两种方式,对于临近时间片有数据的样本,通过临近的数据进行填充,对于连续缺失的情况(比如30分钟,即15个时间片都没有数据),通过同星期几同时间片的均值进行填充。
3.2 异常值处理
异常值处理同样是一个非常重要的环节,噪声数据的存在,会直接对模型产生巨大的影响,使得预测结果有较大偏差。
考虑到我们手头的数据同样可能有很多噪声数据,我们来做一个异常值处理,有一些异常值检测的算法,但是这里简单起见,我们来思考一下,哪些情况可能是异常值。
首先,道路都可能出现路况意外(比如哪位女司机把整条道路整垮了,比如道路出现了问题,红绿灯出现了问题),总之总体想来,就是当通行时间相对于平均水平非常大或者非常小,我们就要采取一些措施了。最常用的方法是借助于箱线图(boxplot)进行上界和下界的确定,我们这里可以利用pandas直接计算同时间片的通行时间上界和下界,对于超过上界或者低于下界的数据,可以①使用均值或者上下界填充②直接drop掉。
还有一些需要考虑的因素,比如连续的长假(比如五一劳动节十一国庆节),假前的半天和放假最后一天,高速路通常是拥堵的,但是这不应该属于异常状况,我们会有一些处理方法,比如打一个时间标签(产出一列01的特征),用于标注是否是长假的这几个敏感时间段;比如在我们这个比赛的复赛里,你会发现我们只需要预测7月份的3个时间段内的时间片通行时间,而7月份是刚好没有任何长假或者法定节日的,所以可以粗暴地把这些历史数据drop掉,以不影响最后的结果。
下面提到的是比赛中的惯用策略,通常一个模型打天下是不太可靠的,全量的数据分布不一定是符合某个分布的,所以我们对样本做一些小小的区分,对于不同的样本子集分别建模,以达到更精细化预测的效果。下面我们来看用echarts可视化的不同道路的拥堵程度:

以上图中是3条不同的道路,可以看到,不同的道路在工作日和周末的拥堵程度模式可能是不一样的,基于这样的考量,我们可以把道路分成这3种不同的类型,分别建模和预测。当然,你也可以按照道路本身的拥挤程度对道路分组,然后分别建模和预测,我这里采用的是前一种方法。
所有的模型,控制得再好,都有可能会过拟合,而实际上我们建模,就是希望得到有足够泛化能力的模型,能够控制过拟合,在没有见过的测试集数据上有好的效果。最常用的控制过拟合的思路是bagging思路,而在各大比赛中,模型融合也是大神们致胜的法宝。
一般说来,模型类型的差异度越高,融合的效果可能越好,我这里没有使用xgboost和lightGBM这样的2个树形模型融合,而是使用的xgboost和神经网络进行的融合。另外,针对这个比赛而言,神经网络的工具库(我用的是keras)非常棒的一点是,可以直接优化mape,不像xgboost,你可能需要修改loss function去近似mape。但是有一定需要特别注意,xgboost建模的训练数据,可以有一些缺失值,并不影响库的使用;但是对于神经网络而言,这是会有问题的,要先做缺失值数据的补全。
1)和任何数据科学比赛一样,这是数据驱动的解决方案,数据是最重要的,严格意义上说,干净的数据是最重要的,因此首先我们要对数据做一些处理:想办法剔除异常点,分类问题的样本均衡等等;
2)很多时候,特征的重要度比模型要重要,要结合业务场景造出有效的特征;
3)每天提交的次数有限,不能依据leadboard来判断模型的好坏,一定要构建自己的验证集,对于时序问题,要注意切分验证集可不可以用交叉验证。
4)模型融合是会有用的,一般说来模型差异越大(比如树形模型和神经网),模型融合效果会更好。
5)follow一下最新的一些方法,比如神经网络方法,这个部分大家可以参考第一名用的方法;
参赛学员专访:





