【导读】自然场景中的文本识别(scene text recognition, STR)是计算机视觉和模式识别领域的研究热点。最近华南理工的学者发布了关于STR的综述论文,总结了STR的基本问题和最先进的技术,介绍新的见解和想法,并展望未来的趋势来展示STR的全貌。

文字的历史可以追溯到几千年前。文本携带的丰富而精确的语义信息在广泛的基于视觉的应用场景中非常重要。因此,自然场景中的文本识别一直是计算机视觉和模式识别领域的研究热点。近年来,随着深度学习的兴起和发展,许多方法在创新、实用性和效率方面都显示出良好的前景。本文的目的是: (1)总结了与场景文本识别相关的基本问题和研究现状; (2)提出新的见解和想法; (3)对公共资源进行全面调查; (4)指出今后的工作方向。综上所述,本文献综述试图呈现场景文本识别领域的全貌。它为进入这一领域的人们提供了一个全面的参考,并可能有助于启发未来的研究。相关的资源可以在我们的Github资源库中找到:
https://arxiv.org/pdf/2005.03492.pdf
概述
文本是一套符号系统,用来记录、交流或继承文化。作为人类最具影响力的发明之一,文字在人类生活中发挥了重要作用。具体来说,文本所携带的丰富而精确的语义信息在图像搜索[1]、智能检测[2]、工业自动化[3]、机器人导航[4]、即时翻译[5]等广泛的基于视觉的应用场景中非常重要。因此,自然场景中的文本识别受到了研究者和实践者的关注,比如最近出现的“ICDAR鲁棒阅读比赛”[6]、[7]、[8]、[9]、[10]、[11]、[12]。
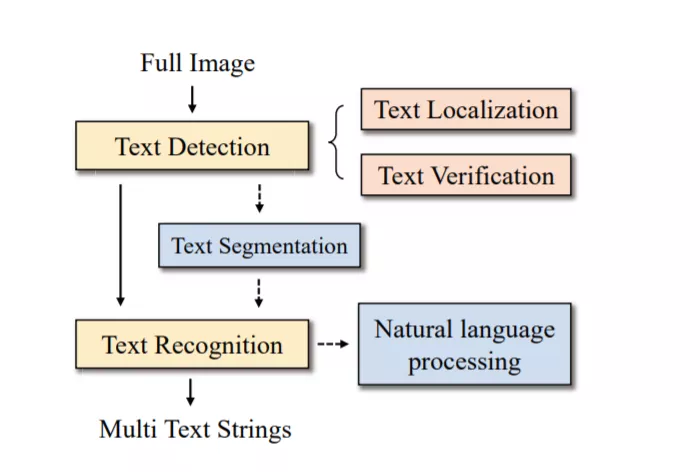
在自然场景中识别文本,也称为场景文本识别(scene text recognition, STR),通常被认为是一种特殊的光学字符识别(OCR)形式,即,camerabased OCR。虽然OCR在扫描文档中已经得到了很好的发展,但由于复杂的背景、不同的字体和不完善的成像条件等诸多因素,它仍然具有挑战性。图1比较了被扫描文档中的STR和OCR的以下特征。
-
背景: 与OCR扫描文档不同的是,自然场景中的文本可以出现在任何东西上(例如,招牌、墙壁或产品包装)。因此,场景文本图像可能包含非常复杂的背景。此外,背景的纹理在视觉上可能与文本相似,这给识别带来了额外的挑战。
-
形式: 扫描文件的文本通常以单一颜色打印,字体规则,大小一致,排列整齐。在自然场景中,文本以多种颜色出现,字体不规则,大小不一,方向各异。文本的多样性使得STR在扫描文档中比OCR更加困难和具有挑战性。
-
噪声: 自然场景中的文本通常会被噪声干扰所扭曲,例如不均匀照明、低分辨率和运动模糊。不完善的成像条件导致STR失效。
-
触达: 扫描文本通常是正面的,占据图像的主要部分。然而,场景文本是随机捕获的,这导致了不规则的变形(如透视变形)。文本的各种形状增加了识别字符和预测文本字符串的难度。
识别自然景物中的文本,由于其重要性和挑战性,近年来引起了学术界和工业界的极大兴趣。
早期研究[15],[16],[17]主要依靠手工制作特征。这些特征的低性能限制了识别性能。随着深度学习的发展,神经网络极大地提高了STR的性能。几个主要因素推动了基于深度学习的STR算法的发展。第一个因素是硬件系统的进步。高性能计算系统[18]可以训练大规模的识别网络。此外,现代移动设备[19]、[20]能够实时运行复杂的算法。第二个是基于深度学习的STR算法中的自动特征学习,这不仅使研究人员从设计和选择手工特征的繁重工作中解放出来,而且显著提高了识别性能。三是对STR应用[21]、[22]、[23]、[24]、[25]的需求不断增长。自然场景中的文本可以提供丰富而准确的信息,有利于理解场景。在大数据时代,自然场景中的文本自动识别在经济上是可行的,这吸引了研究者和实践者。
本文试图全面回顾STR领域,并为算法之间的公平比较建立一个基线。我们通过总结STR的基本问题和最先进的技术,介绍新的见解和想法,并展望未来的趋势来展示STR的全貌。因此,本文旨在为研究人员提供参考,并在今后的工作中有所帮助。此外,我们还提供了对公共资源的全面回顾,包括标准基准数据集和相关代码。
在文献[26],[27],[28],[29],[30],[31]中有一些STR综述。然而,上述[26]、[27]、[28]、[29]、[30]的调查大多已经过时。许多最近的进展,如2018年和2020年开发的算法,都没有包括在这些调查中。我们建议读者阅读这些论文,以获得更全面的历史文献综述。此外,Zhu等人的[29]和Long等人的[31]综述了场景文本检测和识别的方法。Yin等人研究了视频中文本检测、跟踪和识别的算法。与这些调查不同的是,我们的论文主要关注STR,旨在对这一领域提供更详细和全面的概述。