从Boosting到Stacking,概览集成学习的方法与性能
| 全文共3737字,建议阅读时长5分钟 |
转载公众号:机器之心
微信号:almosthuman2014
作者:Vadim Smolyakov
参与:Jane W
集成学习(Ensemble learning)通过组合几种模型来提高机器学习的效果。与单一模型相比,该方法可以提供更好的预测结果。正因为如此,集成方法在许多著名的机器学习比赛(如 Netflix、KDD 2009 和 Kaggle 比赛)中能够取得很好的名次。
集成方法是将几种机器学习技术组合成一个预测模型的元算法,以达到减小方差(bagging)、偏差(boosting)或改进预测(stacking)的效果。
集合方法可分为两类:
序列集成方法,其中参与训练的基础学习器按照顺序生成(例如 AdaBoost)。序列方法的原理是利用基础学习器之间的依赖关系。通过对之前训练中错误标记的样本赋值较高的权重,可以提高整体的预测效果。
并行集成方法,其中参与训练的基础学习器并行生成(例如 Random Forest)。并行方法的原理是利用基础学习器之间的独立性,通过平均可以显著降低错误。
大多数集成方法使用单一基础学习算法来产生同质的基础学习器,即相同类型的学习器,为同质集成。
还有一些使用异构学习器的方法,即不同类型的学习器,为异构集成。为了使集成方法比其中的任何单一算法更准确,基础学习器必须尽可能准确和多样化。
Bagging
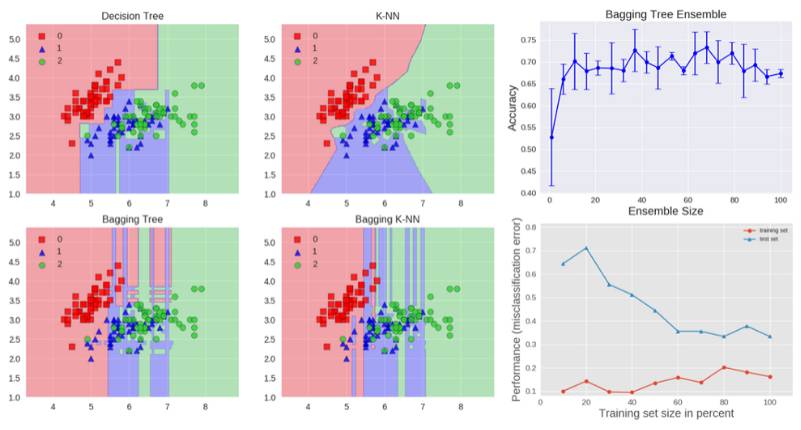
Bagging 是 bootstrap aggregation 的缩写。一种减小估计方差的方法是将多个估计值一起平均。例如,我们可以在不同的数据子集上训练 M 个不同的树(随机选择)并计算集成结果:
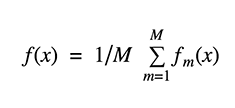
Bagging 使用 bootstrap 抽样来获取训练基础学习器的数据子集。Bagging 使用投票分类和均值回归来聚合得到基础学习者的输出。
我们可以在 Iris 数据集上研究 bagging 方法的分类效果。为了对比预测效果,我们选用两个基准估计器:决策树和 k-NN 分类器。图 1 显示了基准估计器和 bagging 集成算法在 Iris 数据集上的学习决策边界。
准确率:0.63(+/- 0.02)[决策树]
准确率:0.70(+/- 0.02)[K-NN]
准确率:0.64(+/- 0.01)[bagging 树]
准确率:0.59(+/- 0.07)[bagging K-NN]
决策树的决策边界与轴并行,而 K-NN 算法在 k=1 时决策边界与数据点紧密贴合。Bagging 集成了 10 个基础估计器进行训练,其中以 0.8 的概率抽样训练数据和以 0.8 的概率抽样特征。
与 k-NN bagging 集成相比,决策树 bagging 集成实现了更高的准确率。K-NN 对训练样本的扰动较不敏感,因此被称为稳定学习器。
集成稳定学习器不利于提高预测效果,因为集成方法不能有助于提高泛化性能。
最右侧的图还显示了测试集的准确率如何随着集成的大小而提高。根据交叉验证的结果,我们可以看到准确率随着估计器的数量而增加,一直到约 10 个基础估计器时达到最大值,然后保持不变。因此对于 Iris 数据集,添加超过 10 个的基本估计器仅仅增加了计算复杂度而不增加准确率。
我们还可以看到 bagging 树集成的学习曲线。注意训练数据的平均误差为 0.3,测试数据为 U 形误差曲线。训练误差和测试误差之间的最小差距出现在训练集大小的 80%左右的位置。
常用的一类集成算法是随机森林。
在随机森林中,集成中的每棵树都是由从训练集中抽取的样本(即 bootstrap 样本)构建的。另外,与使用所有特征不同,这里随机选择特征子集,从而进一步达到对树的随机化目的。
因此,随机森林产生的偏差略有增加,但是由于对相关性较小的树计算平均值,估计方差减小了,导致模型的整体效果更好。
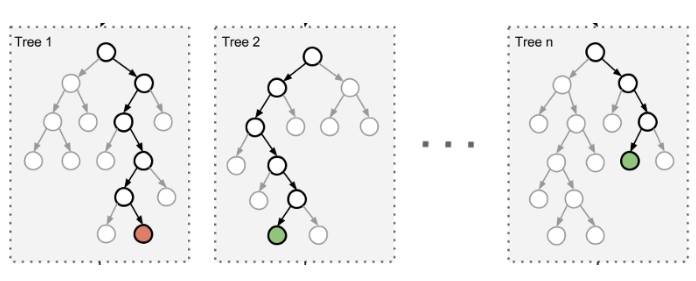
在非常随机化树(extremely randomized trees)算法中,进一步增加随机性:分割阈值是随机的。与寻找最具有区分度的阈值不同,每个备选特征的阈值是随机选择的,这些随机生成的阈值中的最佳值将作为分割规则。这通常能够减少模型的方差,但代价是偏差的略微增加。
Boosting
Boosting 是指能够将弱学习器转化为强学习器的一类算法族。Boosting 的主要原理是适应一系列弱学习器模型,这些模型只是稍微优于随机猜测,比如小决策树——数据加权模型。更多的权重赋值早期训练错误分类的例子。
然后通过结合加权多数投票(分类)或加权求和(回归)以产生最终预测。Boosting 与 bagging 等方法的主要区别是基础学习器通过加权的数据进行顺序训练。
下面的算法阐述了最广泛使用的 boosting 算法形式,称为 AdaBoost,是 adaptive boosting 的缩写。

我们看到第一个基础分类器 y1(x) 使用全部相等的权重进行训练。在随后的 boosting 训练中,增加错误分类的数据点的系数权重,同时减少正确分类的数据点的系数权重。
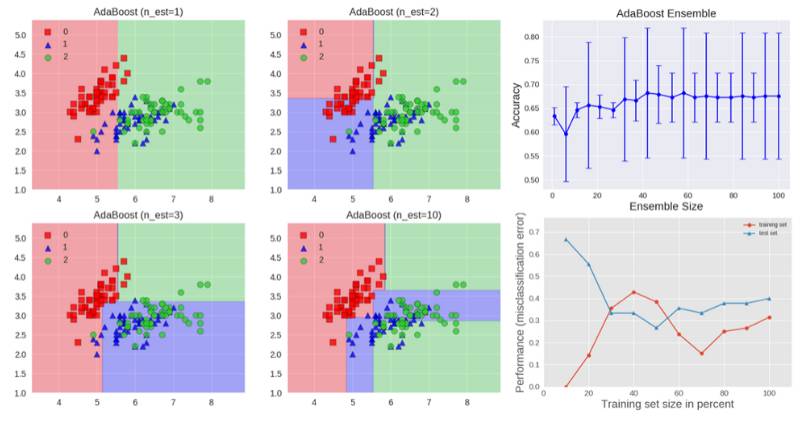
数值 epsilon 表示每个基础分类器的加权误差率。因此,系数权重 alpha 对更准确的分类器赋值更大的权重。
AdaBoost 算法如上图所示。每个基础学习器由深度为 1 的决策树组成,从而基于特征阈值对数据进行分类,该特征阈值将空间分割成由与一个轴平行的线性决策表面分开的两个区域。该图还显示了测试集的准确率随集合大小的增加而改善,同时显示了训练数据和测试数据的学习曲线。
梯度 boosting 树(Gradient Tree Boosting)是 boosting 使用任意可微分损失函数的推广。它可以用于回归和分类问题。梯度 Boosting 以顺序的方式构建模型。
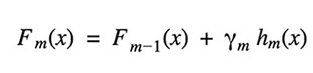
在每一步,给定当前的模型 Fm-1(x),决策树 hm(x) 通过最小化损失函数 L 更新模型:
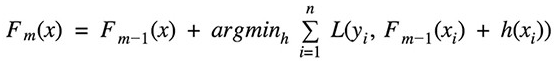
回归和分类算法在使用的损失函数的类型上有所不同。
Stacking
Stacking 是一种集成学习技术,通过元分类器或元回归聚合多个分类或回归模型。基础层次模型(level model)基于完整的训练集进行训练,然后元模型基于基础层次模型的输出进行训练。
基础层次通常由不同的学习算法组成,因此 stacking 集成通常是异构的。下面的算法概括了 stacking 算法的逻辑:

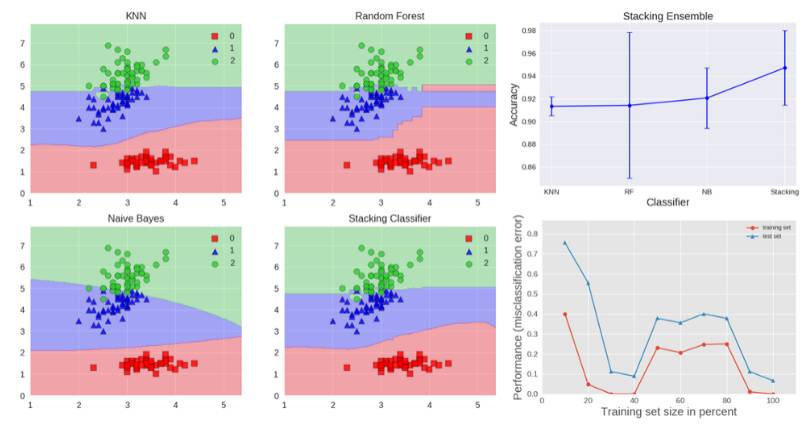
下面是几种算法的准确率,表示在上图右边的图形中:
准确率:0.91(+/- 0.01)[K-NN]
准确率:0.91(+/- 0.06)[随机森林]
准确率:0.92(+/- 0.03)[朴素贝叶斯]
准确率:0.95(+/- 0.03)[Stacking 分类器]
stacking 集成如上图所示。它由 k-NN、随机森林和朴素贝叶斯基础分类器组成,它的预测结果由作为元分类器的 Logistic 回归组合。我们可以看到 stacking 分类器实现的混合决策边界。该图还显示,stacking 能够实现比单个分类器更高的准确率,并且从学习曲线看出,其没有显示过拟合的迹象。
在 Kaggle 数据科学竞赛中,像 stacking 这样的技术常常赢得比赛。例如,赢得奥托(Otto)集团产品分类挑战赛的第一名所使用的技术是集成了 30 多个模型的 stacking,它的输出又作为三个元分类器的特征:XGBoost、神经网络和 Adaboost。有关详细信息,请参阅以下链接:https://www.kaggle.com/c/otto-group-product-classification-challenge/discussion/14335。
代码
生成文中所有图片的代码详见 ipython notebook:
https://github.com/vsmolyakov/experiments_with_python/blob/master/chp01/ensemble_methods.ipynb。
结论
除了本文研究的方法之外,深度学习也常常通过训练多样化和准确的分类器运用集成学习方法。其中,可以通过改变架构、超参数设置和训练技术来实现多样性。
集成学习非常成功,该算法不仅在挑战性的数据集上频频打破性能方面的记录,而且是 Kaggle 数据科学竞赛的获奖者常用的方法之一。
有缘的人终会相聚,慕客君想了想,要是不分享出来,怕我们会擦肩而过~
《【调查问卷】“屏幕时代,视觉面积与学习效率的关系“——你看对了吗?》
本文编辑:慕编组成员(杨佳朋)

